生理门控的免训练混合解码:噪声鲁棒的心音信号分割
把心音图(PCG)逐点切成 S1、收缩期、S2、舒张期四个心动状态,是杂音检测、瓣膜筛查的前置。在 CirCor 真实临床数据上用 1-D U-Net 做逐点分割,再以免训练的 HSMM 时长-Viterbi 混合解码 + 生理合理性门控,让分割在各种噪声下都站得住。
项目亮点
- On a fair, patient-disjoint benchmark, a deep 1-D U-Net clearly beats the classical Springer
- But under in-band noise the deep model collapses — and does so *confidently* (calibration
- That failure is measurable without labels, so we turn it into a fix: a **training-free hybrid
- No like-for-like comparison of deep vs the classical HSMM existed on CirCor — prior numbers
数据与任务
| 样本量 | CirCor DigiScope 2022 · 真实临床心音 · 患者不重叠切分 |
|---|---|
| 核心方法 | 1-D U-Net 逐点分割 + HSMM 时长-Viterbi 混合解码 + 生理门控 |
| 技术栈 | PyTorch · 信号处理 · HSMM |
如果你想找一个医疗 AI 味道浓、又能把"深度模型 + 经典信号方法怎么配合"讲明白的项目,这个「心音信号自动分割」很合适。
它的方向又硬又有临床价值——把听诊器拾到的心音切成 S1、收缩期、S2、舒张期四个心动状态,这是后面判断杂音、筛查瓣膜病的第一步。