基于 SFT + DPO 两阶段微调的大模型指令遵循优化
用 SFT + DPO 两阶段微调,把大模型的指令遵循能力调上去。基于执行反馈自动合成训练数据、零人工标注,一套种子指令即可适配新领域——带注释代码、技术文档、面试问答全配齐。
项目亮点
- 领域无关: 只需替换种子指令即可适配任何专业领域(法律、金融、医疗等)
- 全自动Pipeline: 从数据生成到训练一键完成,无需人工标注
- 单卡可跑: A800/A100 单卡 80GB 即可运行完整流程
- 20分钟出结果: 不含环境安装,全流程约20分钟
数据与任务
| 样本量 | 执行反馈自动合成 |
|---|---|
| 核心方法 | SFT + DPO 两阶段 |
| 技术栈 | LlamaFactory · vLLM |
如果你想找一个把大模型微调全流程跑通、又能在面试里讲清楚"对齐"的项目,这个「大模型 SFT + DPO 两阶段微调」很合适。
它复刻并实现了一套自动化的指令遵循优化方法,配套也给你备齐了,帮你真正搞懂它、在面试和答辩里讲明白:带中文注释、能读懂的代码,一份从背景讲到每步实现的技术文档,一份把面试问题连答案都写好的问答文档,还有一整套能直接做 PPT 的配图。
先说清楚,它到底在做什么
大模型有时候"不听话"——你让它"用不超过 100 字回答""分三点列出来",它经常做不到。