基于深度学习的行人重识别系统
做跨摄像头的行人重识别:用度量学习 + BNNeck 双分支把行人映射到特征空间,靠距离排序完成检索。硬样本挖掘 Triplet + 多损失对比 + 多骨干网络评测——带注释代码、技术文档、面试问答全配齐。
数据与任务
| 样本量 | Market-1501 · 1501 ID |
|---|---|
| 核心方法 | 度量学习 + BNNeck |
| 技术栈 | PyTorch |
如果你想找一个有挑战、又在安防/智能监控里很实用的视觉项目,这个「行人重识别(ReID)」很合适。
它落在度量学习这个有深度的方向上,配套也给你备齐了,帮你真正搞懂它、在面试和答辩里讲明白:带中文注释、能读懂的代码,一份从背景讲到每步实现的技术文档,一份把面试问题连答案都写好的问答文档,还有一整套能直接做 PPT 的配图。
先说清楚,它到底在做什么
行人重识别要解决的是:同一个人在不同摄像头下拍到的画面,能不能自动匹配上。难点在于:同一个人因为视角、光照、遮挡变化很大,而不同人有时却长得像——这不是普通分类(测试时的人在训练集里根本没出现过),而是度量学习 + 开放集检索问题。
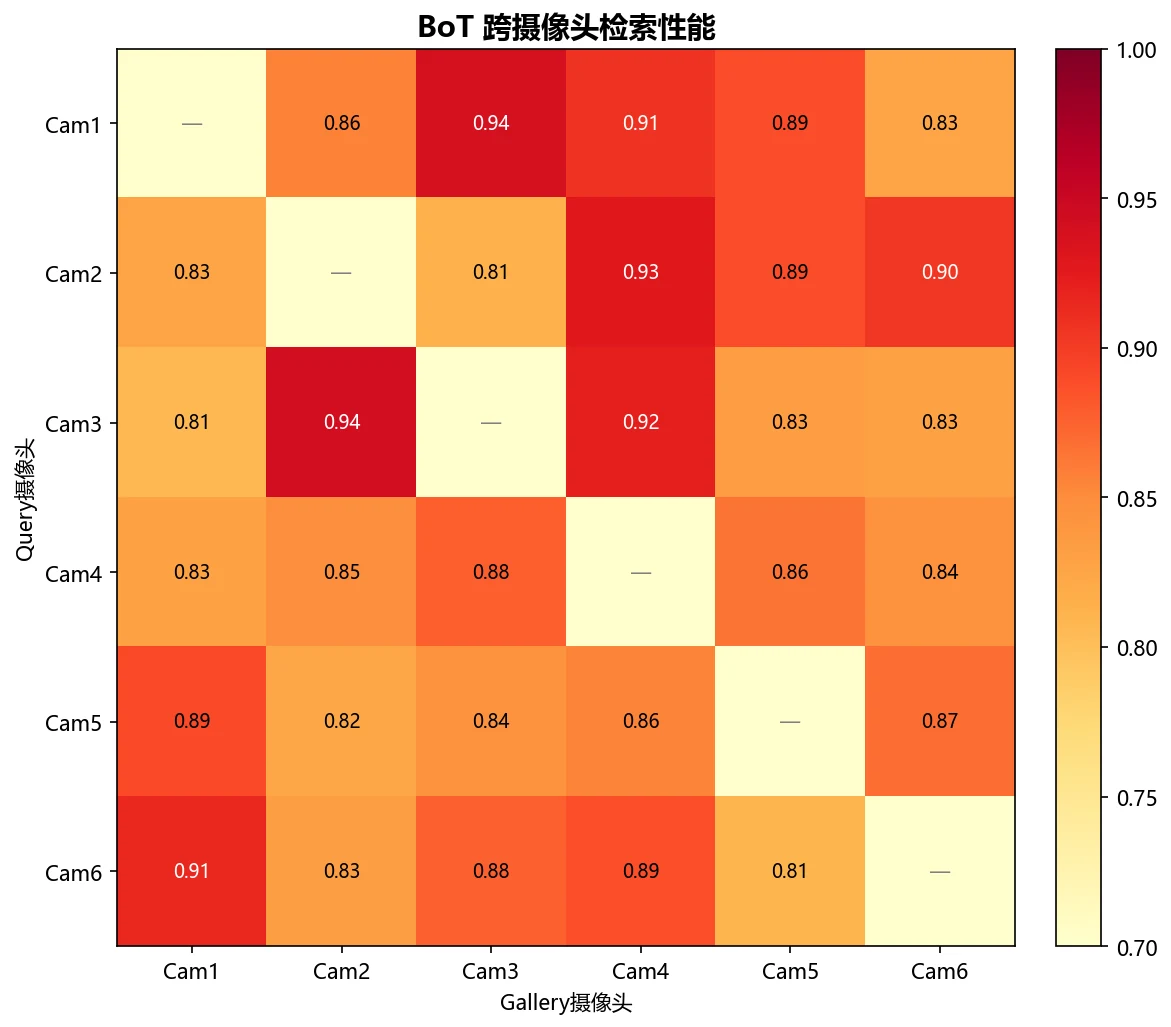
