基于多模态融合的阿尔茨海默病早期筛查系统
把脑 MRI 影像、认知量表、血浆生物标志物、ApoE 基因型四种模态拼成一条 42 维序列,用 ViT 编码影像、Transformer 自注意力做跨模态融合,对 AD / MCI / CN 三分类——还带缺失掩码、MC Dropout 置信度与 LIME 可解释性,代码、文档、讲解资料齐备。
项目亮点
- AD(Alzheimer's Disease,阿尔茨海默病,555人)
- MCI(Mild Cognitive Impairment,轻度认知障碍,1534人)
- CN(Cognitively Normal,认知正常,1199人)
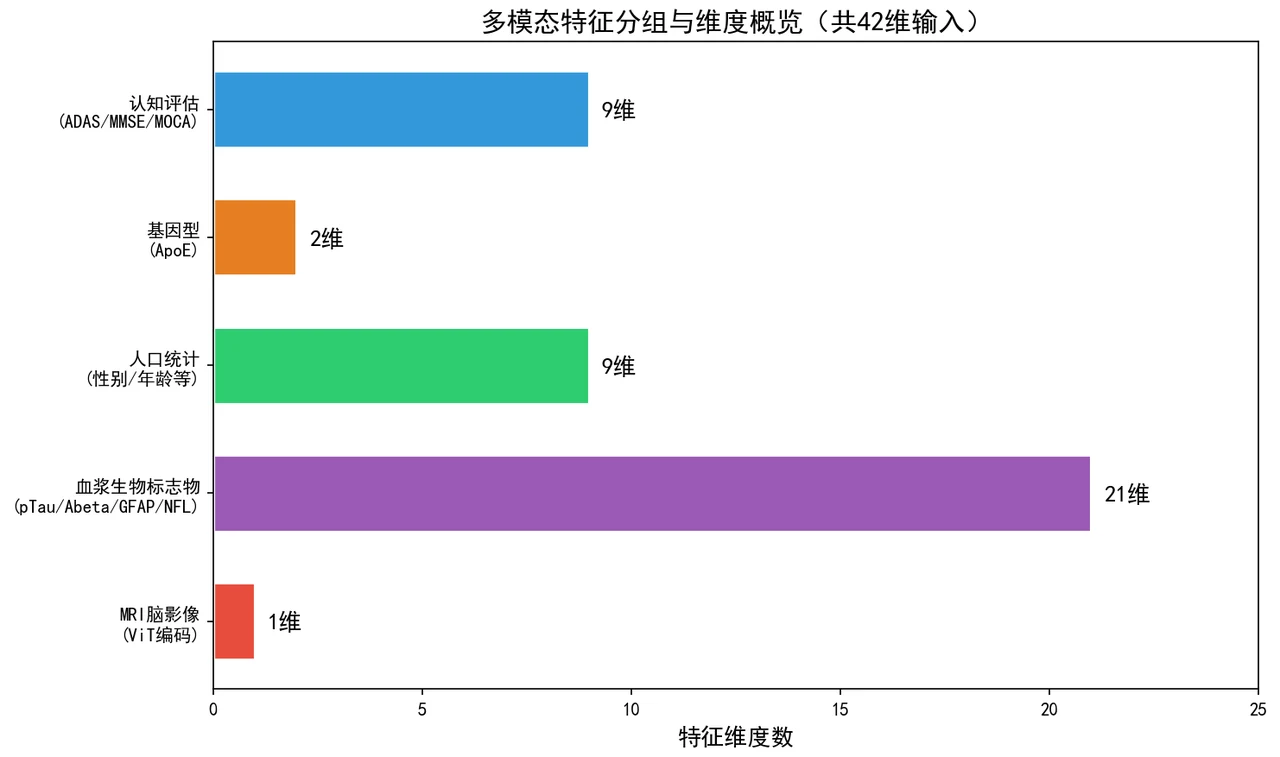