要把这种指令遵循能力调上去,传统做法要么靠人工写大量示范数据(SFT),要么靠人工标注"哪个回答更好"再做强化学习(RLHF),都很贵很慢。
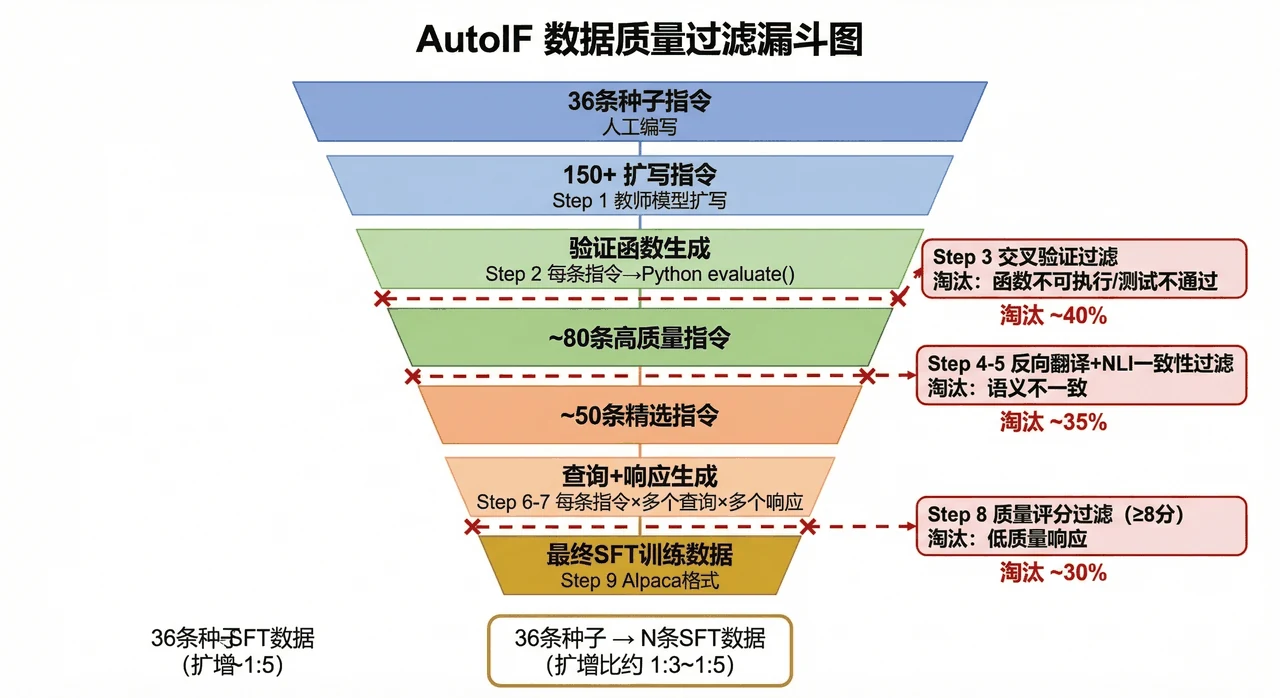
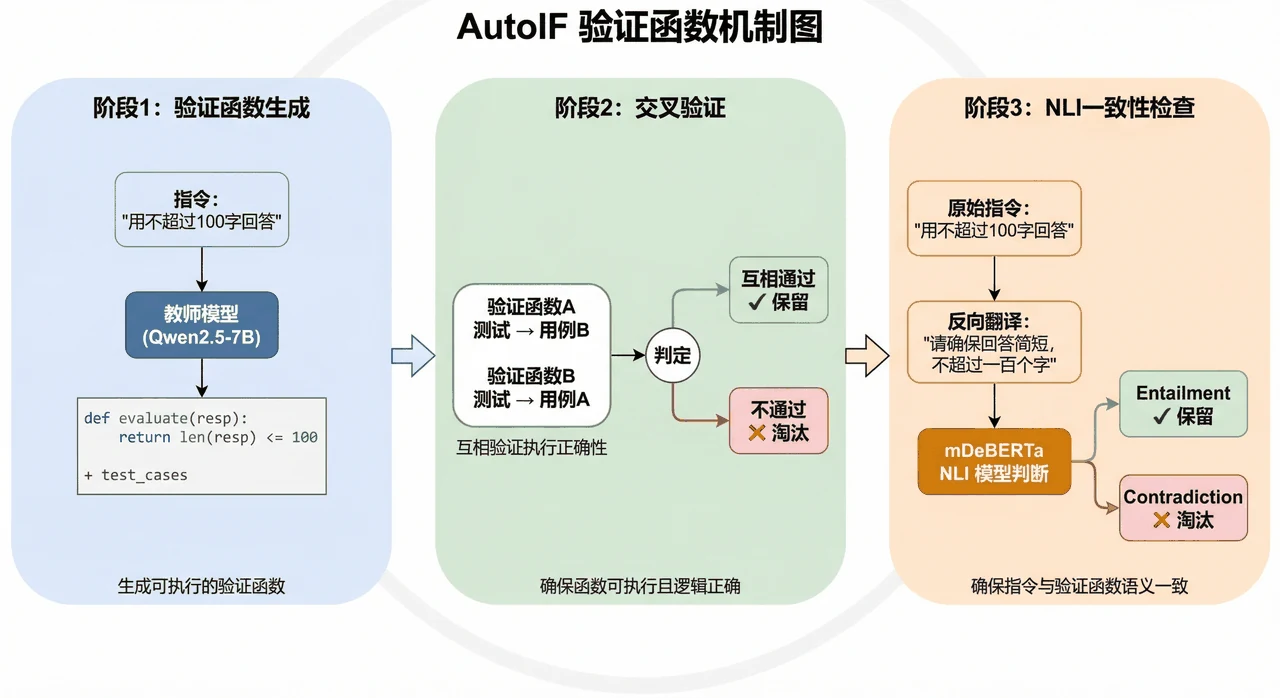
这个项目的思路很巧:用可执行的验证函数代替人工标注。比如"不超过 100 字"这条指令,自动写成一段 Python 代码去数字数——回答能不能过,跑一下就知道。于是整条数据流水线全自动:先合成监督微调(SFT)数据教模型"格式长什么样",再用验证结果自动配出"好 / 差"偏好对,做 DPO 微调教模型"更偏向哪种回答"。两步下来,模型既懂格式、又懂偏好。