这个项目用度量学习把行人图片映射到一个特征空间,让同一个人的特征聚在一起、不同人的分开;测试时对一张查询图,按特征距离排序返回最相似的候选。关键设计是 BNNeck 双分支(一支做度量学习、一支做 ID 分类),并系统对比了多种骨干网络和损失函数。
搞懂它,你能在面试里讲清楚什么
把下面几件事吃透,面试官顺着问下来你都能接得住。
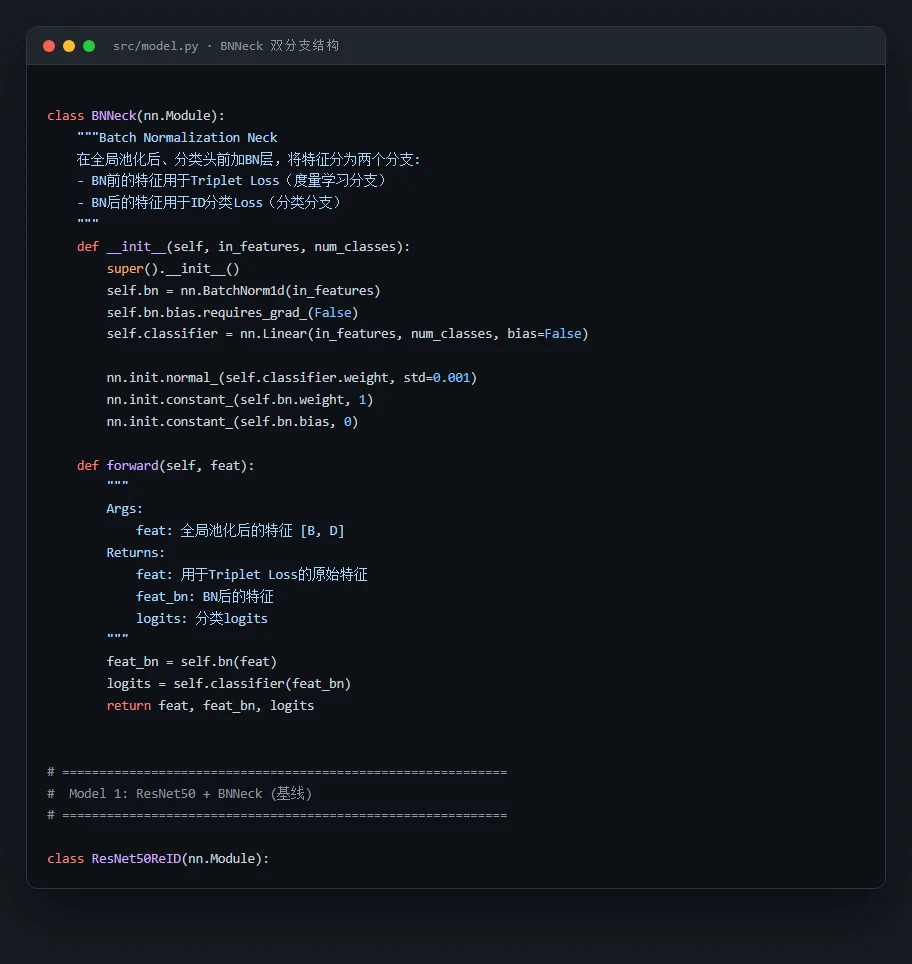
度量学习和 BNNeck 双分支为什么这么设计。 这是项目的灵魂。