配套也给你备齐了,帮你真正搞懂它、在面试和答辩里讲明白:带中文注释、能读懂的代码,一份从背景讲到方法与实验的技术说明文档,里面连简历描述和会被追问的面试问题都连答案写好了,还有一整套能直接做 PPT 的配图。
先说清楚,它到底在做什么
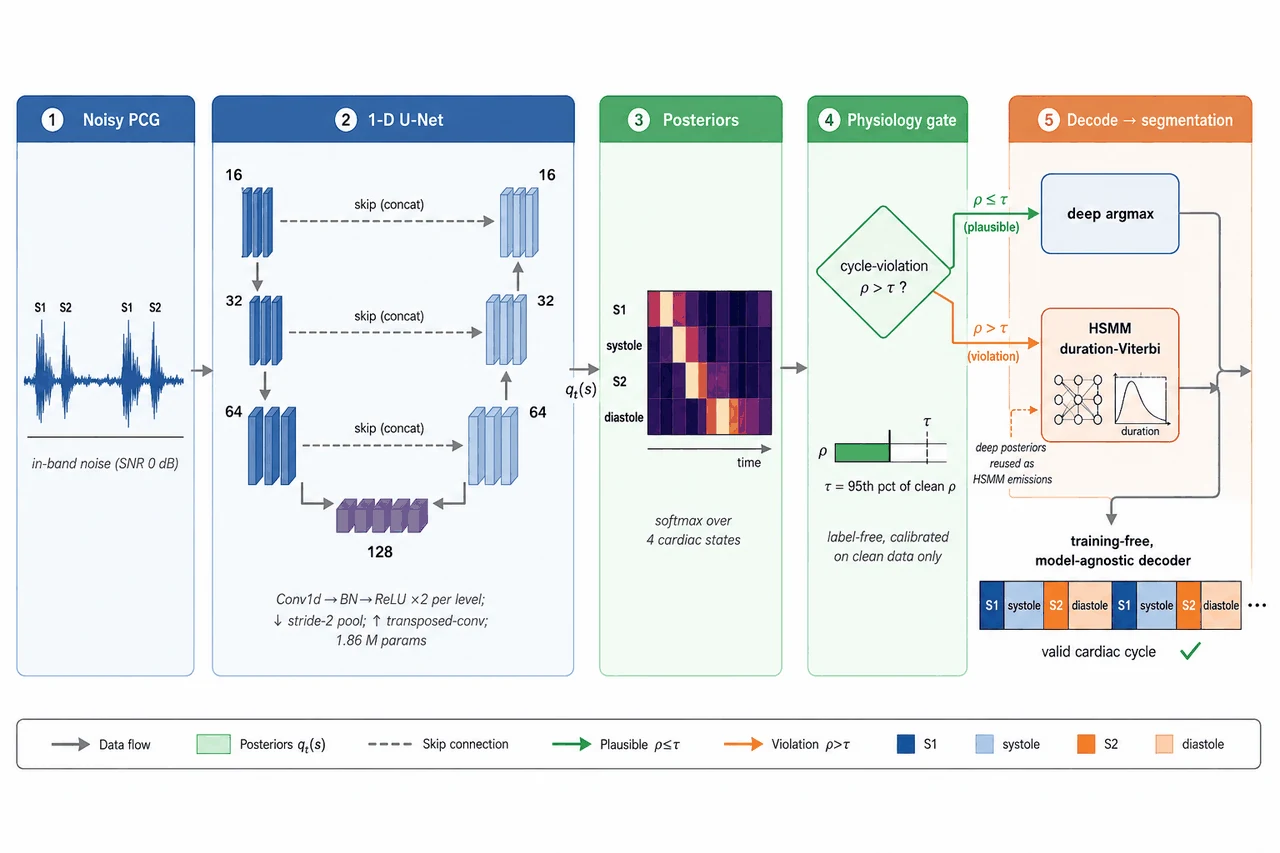
心音图(PCG)是听诊器拾取的心脏机械活动信号。一个完整心动周期严格按环序走:S1(房室瓣关闭)→ 收缩期 → S2(半月瓣关闭)→ 舒张期,再回到下一个 S1。这个项目要做的,就是把一段心音逐采样点切成这四个状态——它是杂音落在收缩期还是舒张期、瓣膜异常定位等所有下游分析的第一步,切错了下游全错。
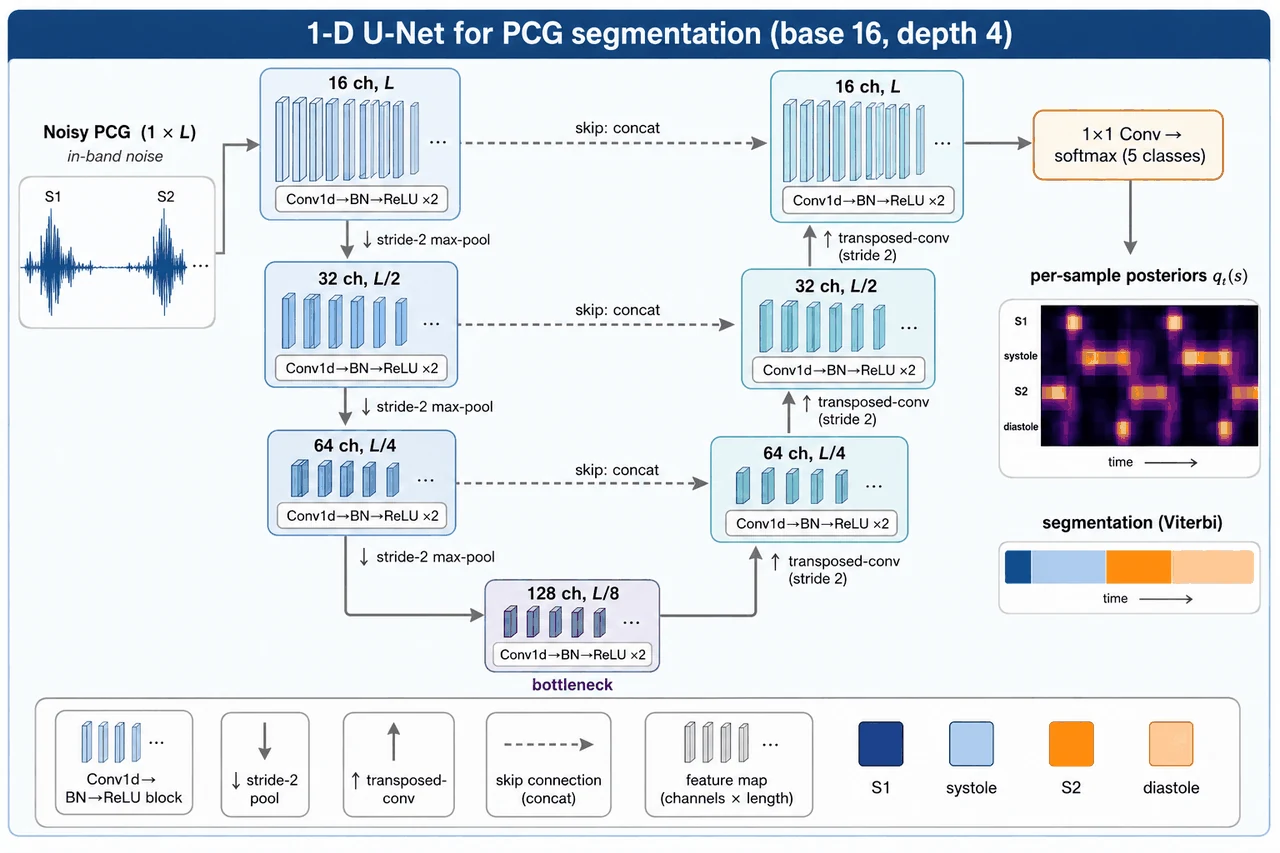
数据来自目前最大的公开心音数据集 CirCor DigiScope 2022,覆盖四个标准听诊位置、标注了有无杂音。项目用 1-D U-Net 做逐点分割(编码器提特征、解码器恢复时间分辨率、跳跃连接保住精细边界),输出每个点在四个状态上的概率。