- ApoE基因型分离为两个特征(两个位置的等位基因类型)
数据与任务
| 样本量 | ADNI · 3288 名被试 · 42 维 |
|---|---|
| 核心方法 | ViT + Transformer 多模态融合 |
| 技术栈 | PyTorch · transformers · LIME |
如果你想找一个有分量、又能在面试和答辩里讲透的 AI 项目,这个「多模态融合 + Transformer 做阿尔茨海默病早期筛查」很合适。
它把医疗影像、深度学习和多模态融合放在一起,听起来很有门槛,但配套都给你备齐了,帮你真正搞懂它、在面试里讲明白:带中文注释、读得懂的代码,一份从数据到模型、结果、可解释性都讲清楚的技术说明文档,里面连简历项目描述和面试问答都写好了,还有一整套能直接做 PPT 的配图。
先说清楚,它到底在做什么
阿尔茨海默病的难点在于"早"——真正有价值的是在轻度认知障碍(MCI)阶段就把人筛出来。可单看任何一种检查都不够:MRI 看脑结构,认知量表测记忆与判断,血浆里的 pTau、Aβ、GFAP 反映病理,ApoE 基因型则提示风险。临床医生本来就是把这些放在一起综合判断的,难点在于怎么让模型也学会这种"跨模态综合",而且现实数据里经常某几项是缺的。
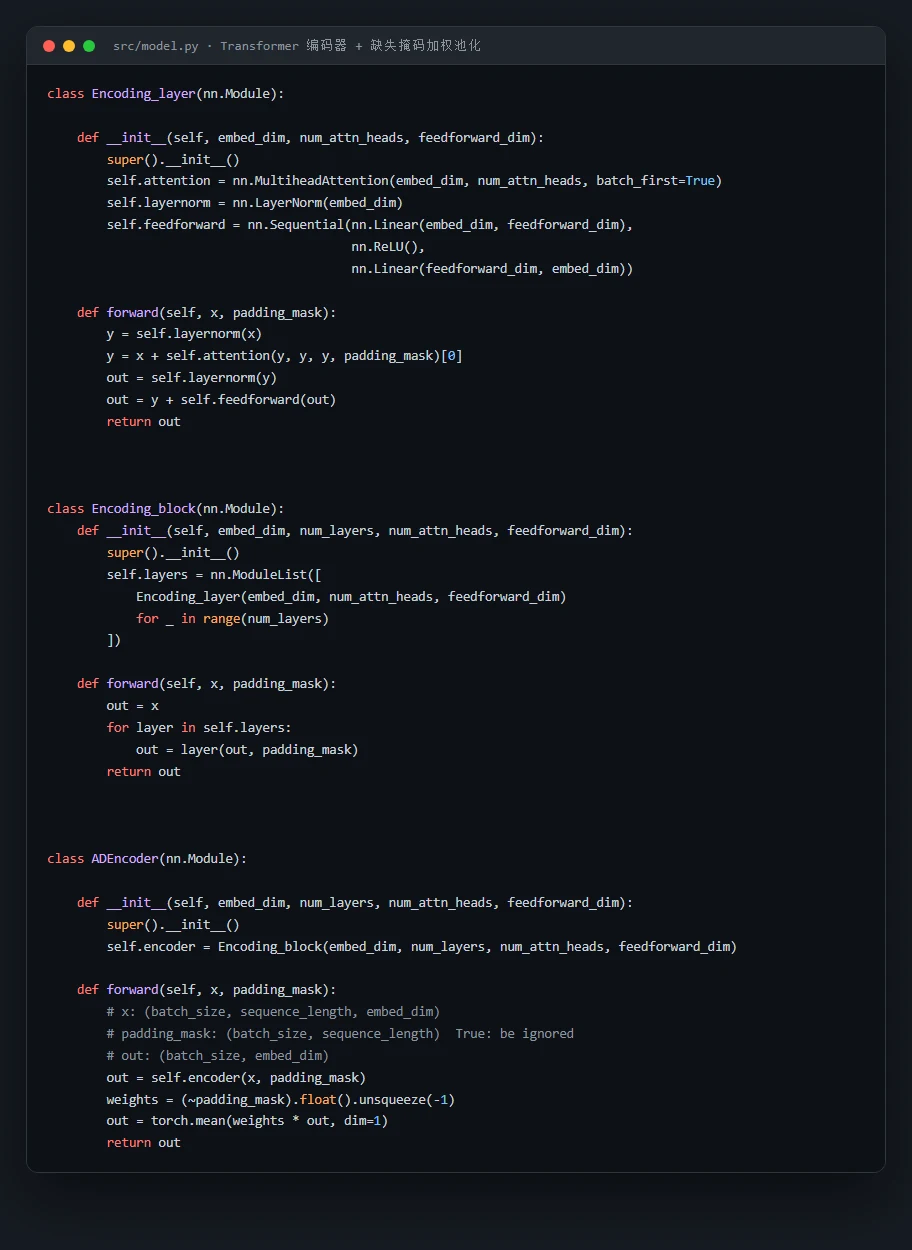
这个项目基于公开的 ADNI 数据集,把四类模态统一成一条序列来处理:MRI 经 ViT 预训练编码器抽成一个影像 token,认知量表、生物标志物、ApoE、人口统计学等表格特征每一维各自嵌入成一个 