你要能讲清楚 ReID 为什么是度量学习而非分类,以及 BNNeck 为什么分两支——一支(BN 前特征)做 Triplet 的距离约束、一支(BN 后特征)做分类判别,两者对特征的要求不同。
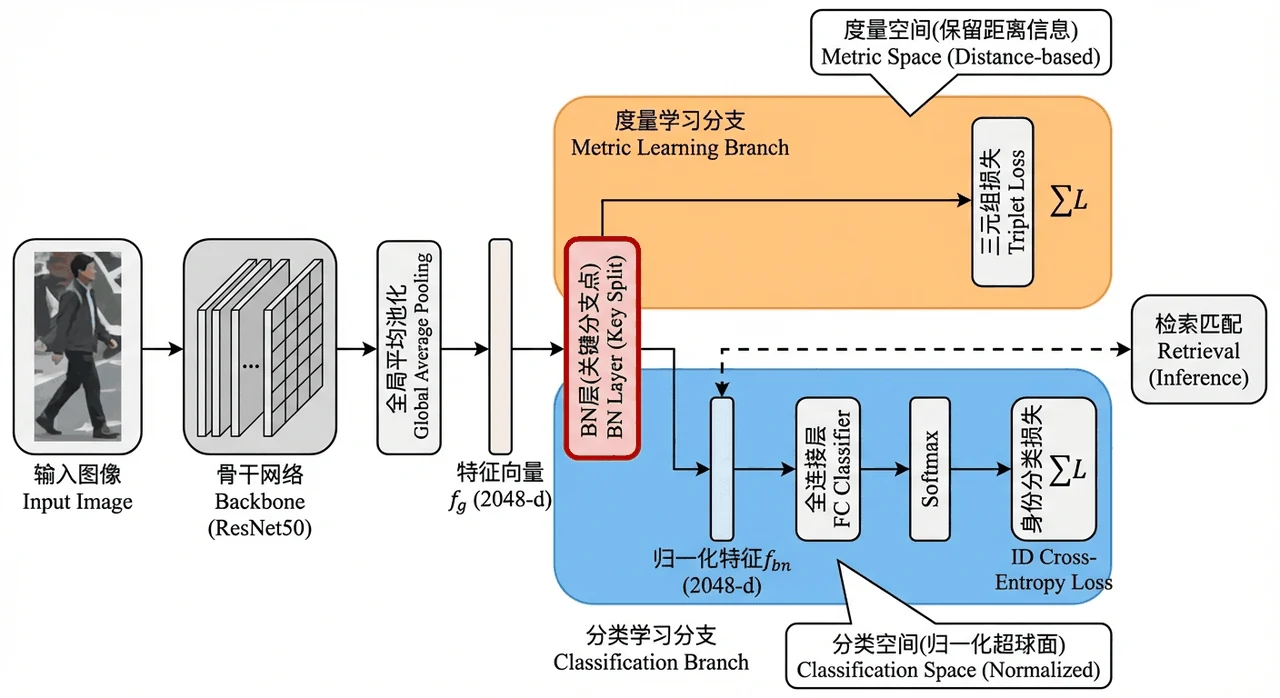
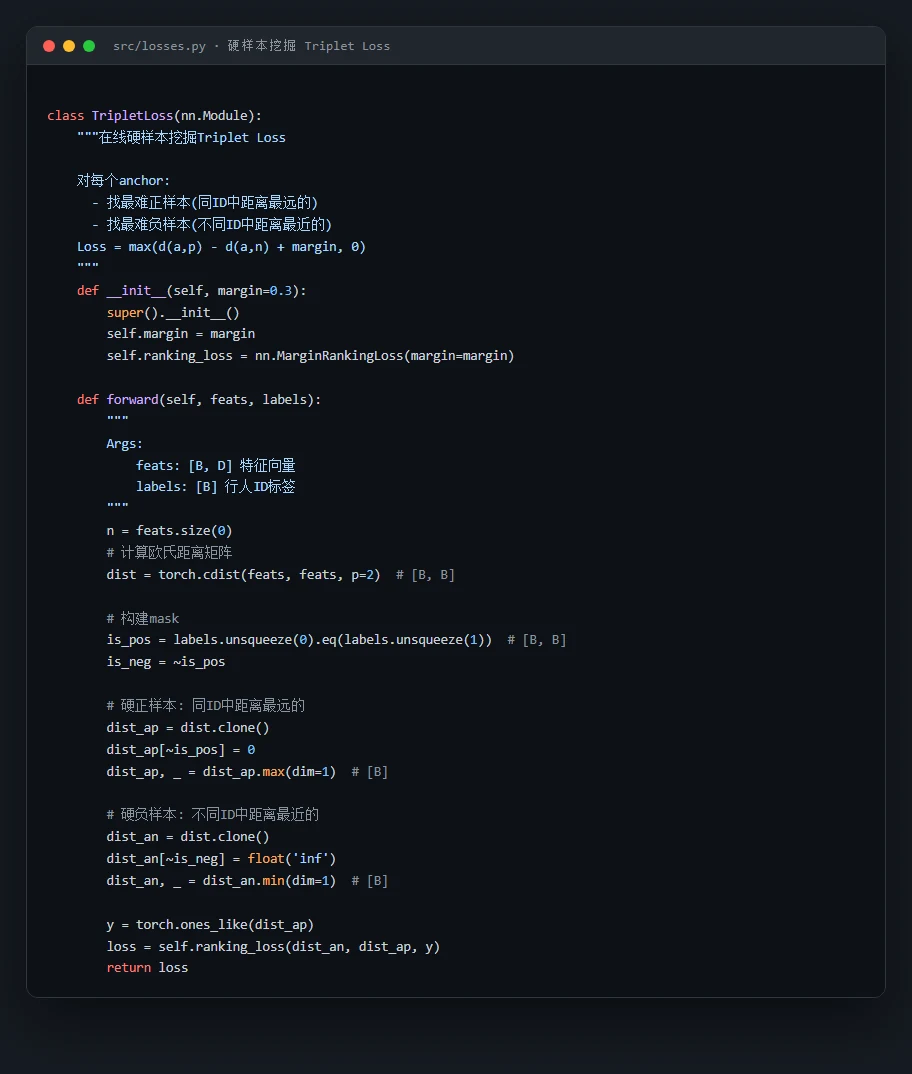
硬样本挖掘的 Triplet Loss。 你能讲清楚 Triplet Loss 怎么"拉近正样本、推远负样本",以及在线硬样本挖掘怎么自动挑最难的正负样本来加速学习;还有 PK 采样、Random Erasing 这些 ReID 特有的训练技巧。
