基于推荐系统的电影个性化推荐与用户画像分析
一套完整的电影个性化推荐系统,打通「召回—排序—评估—画像」全链路。用矩阵分解、协同过滤等四类模型对比,讲透推荐系统最重要的一课:评分预测准,不等于推荐排序好。配套带注释代码、技术文档、面试问答与整套配图。
项目亮点
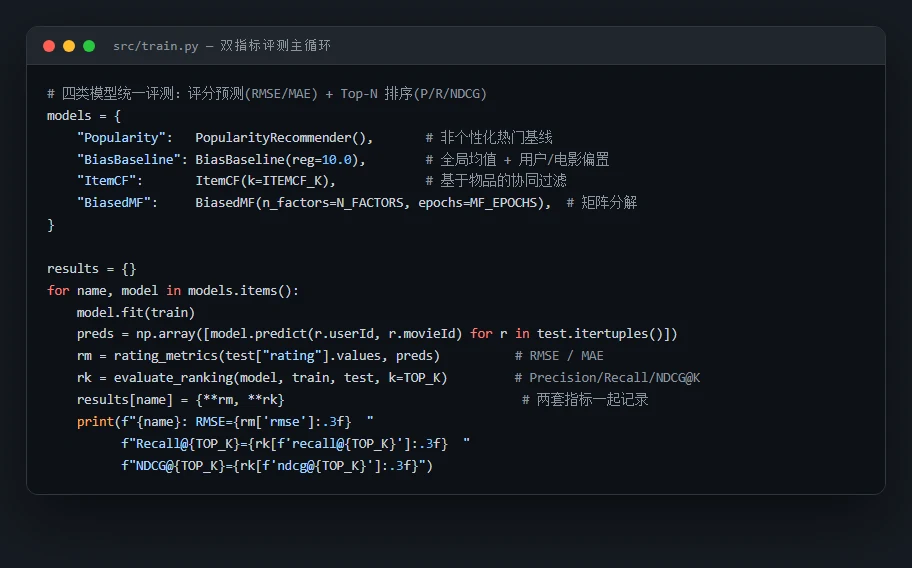
- Popularity:非个性化热门基线。
- BiasBaseline:μ + 用户偏置 + 物品偏置。
- ItemCF:基于物品的协同过滤(余弦相似度 + 用户均值中心化)。
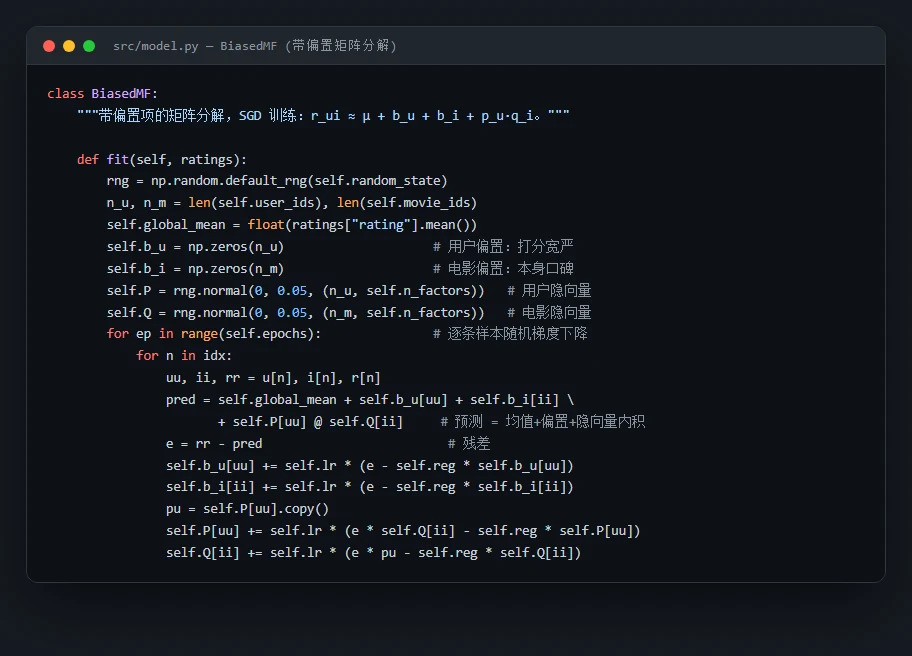
- BiasedMF:带偏置矩阵分解,SGD 训练(k=50, 30 轮)。
如果你正在找一个能写进简历、面试时又能讲清楚的 AI 项目,这个「做一套电影推荐系统」的题目会很合适——它就是抖音、淘宝、Netflix 背后那套「猜你喜欢」的简化版,方向热门、人人都用过,讲起来天然有共鸣。
