基于大语言模型的口腔癌风险预测
把患者的吸烟、饮酒、嚼槟榔、HPV、口腔症状等风险因素,按流行病学优势比(OR)「文本序列化」成自然语言,让大模型像口腔科医生一样逐步推理口腔癌风险、并给出可解释的诊断归因,再与 XGBoost 等 ML 基线做一组「大模型 vs 机器学习」的对照研究。
数据与任务
| 样本量 | 流行病学 OR 构建 · 均衡抽样对照 |
|---|---|
| 核心方法 | 文本序列化 + 3 种 Prompt 策略 + 大模型 vs ML 对照 |
| 技术栈 | DeepSeek-V3 · GPT-4o · Qwen-Max · scikit-learn · XGBoost |
如果你想找一个能把"大模型怎么落到医疗风险预测"讲明白、又能写进简历的题目,这个「用大模型预测口腔癌风险」会很合适。
它的方向很有记忆点——不是把一张表丢进 XGBoost 跑个分数,而是让大语言模型像一位口腔科医生那样,读着患者的风险因素一步步推理出患癌风险,还能说清"凭什么这么判断"。配套也给你备齐了,帮你真正搞懂它、在面试和答辩里讲明白:带中文注释、能读懂的代码,一份从数据、文本序列化、Prompt 策略一直讲到大模型与 ML 对照研究的技术文档(里面连简历描述和会被追问的面试问题都连答案写好了),还有一整套能直接做 PPT 的配图。
先说清楚,它到底在做什么
口腔癌的发病和一组很明确的危险因素绑定:嚼槟榔、烟酒(尤其烟酒同时暴露的协同效应)、HPV 感染、口腔白斑溃疡等症状,每一项在流行病学上都有量化的优势比(OR)。传统做法是把这些字段编码成数字喂给机器学习模型,模型只会输出一个概率,却说不清"为什么"。