搞懂它,你能在面试里讲清楚什么
把下面几件事吃透,面试官顺着问下来你都能接得住。
SFT 和 DPO 各自在做什么、为什么要分两步。 这是地基。你要能讲清楚:SFT 是"模仿",教模型在某类指令下该怎么回答(学格式);DPO 是"择优",在同一条指令下让模型更偏向通过验证的那个回答(学偏好)。两者分工明确,缺一不可。
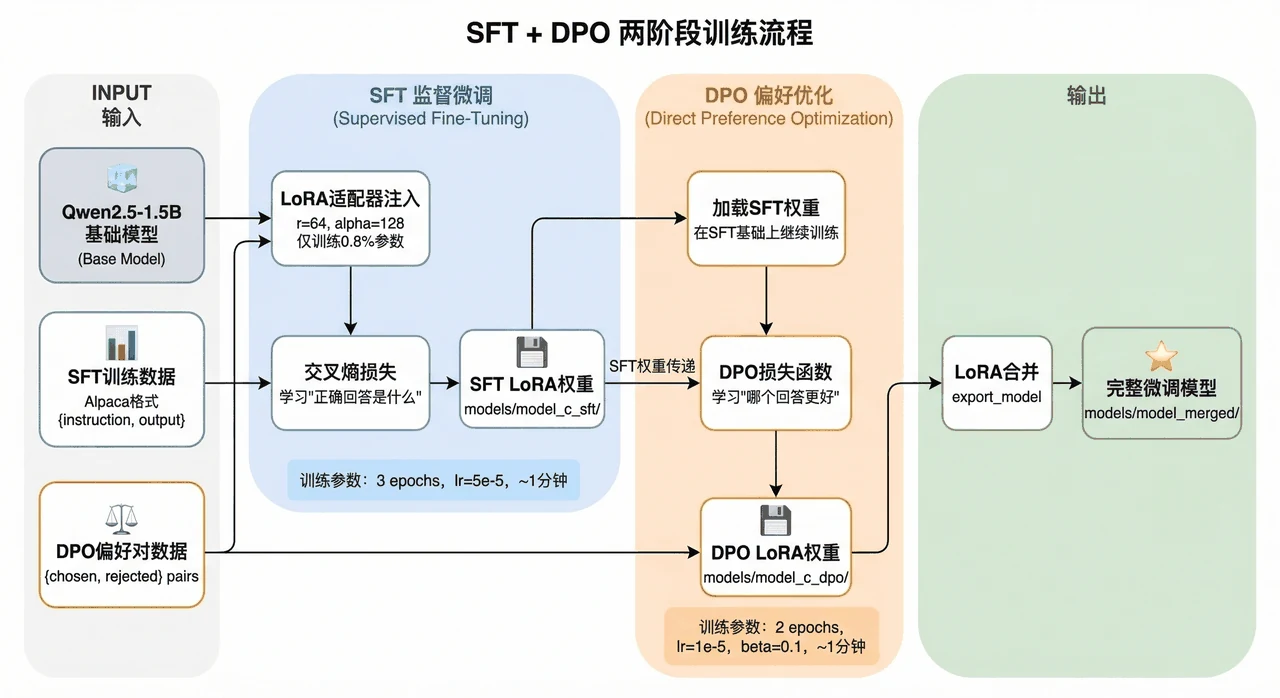
DPO 相比 RLHF / PPO 好在哪。 这是当下面试的热点。你能讲清楚:DPO 不需要单独训练一个奖励模型,直接用偏好对优化模型的概率比,计算更省、训练更稳——这正是它越来越流行的原因。