但真正出彩的地方,是它没有止步于"训一个深度模型",而是把深度模型和经典的隐半马尔可夫(HSMM)时长解码巧妙地接在了一起。
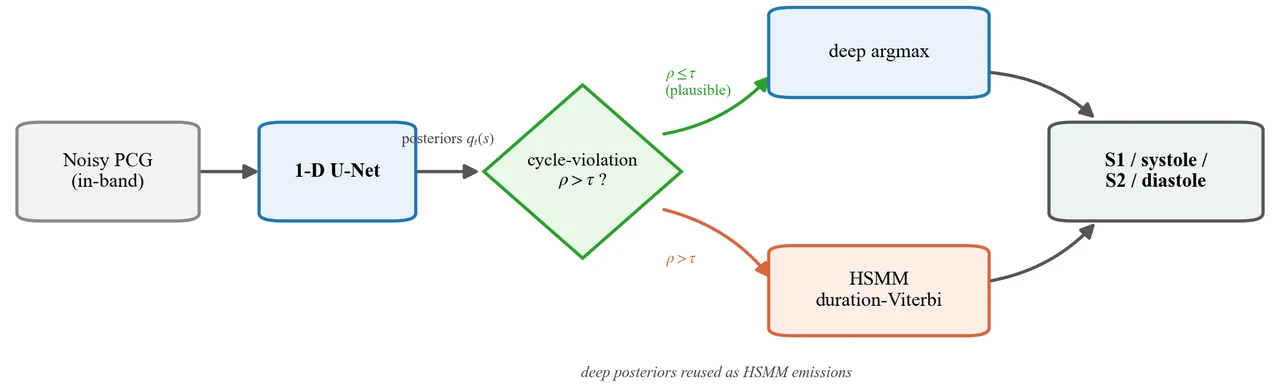
搞懂它,你能在面试里讲清楚什么
把下面几件事吃透,面试官顺着心音分割这条线问下来你都能接得住。
1-D U-Net 怎么做逐点分割、跳跃连接在干什么。 这是项目的骨架。你要能讲清楚:U-Net 怎么逐采样点输出四个状态的概率、编码器为什么逐级下采样、解码器怎么恢复时间分辨率,以及跳跃连接为什么能把浅层的精细边界信息直接送给深层——这正是分割边界不被模糊掉的关键。
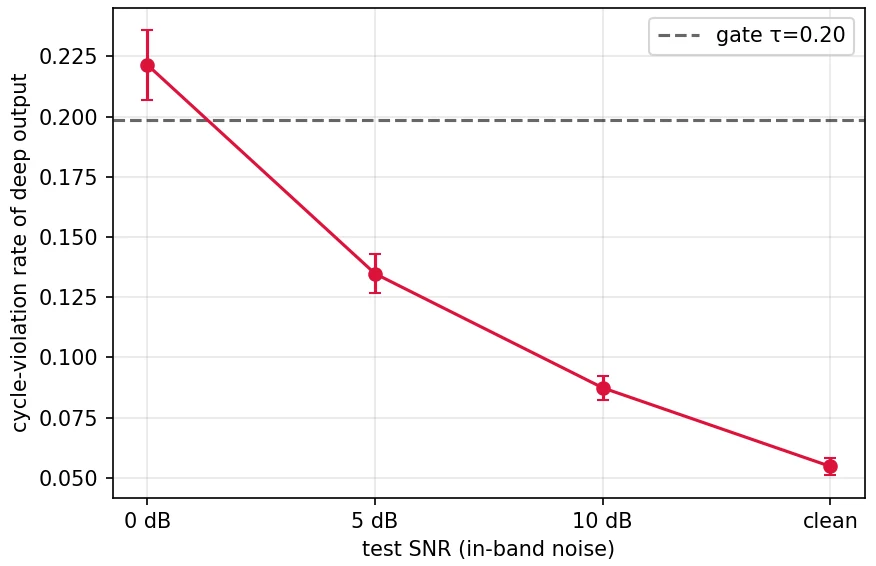
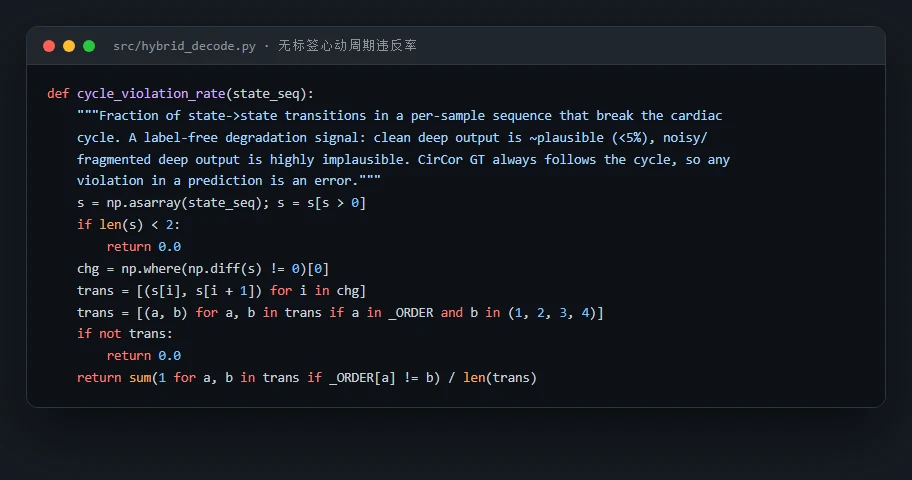