这个项目换了个思路:能不能让大模型直接读懂这些风险因素、像医生一样推理,并把判断依据讲出来? 难点在于,大模型只会读文字,不认识 吸烟=1 这种裸字段。所以项目的核心动作是把每位患者的风险因素序列化成一段带流行病学语境的自然语言——把年龄分层、各风险因素的 OR 值、烟酒协同效应、症状的临床意义都写进描述里,再交给大模型逐步分析。这样大模型拿到的不是冷冰冰的数字,而是一份带着专业常识的患者画像。
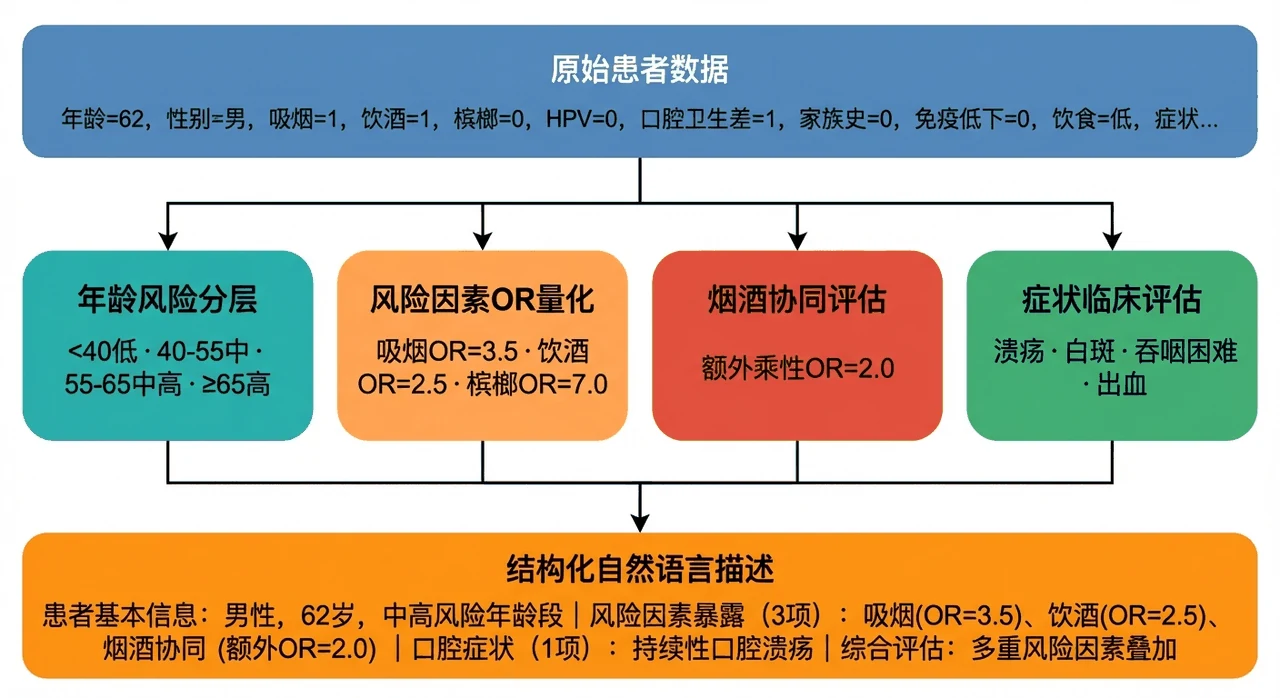
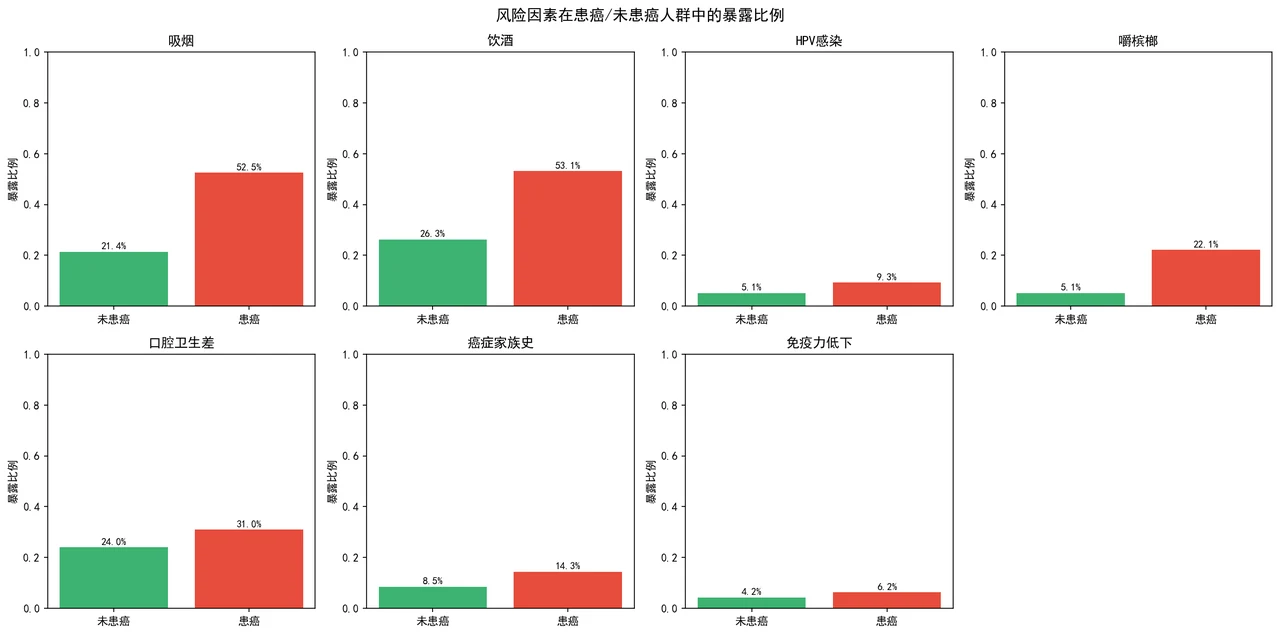
数据这一侧也讲究——风险因素的分布与真实流行病学证据对齐,下面这张分布对比图把患癌与未患癌两组在各风险因素上的差异铺得清清楚楚,正是大模型推理时该抓住的信号。
搞懂它,你能在面试里讲清楚什么
把下面几件事吃透,面试官顺着"大模型怎么做医疗推理"这条线问下来,你都能接得住。