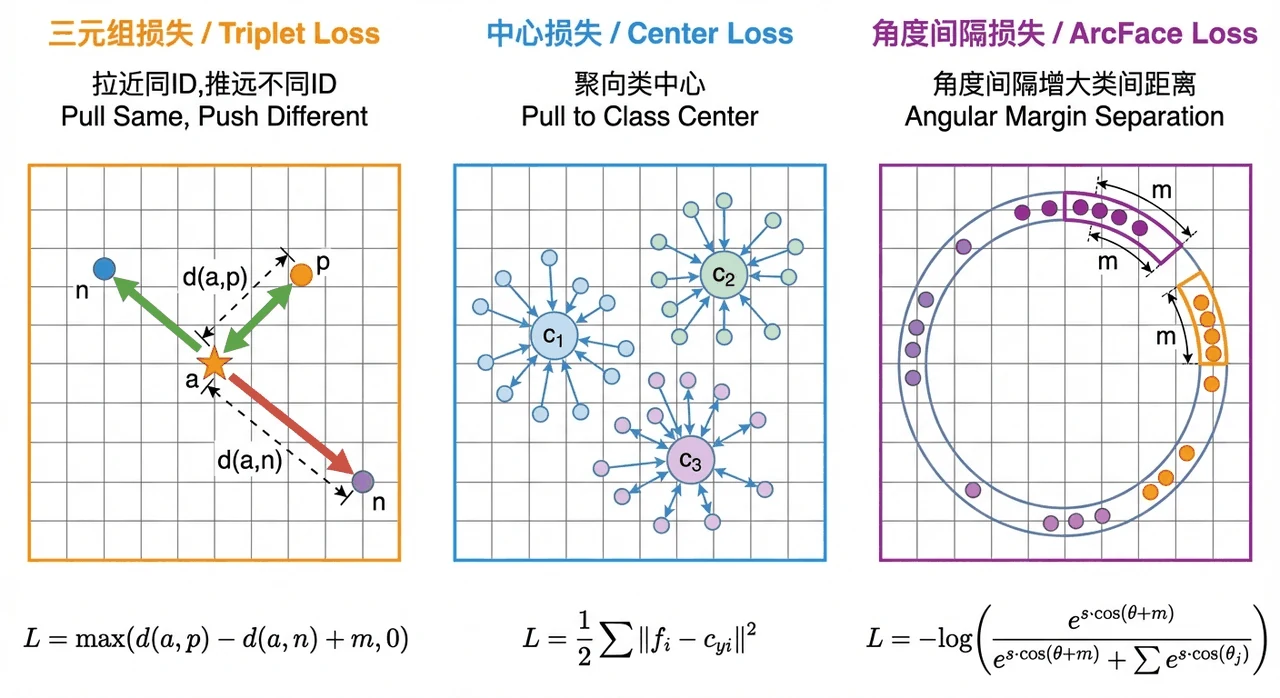
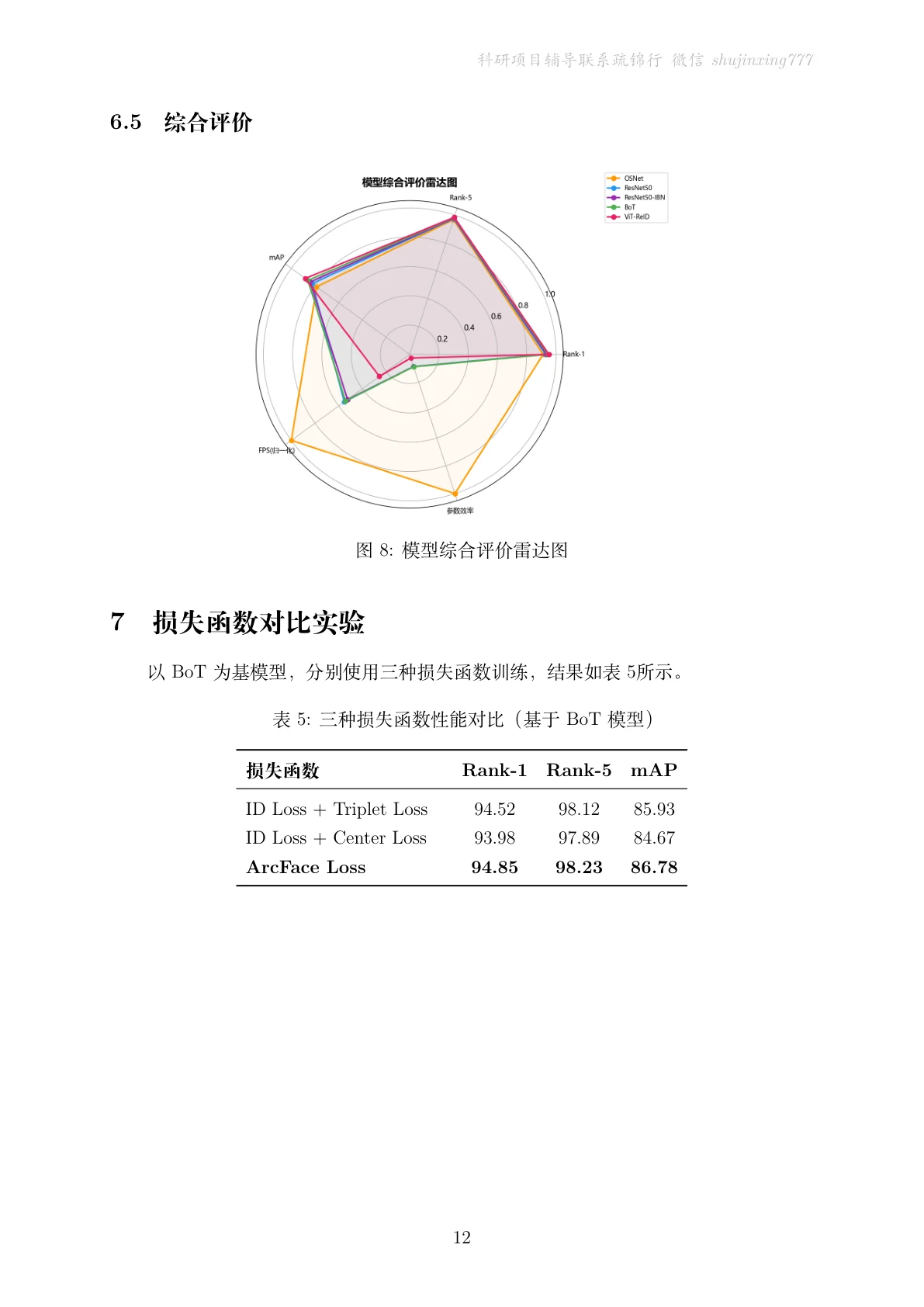
多损失对比里的取舍。 项目对比了 Triplet、Center、ArcFace 等损失。你能借此讲清楚不同损失从距离、聚集、角度间隔等角度约束特征空间的差异。
下面这组分析图也都给你做好了,可以直接放进答辩或面试 PPT:
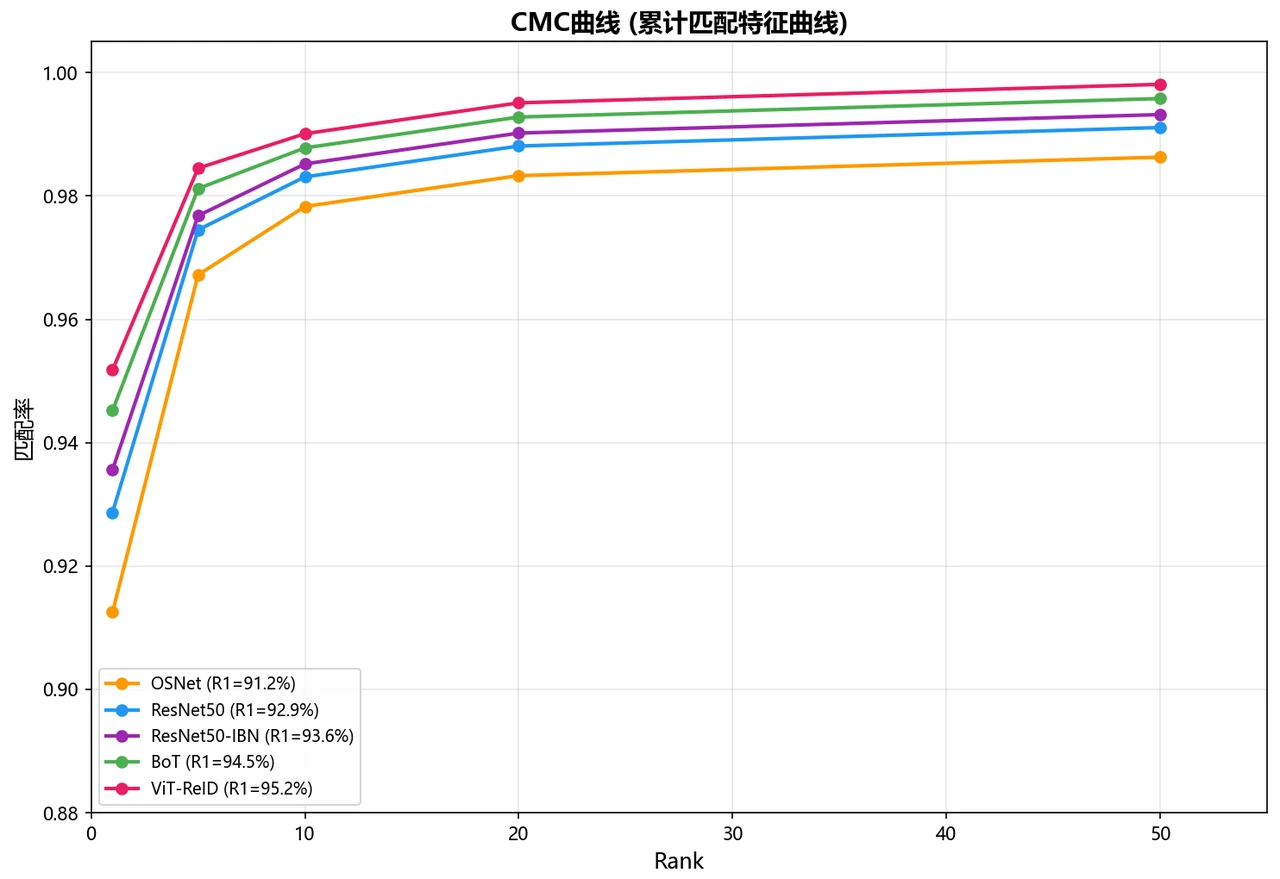