深度模型在噪声下怎么崩,而且这种崩怎么不用标签就能测出来。 这是项目最有思想含量的一点。深度模型在干净数据上很强,但一加采集噪声就会"自信地、且生理上不可能地"出错——它会切出违反 S1→收缩→S2→舒张环序的序列。项目定义了一个心动周期违反率:只看预测序列自己就能算、完全不需要标签,却能随噪声单调上升。你要能讲清楚:为什么这是个可在线监控的退化信号,以及它为什么比"等有了金标准才发现错"高明得多。
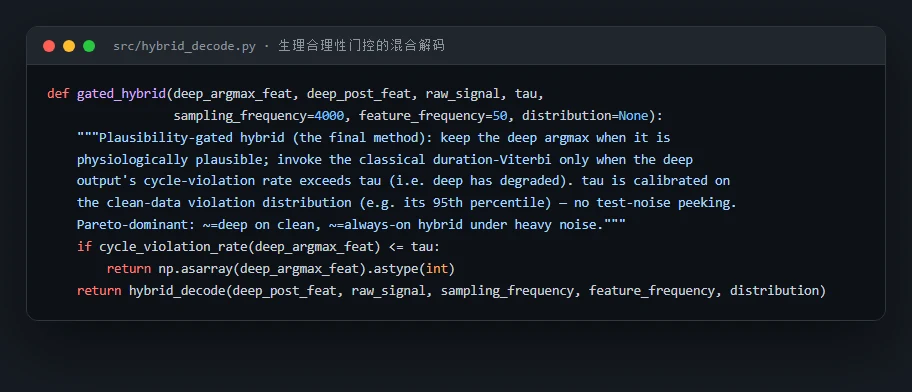
免训练的混合解码器怎么把深度和经典的长处接在一起。 这是项目的落点。做法很巧:把深度模型的逐点后验当作经典 HSMM 时长-Viterbi 解码器的发射概率——深度负责"每个点像哪个状态",经典负责"每个状态该持续多久、必须按环序走",二者拼接不改一个权重、无需重训。再用违反率做门控,只在深度输出不合理时才启用。你要能讲清楚:为什么这是"免训练、模型无关"的、为什么它能在全噪声范围内取两者之长。