token,最终拼成 42 个 token 的序列喂给 Transformer,靠自注意力让各模态信息互相参照、融合,最后对 AD / MCI / CN 做三分类。
搞懂它,你能在面试里讲清楚什么
把下面几件事吃透,面试官顺着多模态、Transformer 这两条线追问下来,你都能接得住。
为什么用 Transformer 来做多模态融合,而不是简单拼接。 这是项目的核心立意。你要能讲清楚:把每个模态、每一维特征都当成一个 token,自注意力就能让"影像异常"和"pTau 升高""MMSE 偏低"这些来自不同模态的线索互相加权、彼此印证,比把特征直接 concat 再过全连接更能学到跨模态关系。
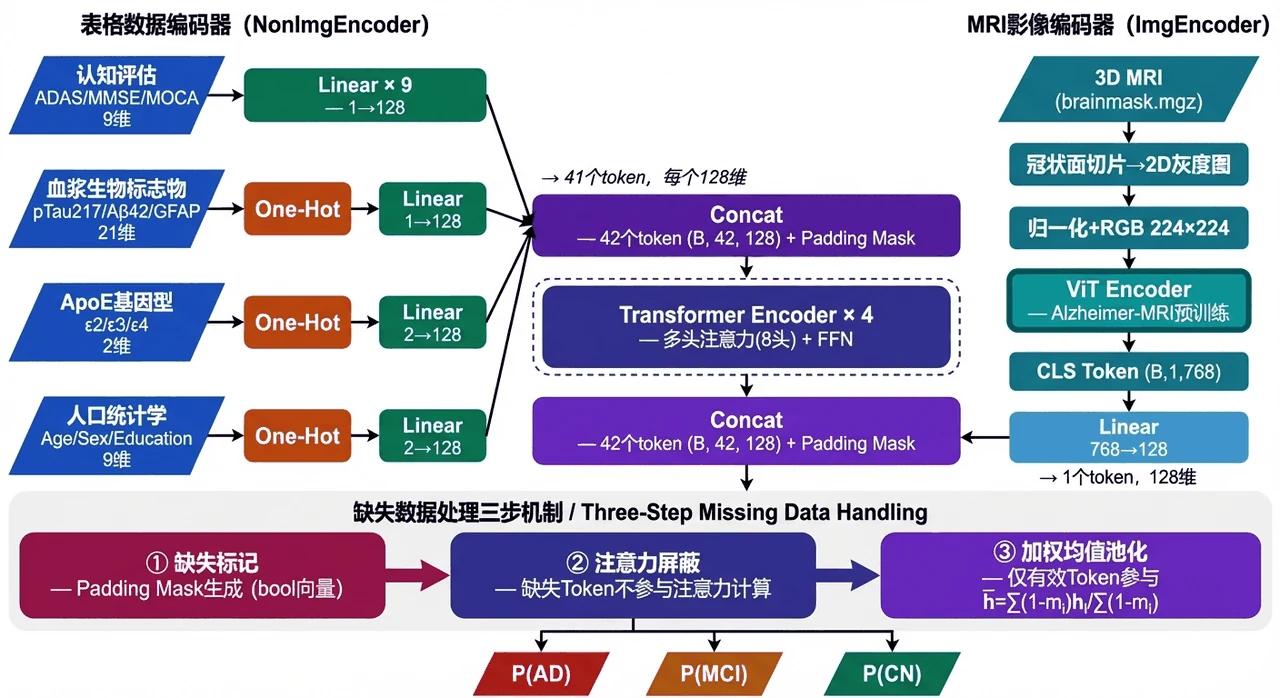
缺失模态怎么办——Padding Mask 是怎么设计的。 真实医疗数据里 MRI 或某些量表常常缺失。项目没有简单丢样本或硬填零,而是给缺失的 token 打上掩码,在多头注意力里屏蔽掉、加权池化时也只让有效 token 参与,从而把"只有部分模态"的被试也用起来。这一点是面试里最能体现工程考量的细节。
注意力到底学到了什么。 把 Transformer 的注意力权重画成热力图,能看出模型在判断时更看重哪些特征、哪些模态之间互相关注——让"黑盒"变得能解释,也呼应了医学场景对可信度的要求。
下面这组分析图也都给你做好了,可以直接放进答辩或面试 PPT:
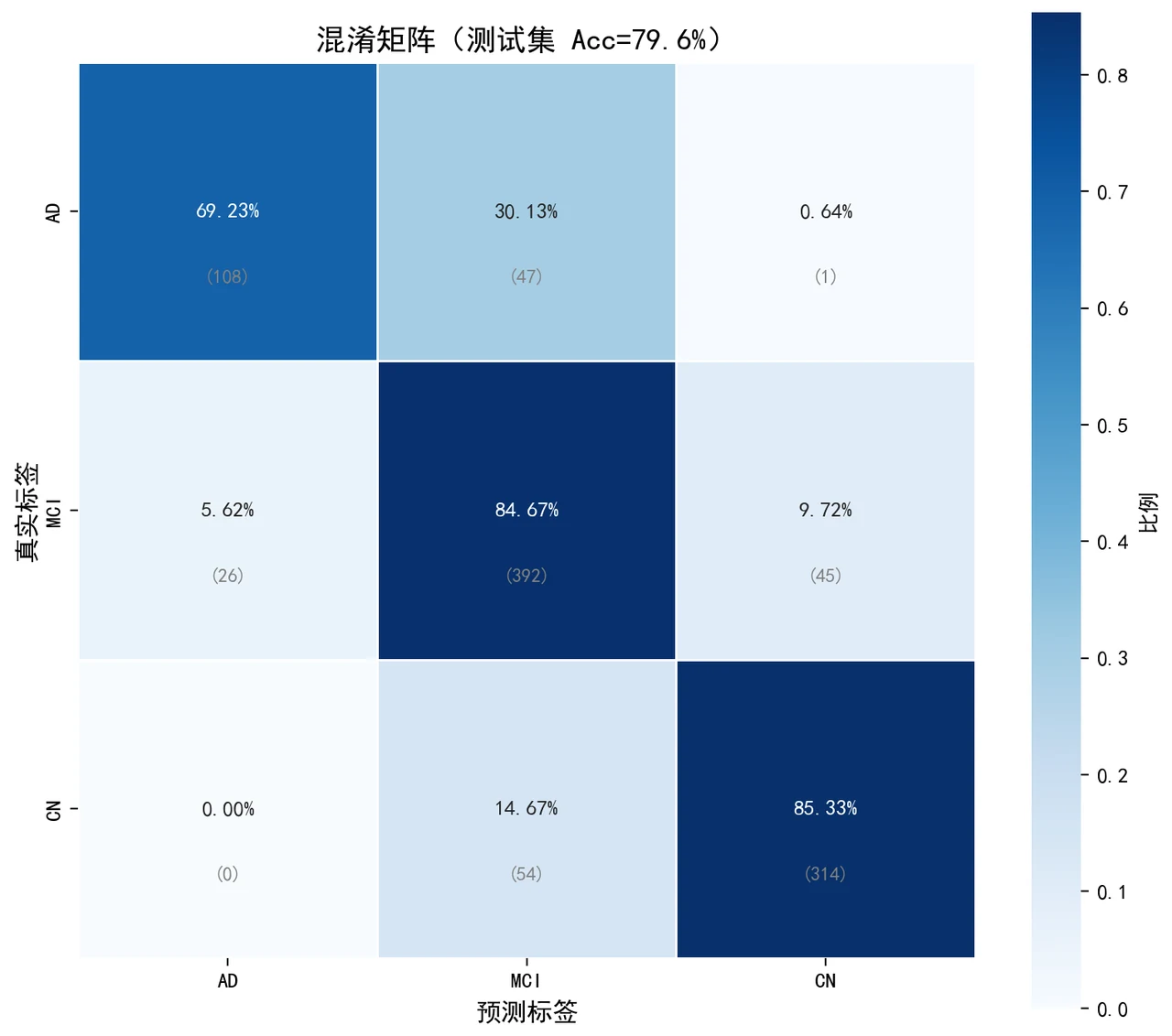