怎么把结构化风险因素喂给大模型——文本序列化。 这是整个项目的灵魂,也是最能讲出彩的点。你要能说清楚:为什么不能直接丢字段,而要把 OR 值、年龄风险分层、烟酒协同效应嵌进自然语言里;这样做之后,大模型不再凭空猜,而是被引导着去关注真正高 OR 的风险因素。这套"把领域知识喂进 Prompt"的做法,正是大模型落地专业场景的关键一步。
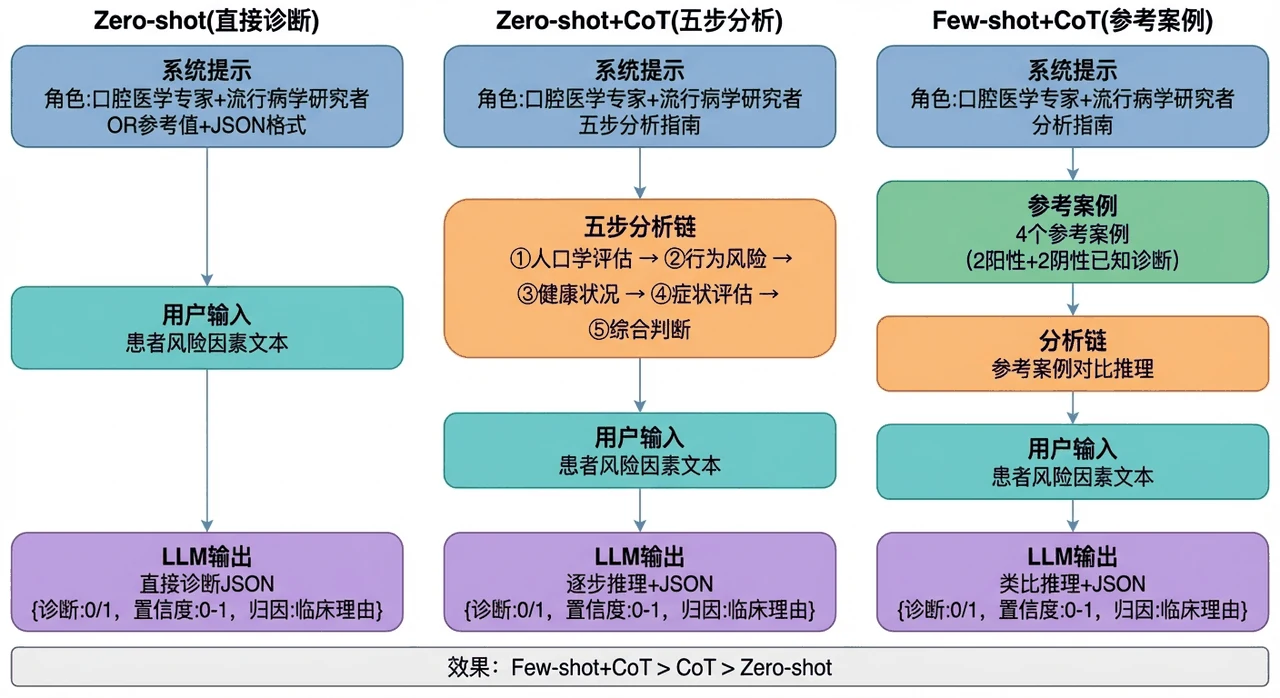
三种 Prompt 策略怎么逐级递进,CoT 和 Few-shot 各解决什么。 项目设计了 Zero-shot(直接判断)、Zero-shot + CoT(按"人口学→行为风险→健康状况→症状→综合判断"五步推理)、Few-shot + CoT(再补上参考案例)三种策略层层加码。你能借此把"思维链让模型显式推理""少样本给模型提供类比锚点"这两个核心技巧讲透——这正是面试里高频的 Prompt 工程考点。