下面这组实验图也都给你做好了,可以直接放进答辩或面试 PPT:
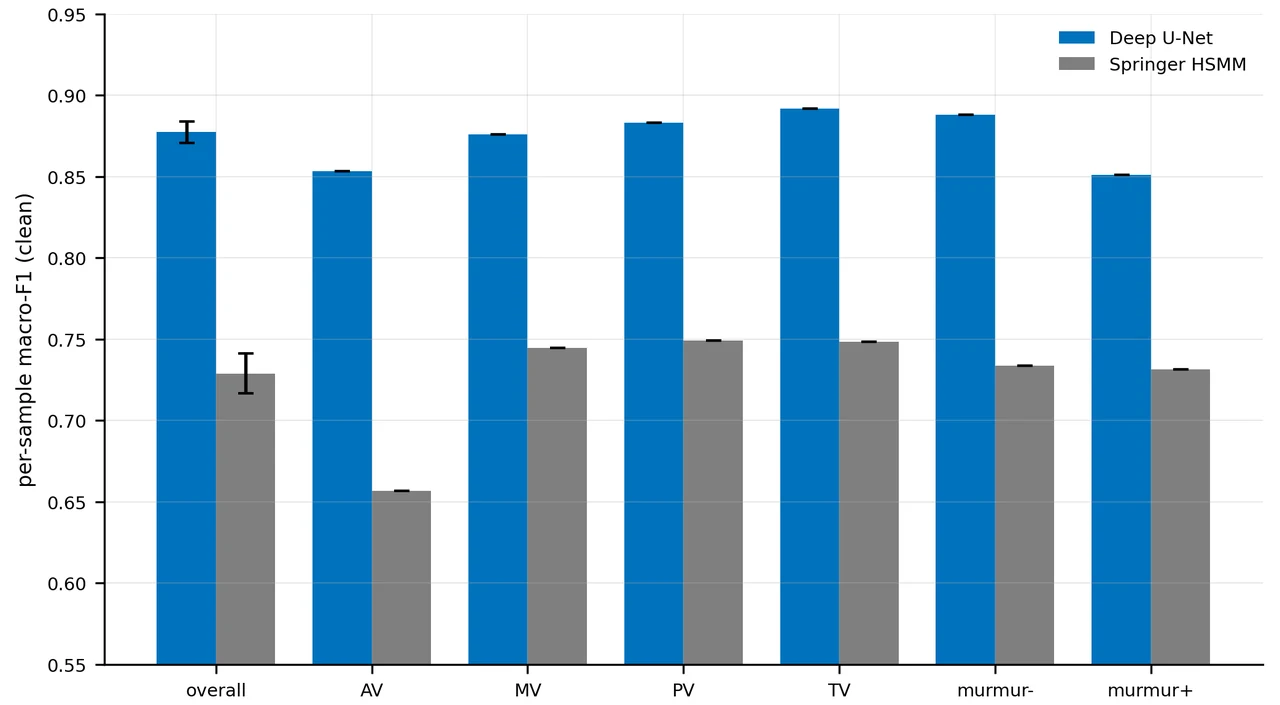
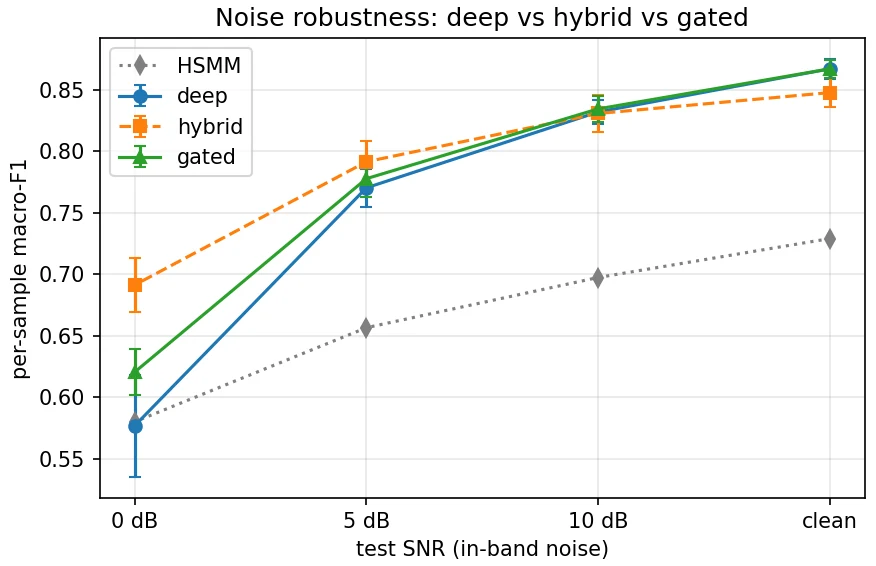
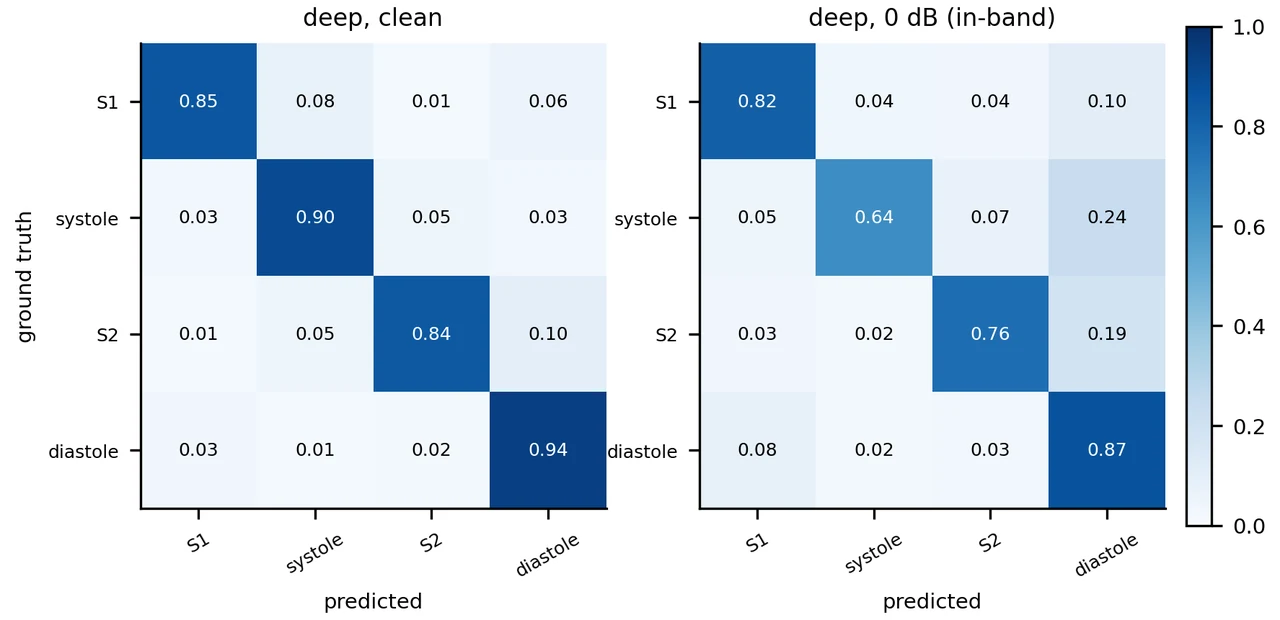
更关键的是,每张图怎么跑出来的、该怎么解读,技术文档里都讲清楚了——比如混淆矩阵里收缩期为什么会被噪声"抹"成舒张期,而这恰恰是时长先验最擅长修复的那类错误。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
心音为什么要切成 S1、收缩期、S2、舒张期四个状态?切错了会影响什么?
U-Net 的跳跃连接在分割里到底起什么作用?为什么逐点分割需要它?
你说的"心动周期违反率"是什么?为什么它不需要标签就能算出来?
混合解码器是怎么把深度模型和经典 HSMM 接在一起的?为什么说它免训练、模型无关?