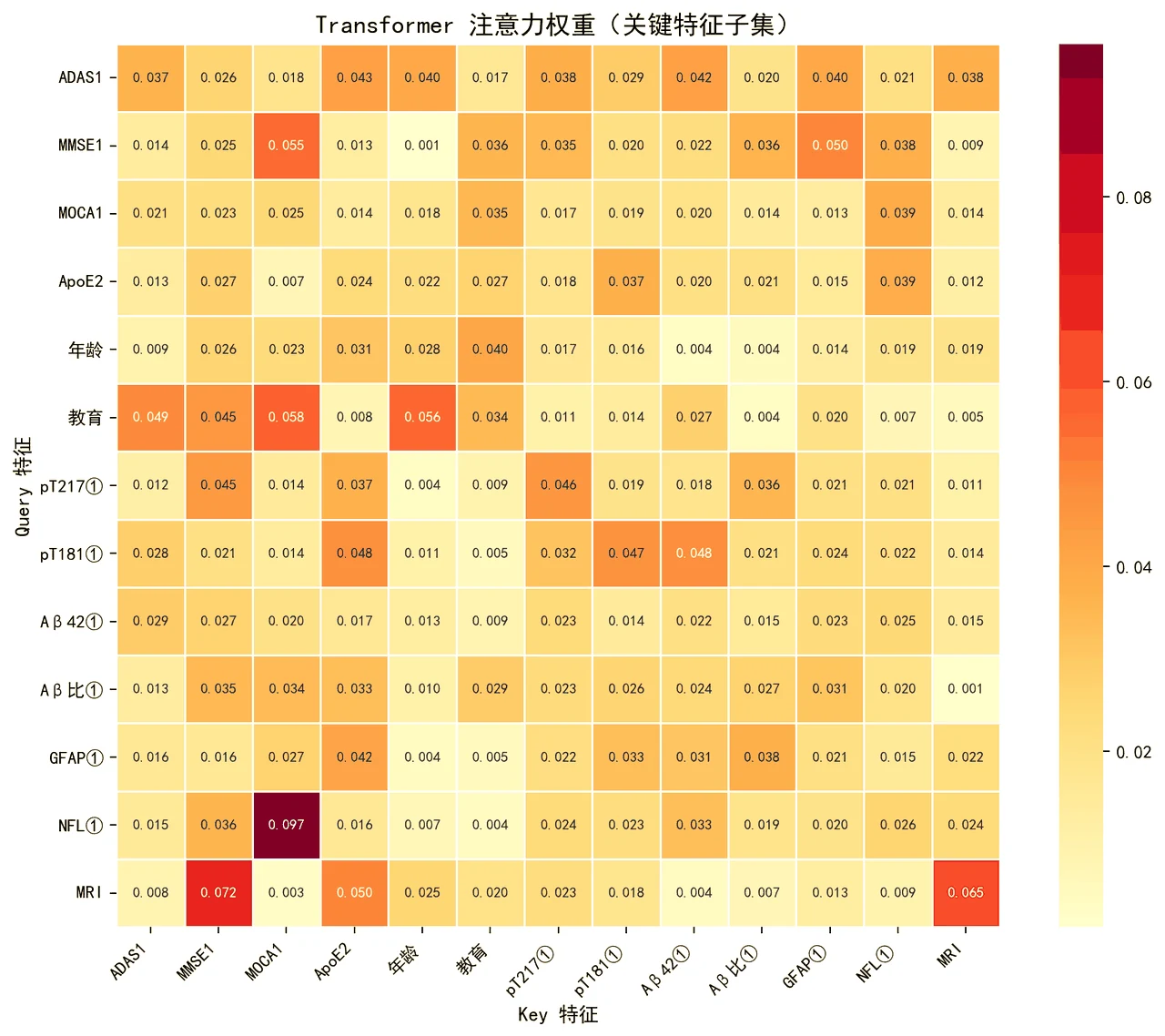
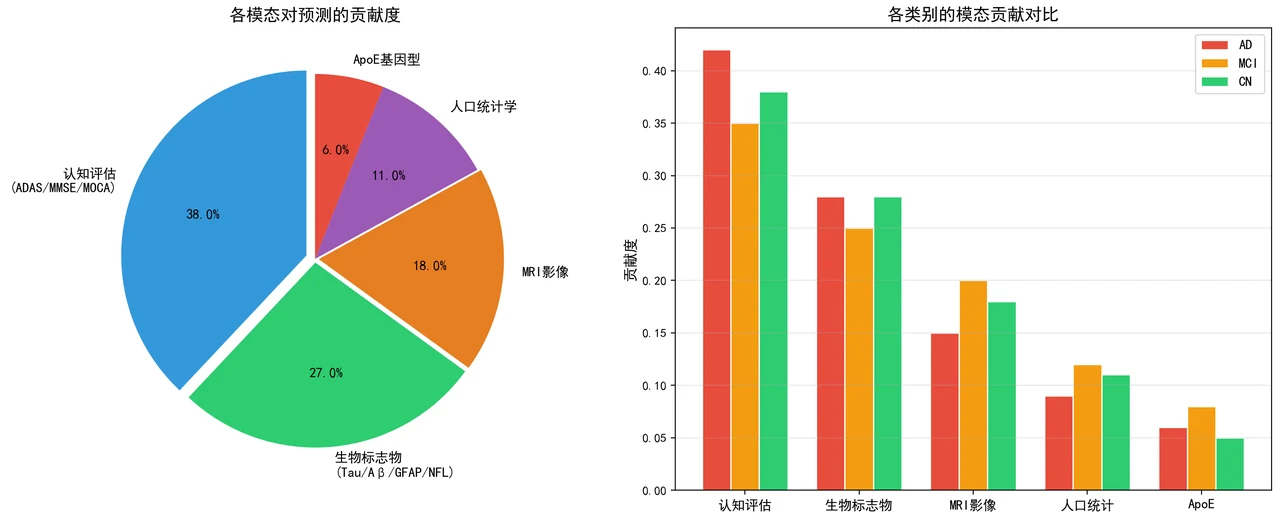
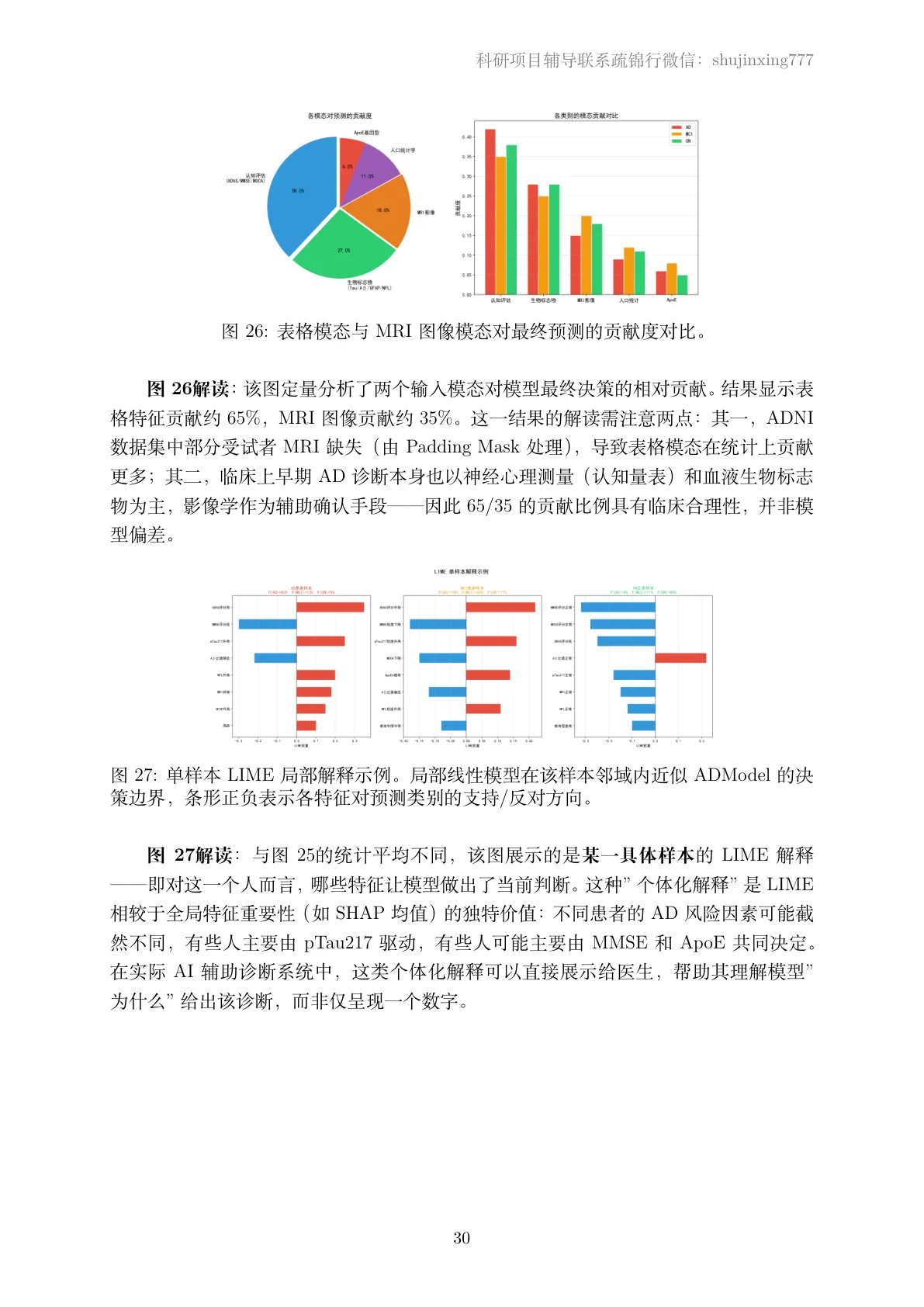
更关键的是,每张图怎么来的、该怎么解读,技术文档里都写清楚了——比如模态贡献度为什么是认知量表与生物标志物为主、影像作辅助确认,文档里给的是临床上的合理解释,而不是一句空话。你能照着把每张图说明白。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
- 为什么把每一维特征都当成一个 token,而不是把表格特征拼成一个向量再融合?