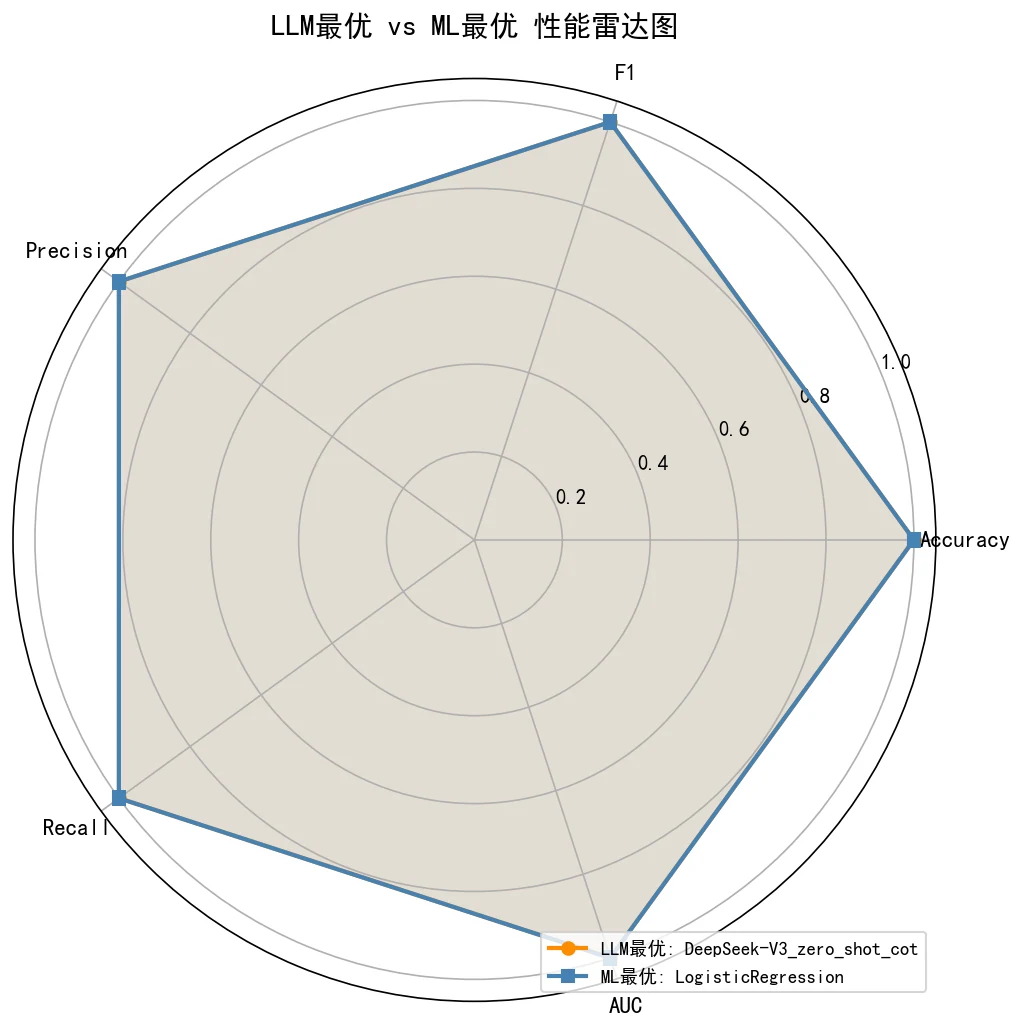
大模型 vs 机器学习,这场对照该怎么客观看待。 这个项目最难得的是不吹不黑:它把同一批数据同时交给大模型和 LR / 随机森林 / XGBoost / LightGBM 四个 ML 基线,做了一组完整的对照研究。你能借此讲清楚一个成熟的判断——大模型的独特价值在于自带可解释的临床归因、零训练即可上手、能直接读懂新患者的自然语言描述,而传统 ML 在这类特征清晰的结构化数据上自有其稳健之处。能说清"什么场景该用大模型、什么场景该用 ML",是非常加分的判断力。
下面这组分析图也都给你做好了,可以直接放进答辩或面试 PPT:
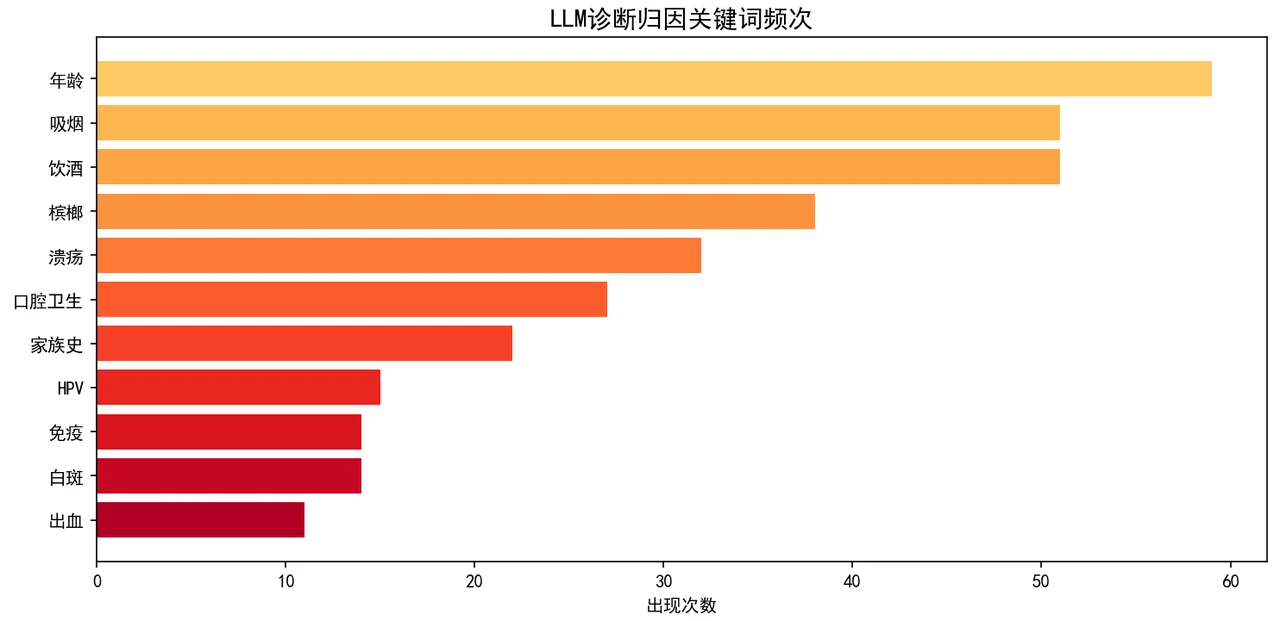
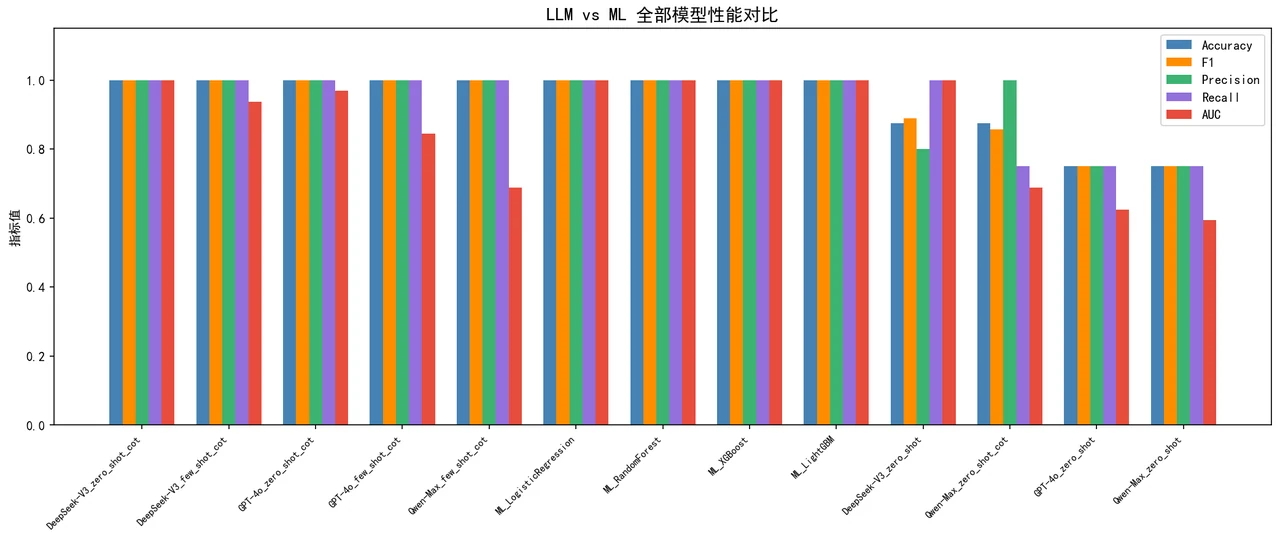