更难得的是,它不是只跑一个模型交差,而是把一套推荐系统从头到尾完整地搭了起来:怎么从上万部电影里召回候选、怎么排序、怎么评估好坏、怎么刻画用户兴趣画像。配套也都给你备齐了,帮你真正搞懂它、在面试和答辩里讲明白:带中文注释、能读懂的代码,一份图文并茂的技术文档,一份把面试问题连答案都写好的问答文档,还有一整套能直接做 PPT 的配图。
先说清楚,它到底在做什么
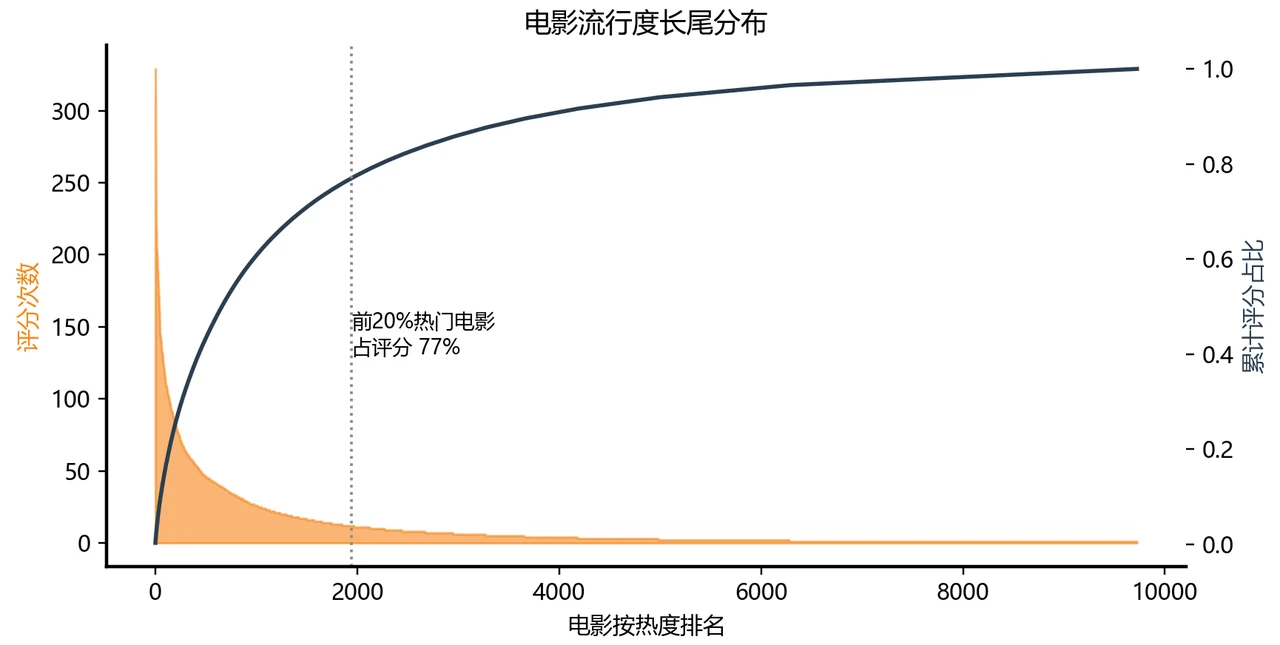
推荐系统要解决的是「信息过载」——电影有上万部,但用户耐心只够看十几个。系统的活儿,就是从海量物品里挑出这个人最可能喜欢的那几个,放到「猜你喜欢」里。难点在于:每个用户只看过、只评过其中极少数电影,绝大多数格子都是空的(数据极度稀疏),得靠这点零星线索去猜他对没看过的片子的态度。
这个项目用的是经典的 MovieLens 数据(约 10 万条评分、610 个用户、9700 多部电影),思路是层层递进地搭四类模型:先用谁都能想到的「推热门」打底,再加上「用户打分宽严 + 电影本身口碑」的偏置基线,然后上「物品协同过滤」(看过这部的人还爱看哪部),最后是推荐系统的现代主力「带偏置的矩阵分解」——把每个用户和每部电影都压成一串隐向量,用向量的匹配度去预测评分。