"执行反馈自动造数据"这套机制是怎么保证质量的。 项目用三层验证(验证函数交叉检验、语义一致性检查、质量评分过滤)层层把关,最后留下的都是高质量样本。你能借此讲清楚"无人工标注"为什么还能保证数据可靠。
下面这组图也都给你做好了,可以直接放进答辩或面试 PPT:
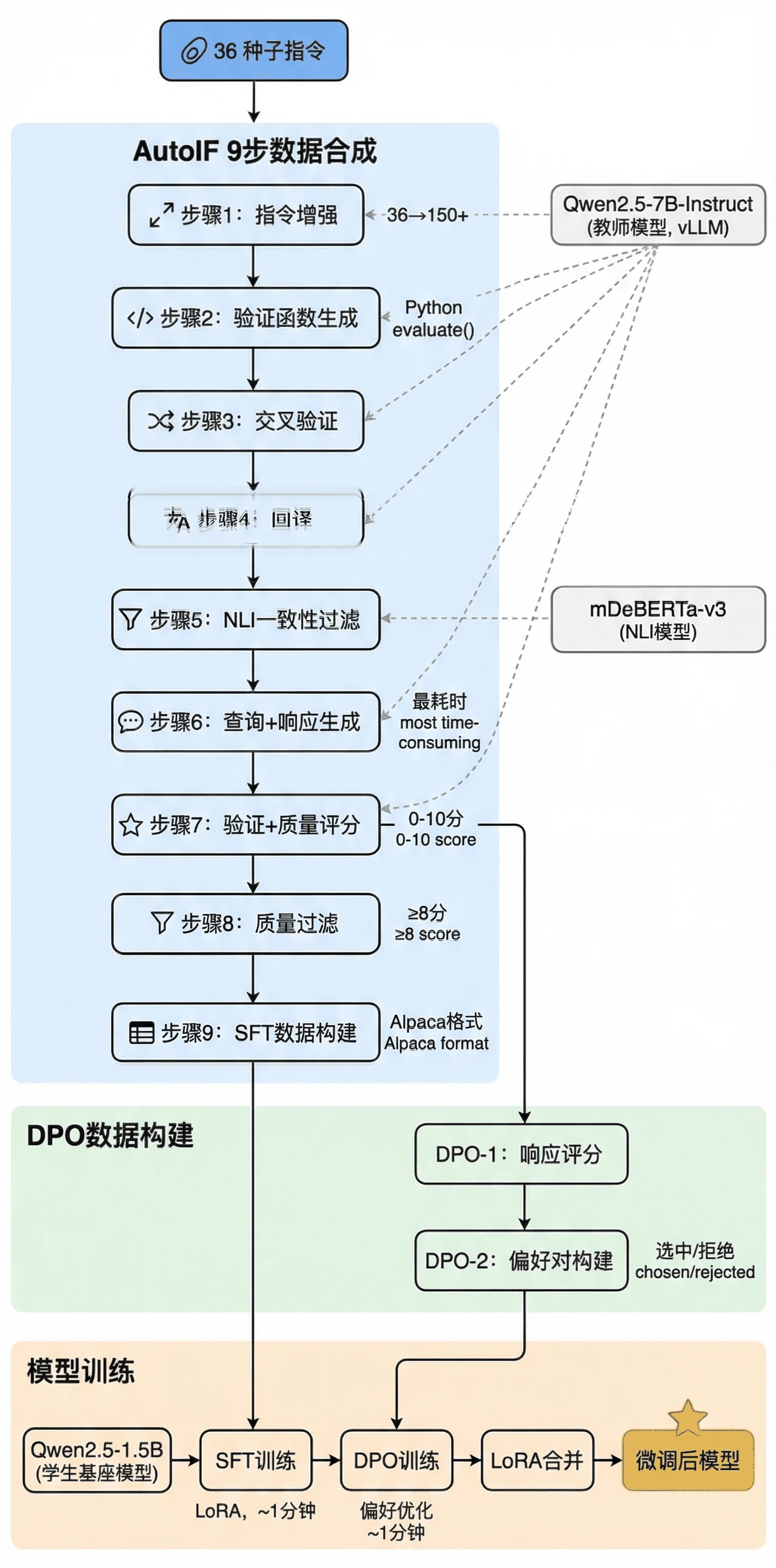
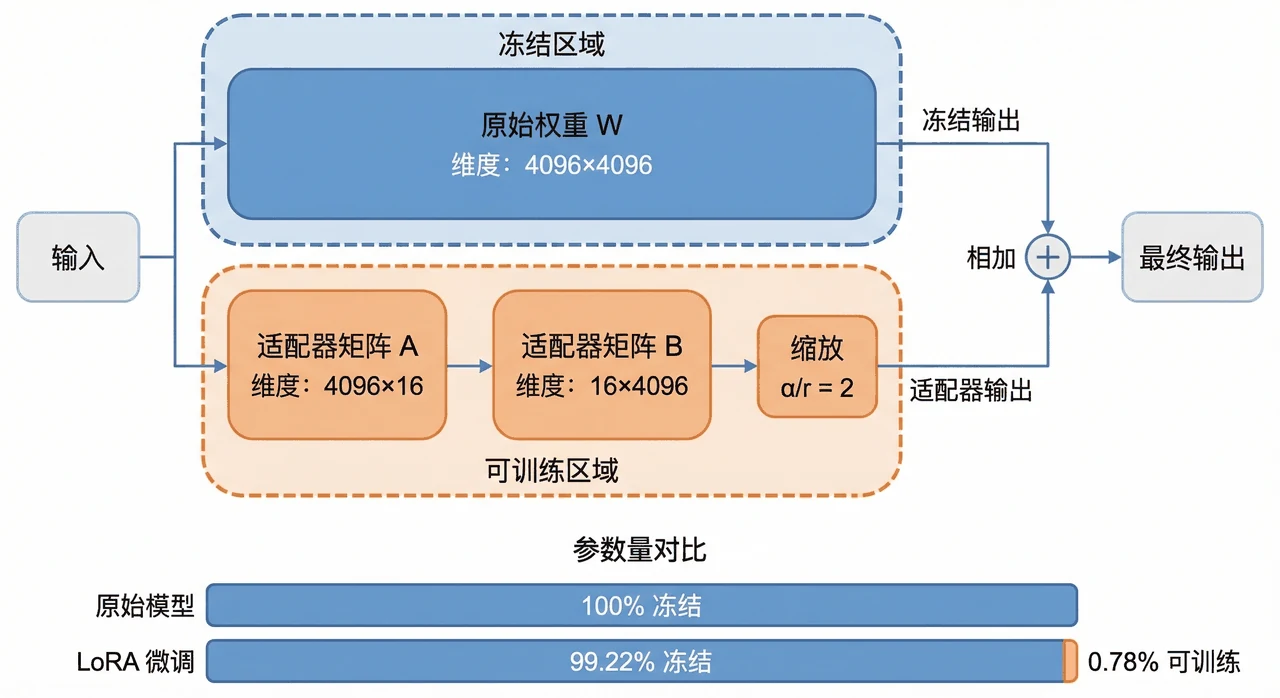
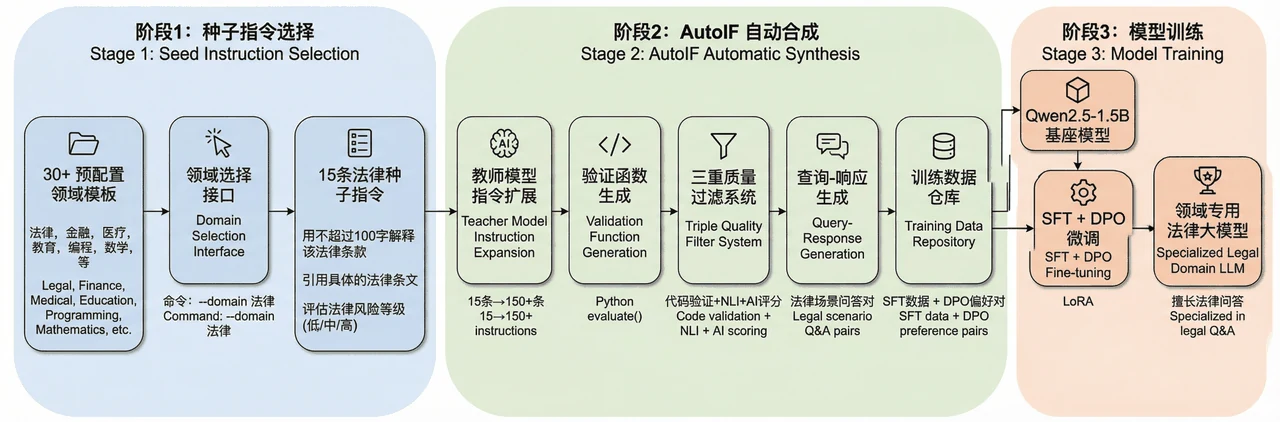