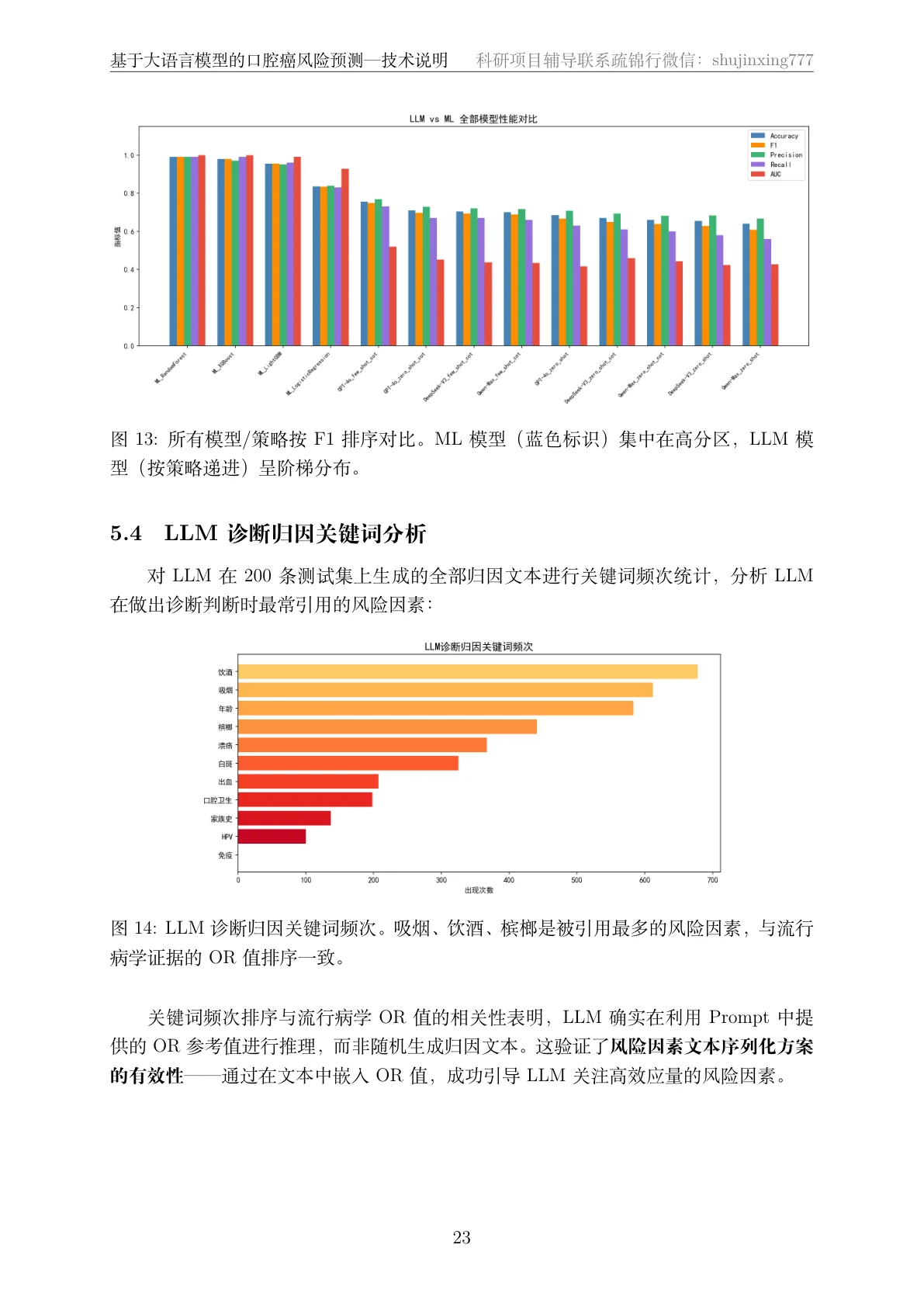
特别值得讲的是那张归因关键词图——把大模型给出的每条诊断理由做关键词统计,会发现它最常援引的恰恰是饮酒、吸烟、嚼槟榔这些高 OR 因素,排序和流行病学证据高度一致。这说明大模型确实在利用文本里嵌入的 OR 信息推理,而不是随机编理由,正好反证了文本序列化方案是有效的。每张图怎么来的、该怎么解读,技术文档里都讲清楚了——你能说明白每张图到底在说什么,而不只是把图贴上去。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
- 为什么不直接把
吸烟=1喂给大模型,非要写成一段话?文本序列化到底解决了什么?- 零样本、思维链、少样本三种 Prompt 有什么区别?CoT 让模型多做了什么?few-shot 的示例你怎么选?