- Padding Mask 是怎么让缺失模态的样本也能参与训练的?
- MC Dropout 是怎么给出置信度的?它和模型直接输出的 Softmax 概率有什么区别?
看到会愣一下?正常。配套的项目讲解资料把这个项目——从整体思路到每个流程细节、各种可能被追问的点——连参考答案都写好了。里面还有现成的简历项目描述,照着改就能写进简历;那套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。
配套资料:搞懂一个项目需要的,这里全都有
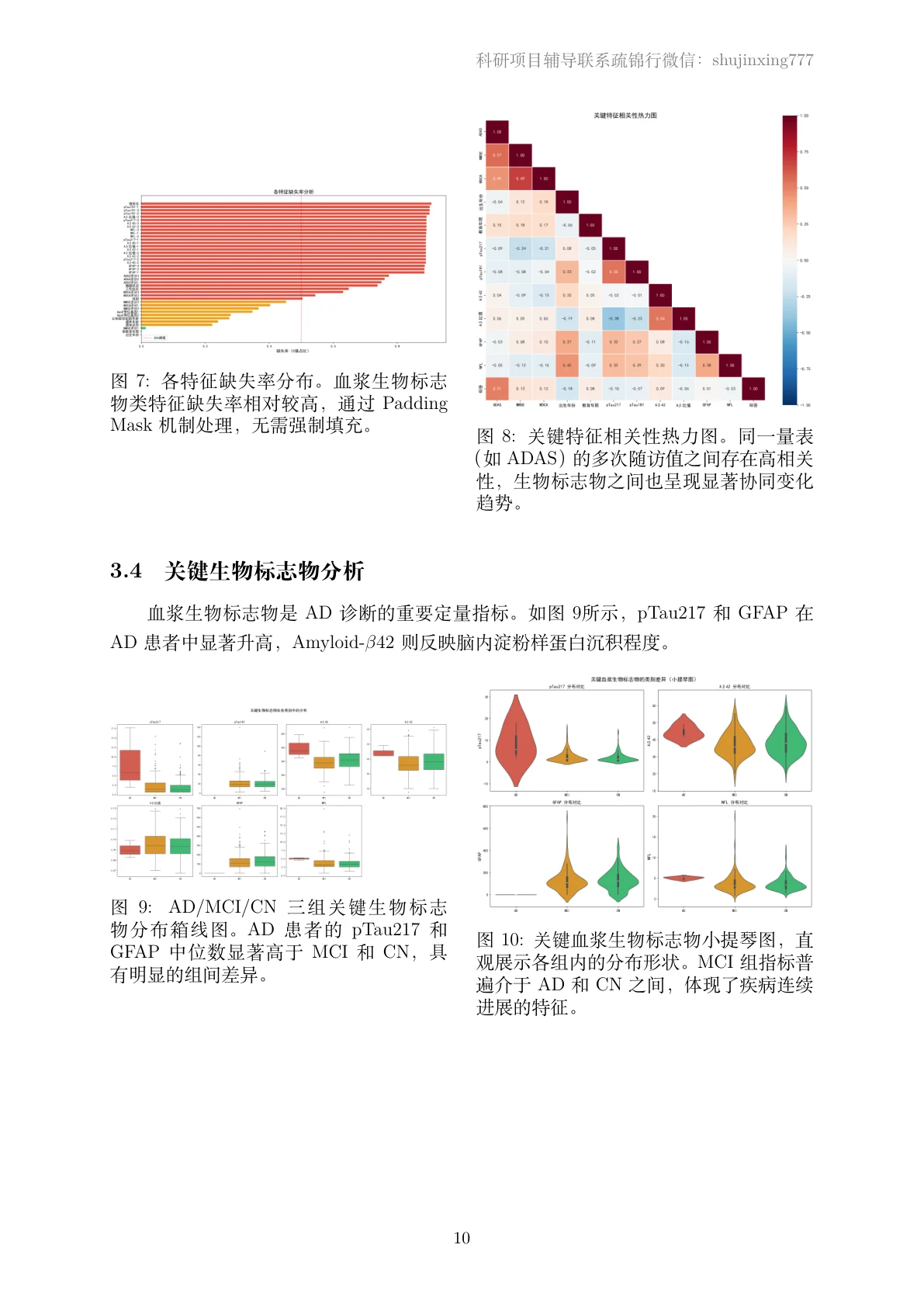
先看那份技术说明文档——从数据来源、多模态预处理,一直讲到模型结构、训练、结果与 LIME 可解释性,图文并茂:

代码也给你了——关键部分都带着中文注释,帮你读懂"多模态融合到底是怎么实现的":