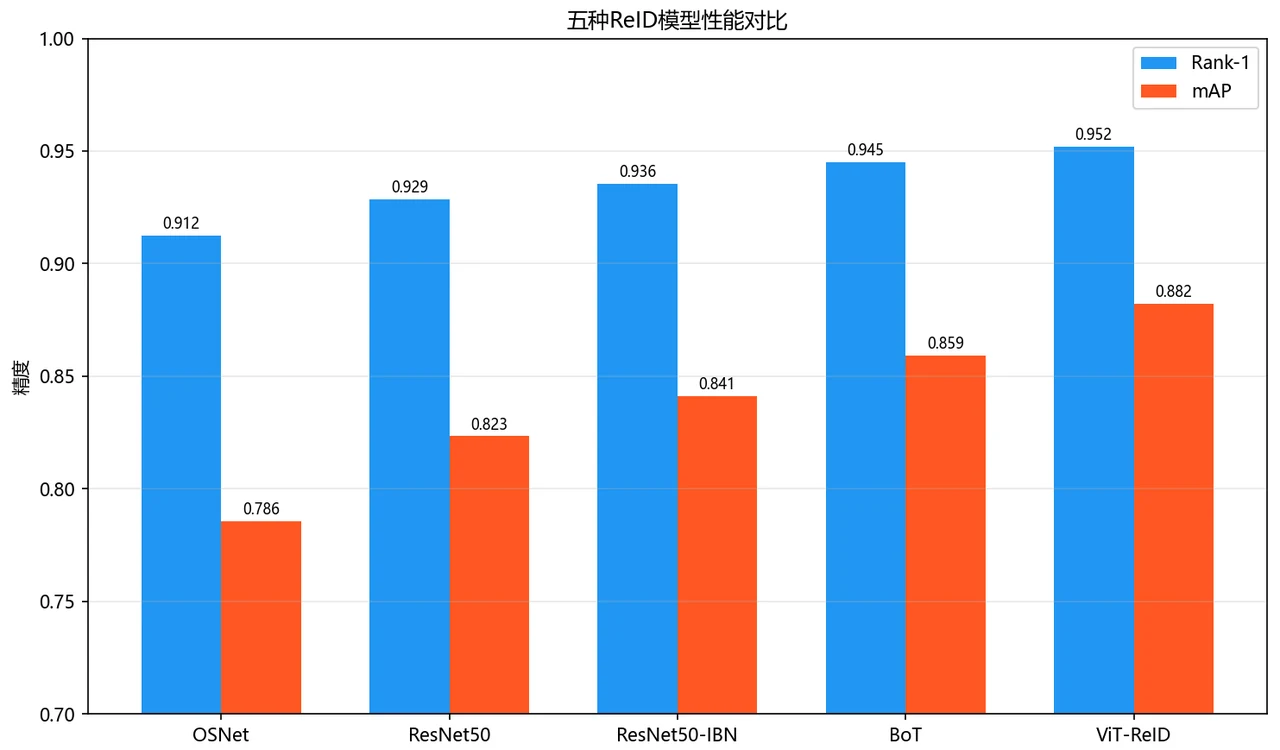
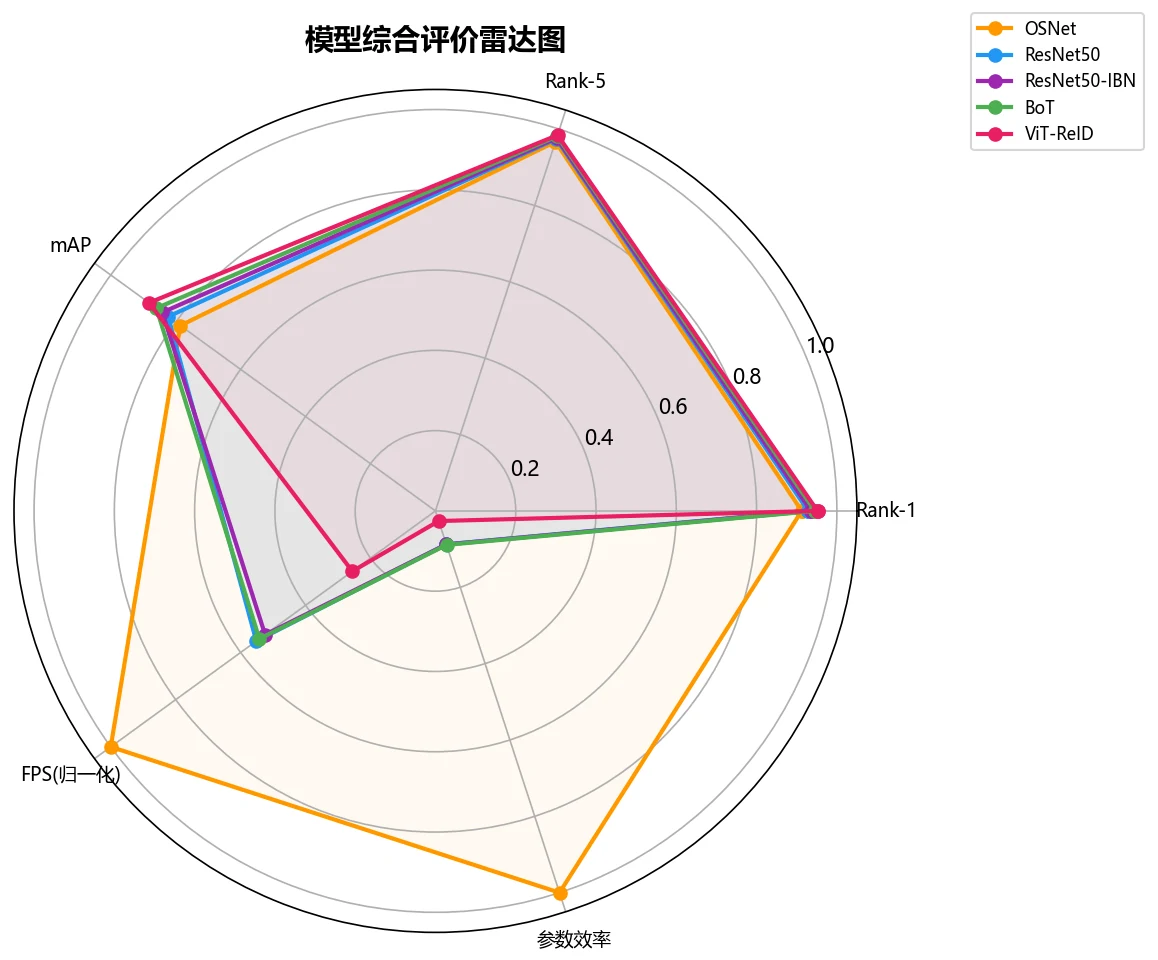
更关键的是,每张图怎么跑出来的、该怎么解读,技术文档里都讲清楚了——你能说明白每张图到底说明了什么。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
- 为什么 BNNeck 要分两个分支,不能只用一个特征?
- 测试时出现训练集里没有的陌生行人,系统怎么处理?
- Triplet 的在线硬样本挖掘是怎么选样本的?为什么能加速收敛?
看到会愣一下?正常。配套的面试问答文档把这个项目——从整体思路到每个流程细节、各种可能被追问的点——连参考答案都给你写好了。另外还有现成的简历描述,照着改就能写进简历;那套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。
配套资料:搞懂一个项目需要的,这里全都有
先看那份技术文档——从背景、度量学习、BNNeck 与损失函数一直讲到多模型评测,图文并茂:


代码也给你了——关键部分都带着中文注释,帮你读懂"它到底是怎么实现的":
技术文档、面试问答、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添个有分量的项目,还是在准备面试,这个题目都接得住。专业上,计算机、人工智能、自动化、安防/智能监控方向都很合适。度量学习 + 检索是很有深度、面试也爱问的方向,把它真正搞懂、能讲出来,就是一个能写进简历、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「基于深度学习的行人重识别系统」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。