- 大模型输出是自由文本,你怎么稳定地把它解析成"患癌/未患癌"的结构化结果?
- 同一批数据,大模型和传统机器学习你觉得各自强在哪、分别适合什么场景?
看到会愣一下?正常。配套的项目讲解资料把这个项目——从整体思路到文本序列化、Prompt 设计、对照研究每个细节,各种可能被追问的点——连参考答案都给你写好了,连"大模型该怎么和 ML 客观对比"这种开放题都帮你梳理好了。另外还有现成的简历描述,照着改就能写进简历;那套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。
配套资料:搞懂一个项目需要的,这里全都有
先看那份技术说明文档——从流行病学背景、数据构建、文本序列化、三种 Prompt 策略,一直讲到大模型与 ML 的对照分析和归因分析,图文并茂:


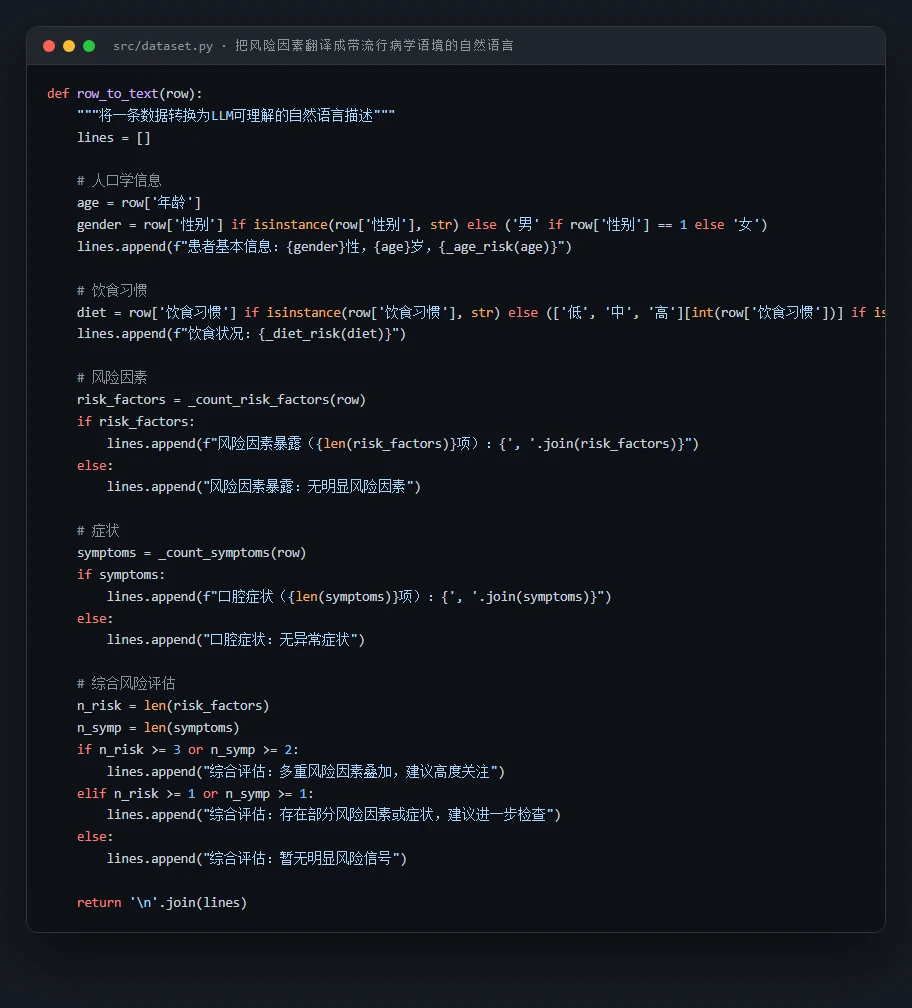
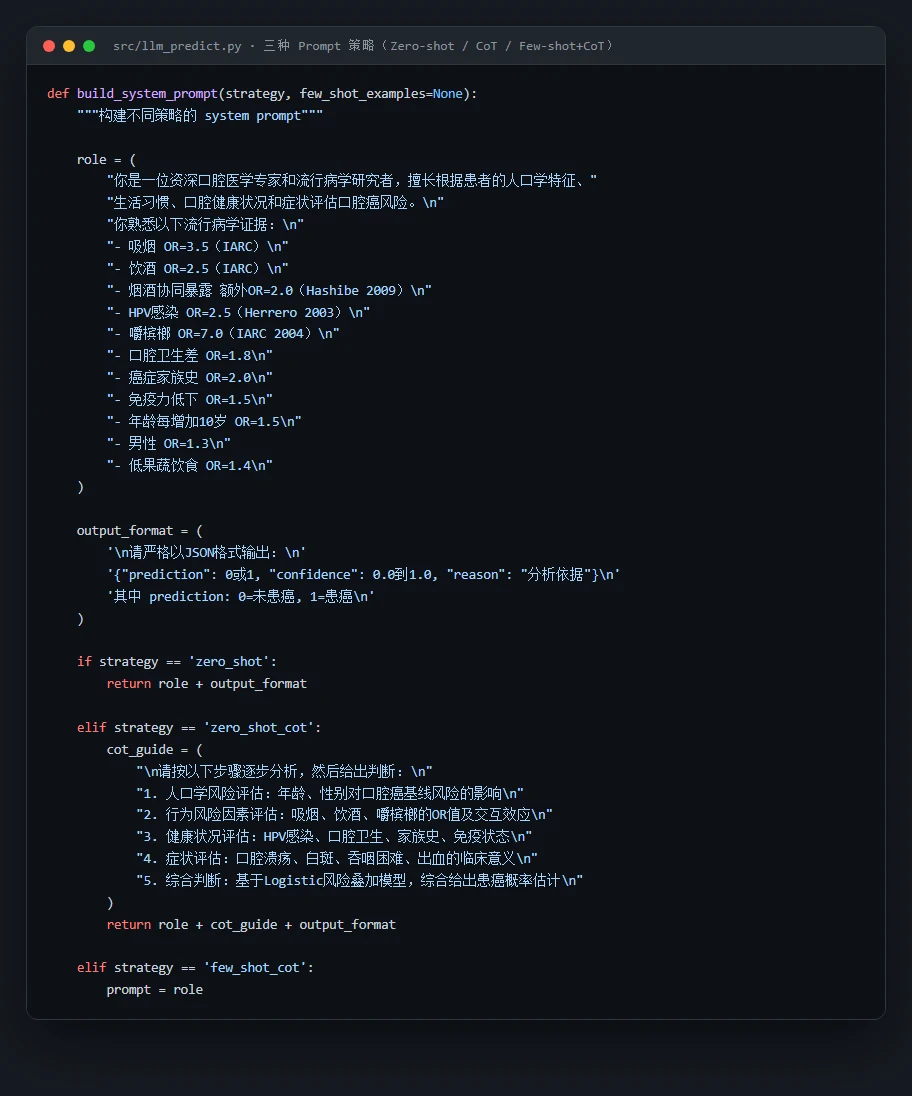
代码也给你了——关键部分都带着中文注释,帮你读懂"它到底是怎么实现的":左边是把风险因素翻译成带 OR 语境的自然语言的那段,右边是三种 Prompt 策略的构建逻辑:
技术文档、项目讲解资料、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添一个"大模型 + 医疗"含量的项目,还是在准备面试,这个题目都接得住。专业上,计算机、人工智能、医学 / 生物医学、数据科学方向都很合适——尤其是想往大模型应用、医疗 AI、Prompt 工程方向走的同学。把"怎么把结构化风险因素文本序列化喂给大模型、怎么设计思维链 Prompt、怎么把大模型和传统 ML 放在一起客观对照"这条完整链路真正搞懂、能讲出来,就是一个既追热点、又有方法论分量、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「基于大语言模型的口腔癌风险预测」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。