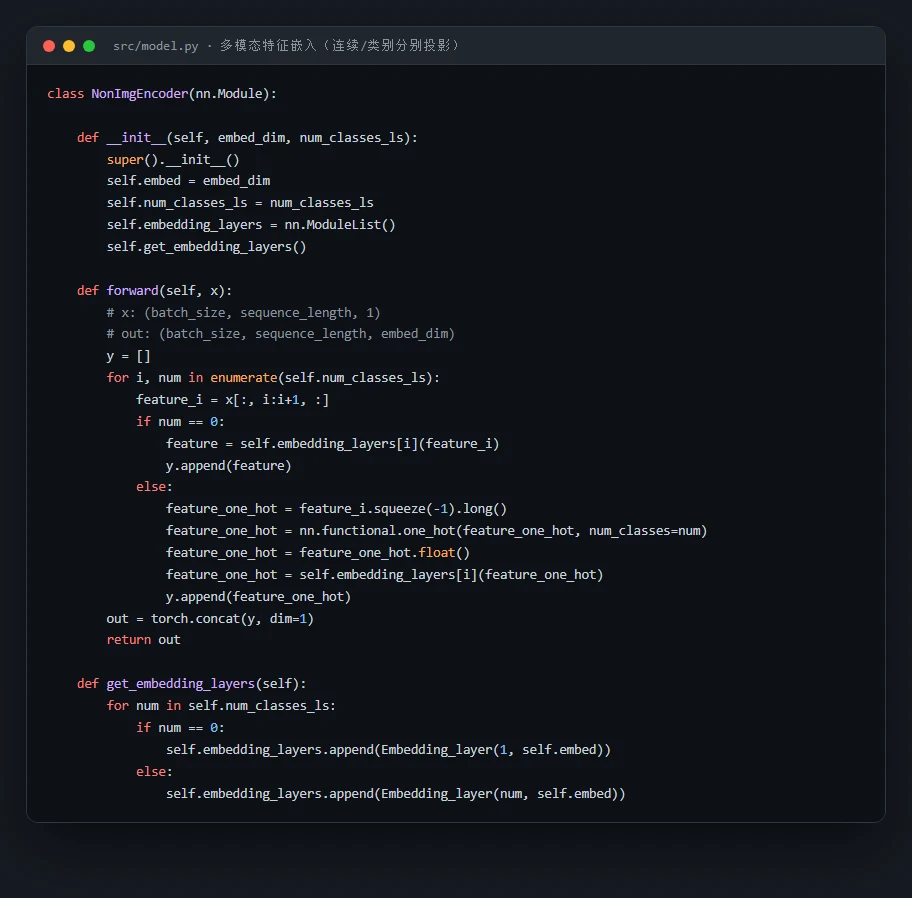
技术文档、项目讲解资料、源码注释、整套配图——搞懂这个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添一个有分量的 AI 项目,还是在准备面试,这个题目都接得住。专业上,计算机、人工智能、软件工程、生物医学工程、数据科学方向都很合适。多模态融合与 Transformer 是当下最有热度的方向,再叠加医疗这个有故事、有意义的场景——把这条从数据到模型、再到可解释性的完整链路真正搞懂、能讲出来,就是一个能写进简历、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「基于多模态融合的阿尔茨海默病早期筛查系统」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。