更关键的是,每一步、每张图怎么来的,技术文档里都讲清楚了——你能说明白整条流水线到底在做什么。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
- DPO 相比 PPO/RLHF 为什么更高效?损失里那个 β 参数起什么作用?
- 验证函数是怎么从一句自然语言指令自动生成 Python 代码的?
- 已经做了 SFT,为什么还要再做 DPO?SFT 学不到格式约束吗?
看到会愣一下?正常。配套的面试问答文档把这个项目——从整体思路到每个流程细节、各种可能被追问的点——连参考答案都给你写好了。另外还有现成的简历描述,照着改就能写进简历;那套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。
配套资料:搞懂一个项目需要的,这里全都有
先看那份技术文档——从对齐背景、自动数据合成、SFT/DPO 原理一直讲到 LoRA 与训练细节,图文并茂:

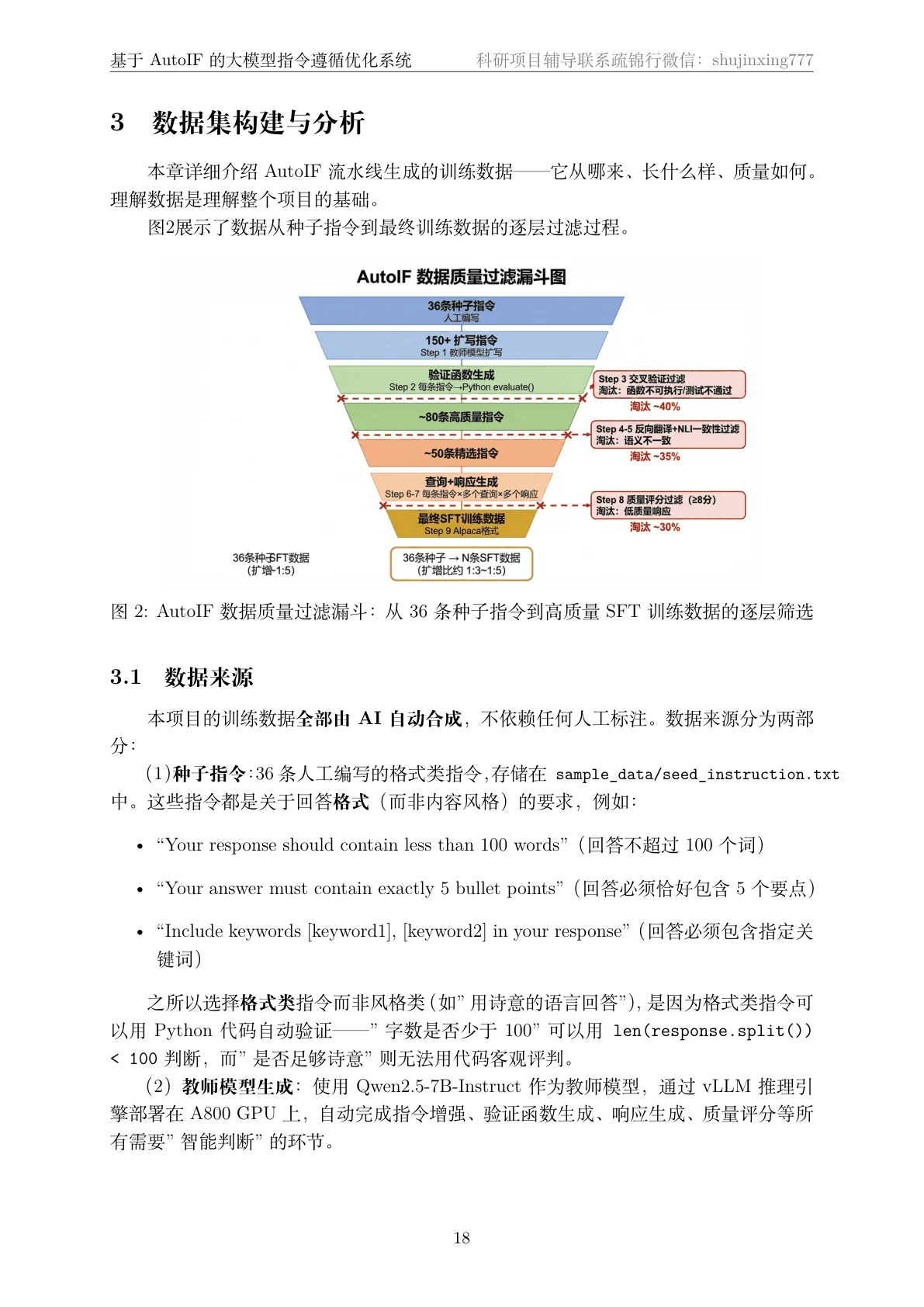
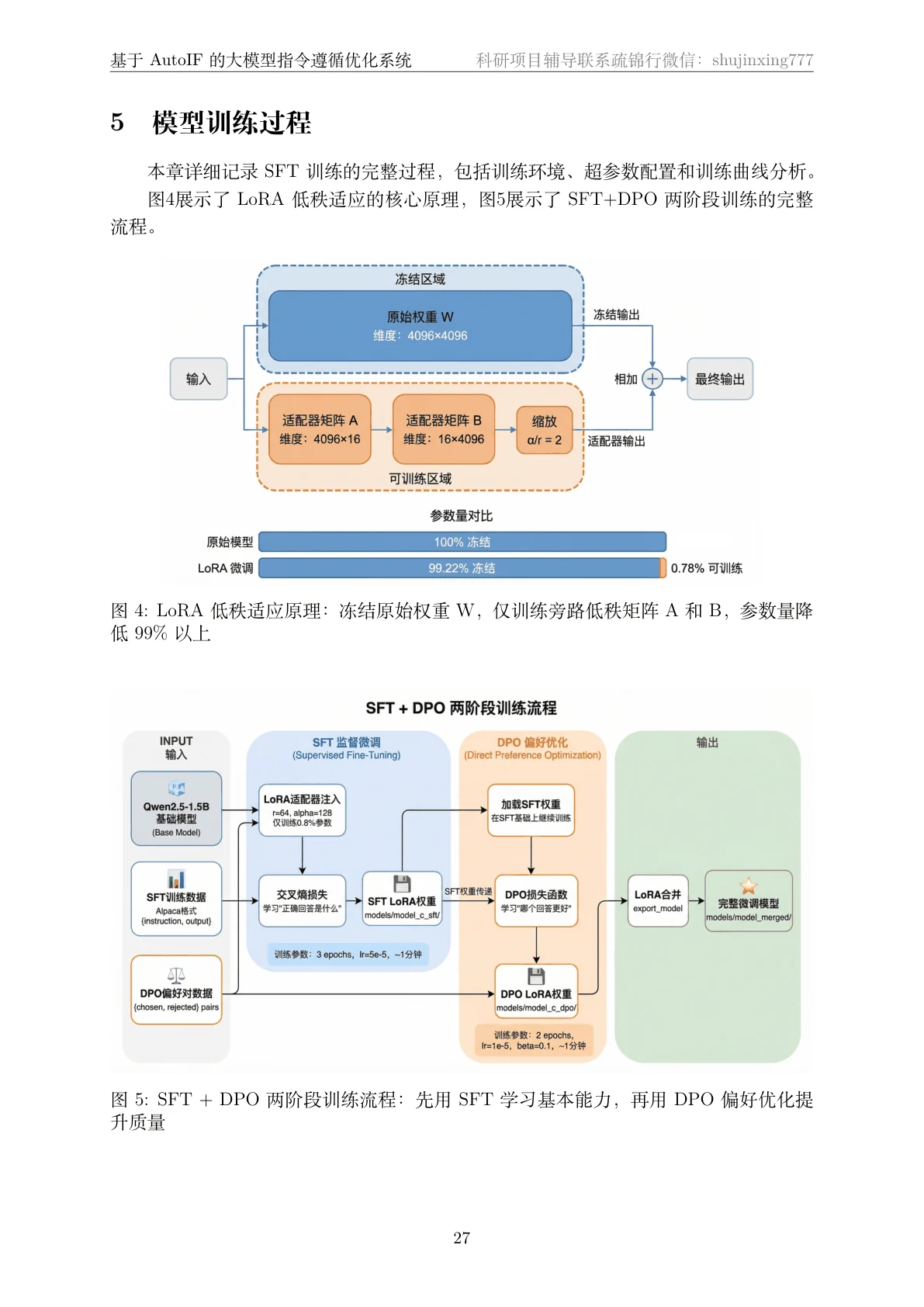
代码也给你了——关键部分都带着中文注释,帮你读懂"它到底是怎么实现的":
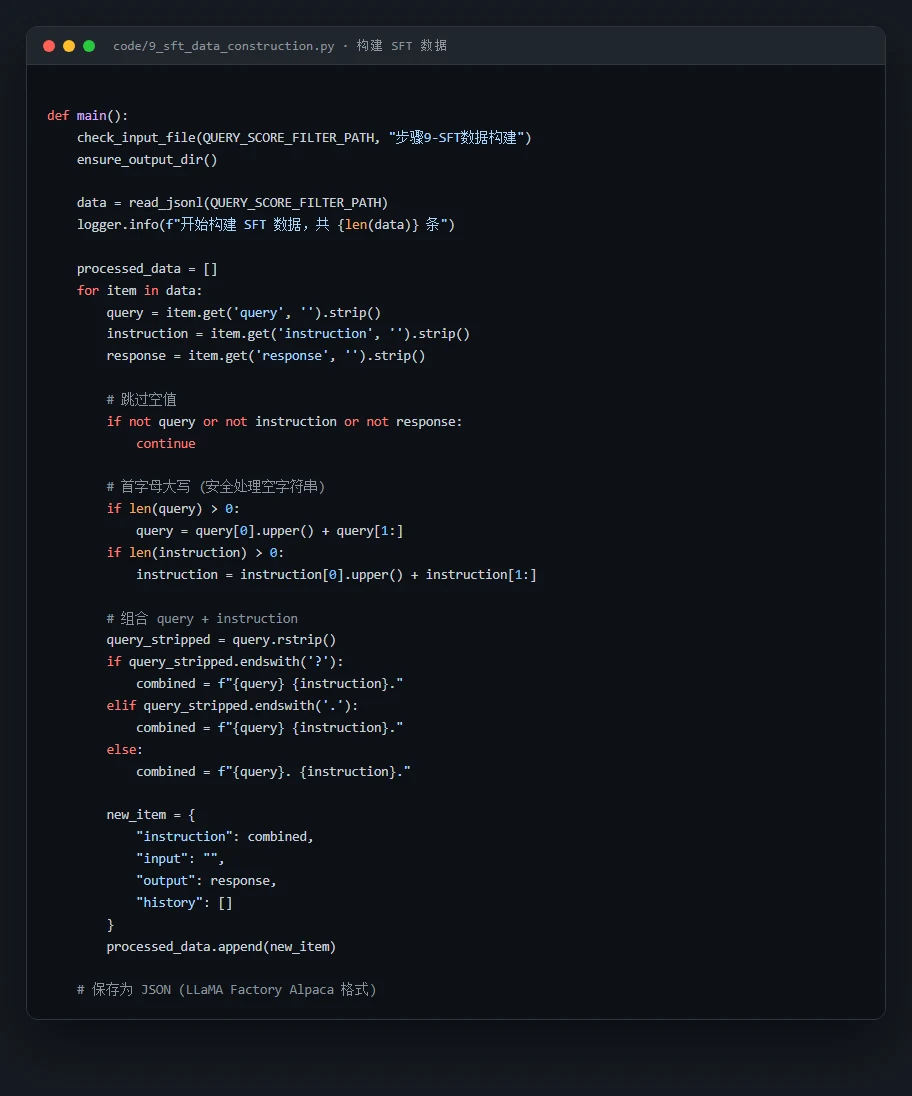
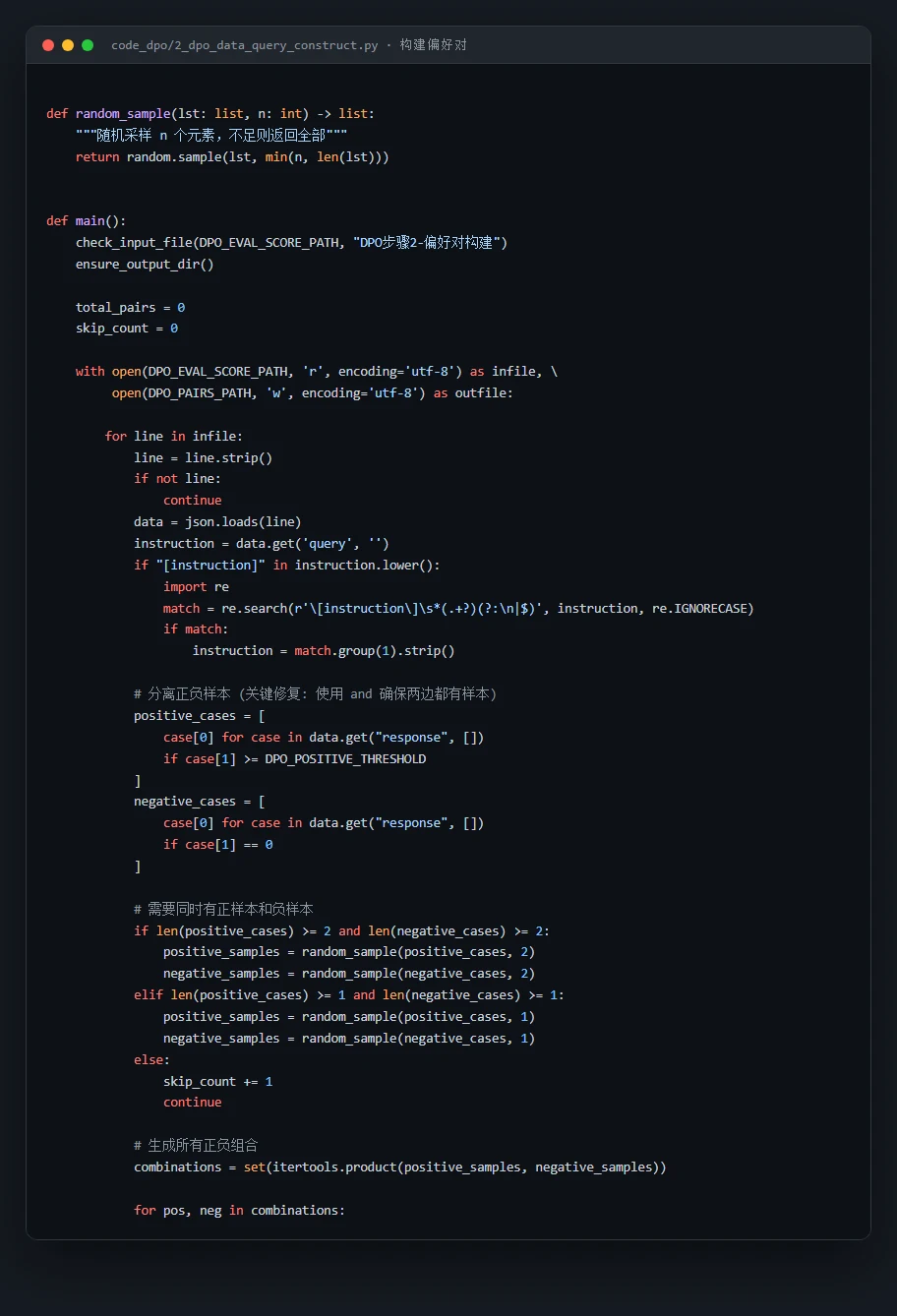
技术文档、面试问答、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添个有分量的项目,还是在准备面试,这个题目都接得住。专业上,计算机、人工智能、软件工程、数据科学方向都很合适。大模型微调与对齐是当下最热的方向之一,把它真正搞懂、能讲出来,就是一个能写进简历、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「基于 SFT + DPO 两阶段微调的大模型指令遵循优化」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。