看到会愣一下?正常。配套的项目讲解资料把这个项目——从整体思路到每个流程细节、各种可能被追问的点——连参考答案都给你写好了,连"深度强在哪、经典强在哪、门控为什么取两者之长"这种判断题都帮你梳理好了。另外还有现成的简历描述,照着改就能写进简历;那套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。
配套资料:搞懂一个项目需要的,这里全都有
先看那份技术说明文档——从心音分割背景、CirCor 数据、U-Net 逐点分割,一直讲到违反率、混合解码与门控,再到各类实验结果,图文并茂:

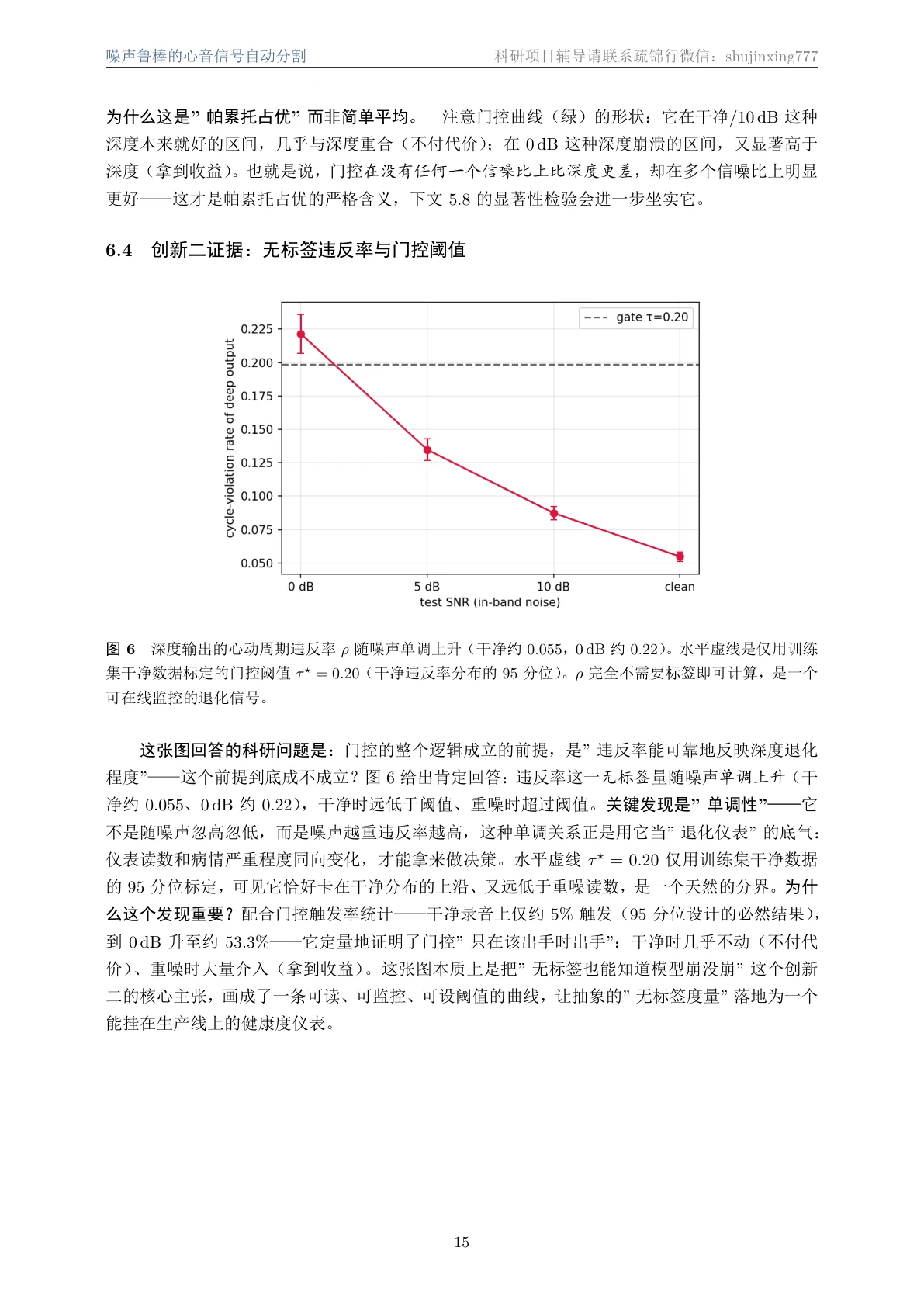
代码也给你了——关键部分都带着中文注释,帮你读懂"它到底是怎么实现的":左边是无标签的心动周期违反率,右边是生理门控的混合解码逻辑:
技术文档、项目讲解资料、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添个有医疗 AI 分量的项目,还是在准备面试,这个题目都接得住。专业上,计算机、人工智能、医学/生物医学工程、数据科学方向都很合适——尤其是想往医疗信号处理、智能诊断、可穿戴健康监测方向走的同学。把"怎么用 U-Net 做逐点分割、怎么用无标签信号度量模型退化、怎么把深度和经典方法接在一起取长补短"这条完整链路真正搞懂、能讲出来,就是一个既有临床价值、又有方法论分量、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「生理门控的免训练混合解码:噪声鲁棒的心音信号分割」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。