搞懂它,你能在面试里讲清楚什么
这才是这个项目对你最大的价值。把下面几件事吃透,面试官问到推荐系统,你都能从容答上来。
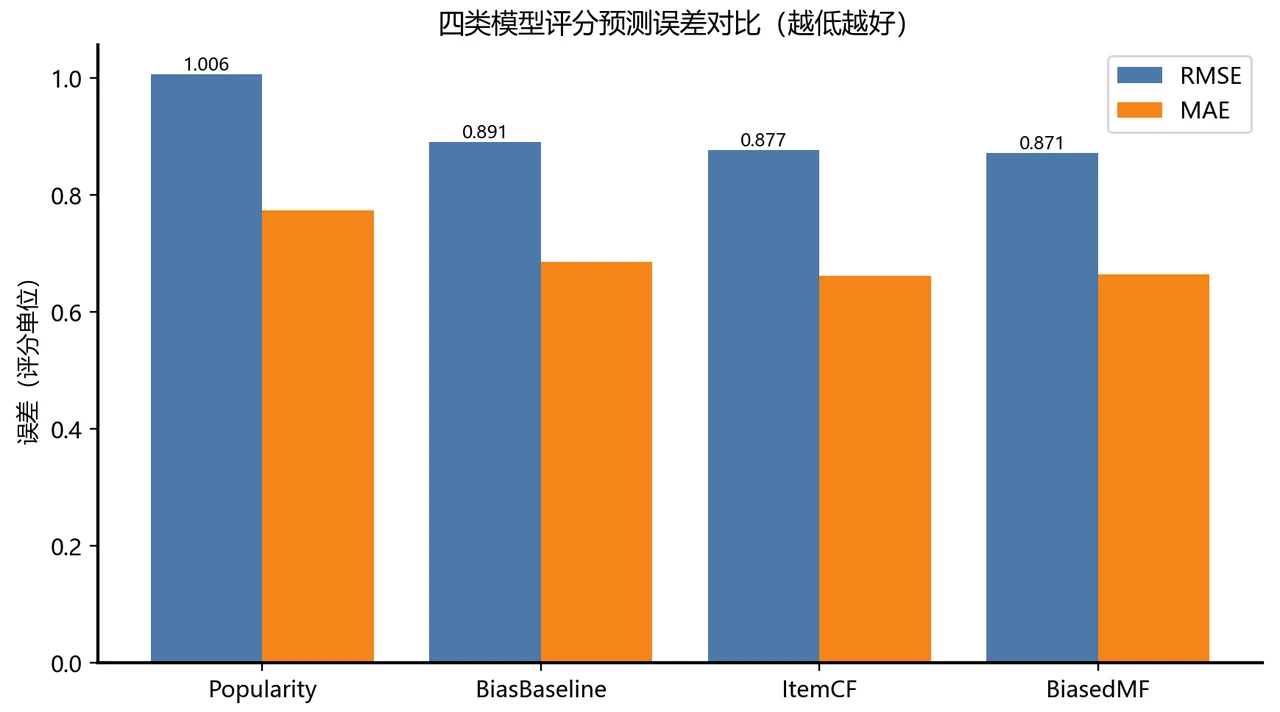
最出彩的一课:评分预测准,不等于推荐排序好。 这是整个项目的灵魂,也是最能体现你「想得比别人深」的地方。项目同时量了两套指标:一套是「评分预测」准不准(RMSE / MAE,预测分和真实分差多少),一套是「排序」好不好(Precision / Recall / NDCG,真正推给用户的 Top-N 命中没有)。结果出人意料——矩阵分解把评分预测做到了最准(RMSE 0.871),但在真正决定体验的 Top-N 排序上,最朴素的「推热门」反而赢了。 这不是模型不行,而是它精准地暴露了一个推荐系统的核心真相:评分预测和排序是两个不同的目标,只盯着 RMSE 调模型,会把方向带偏。 你能把这个讲透,面试官会记住你。
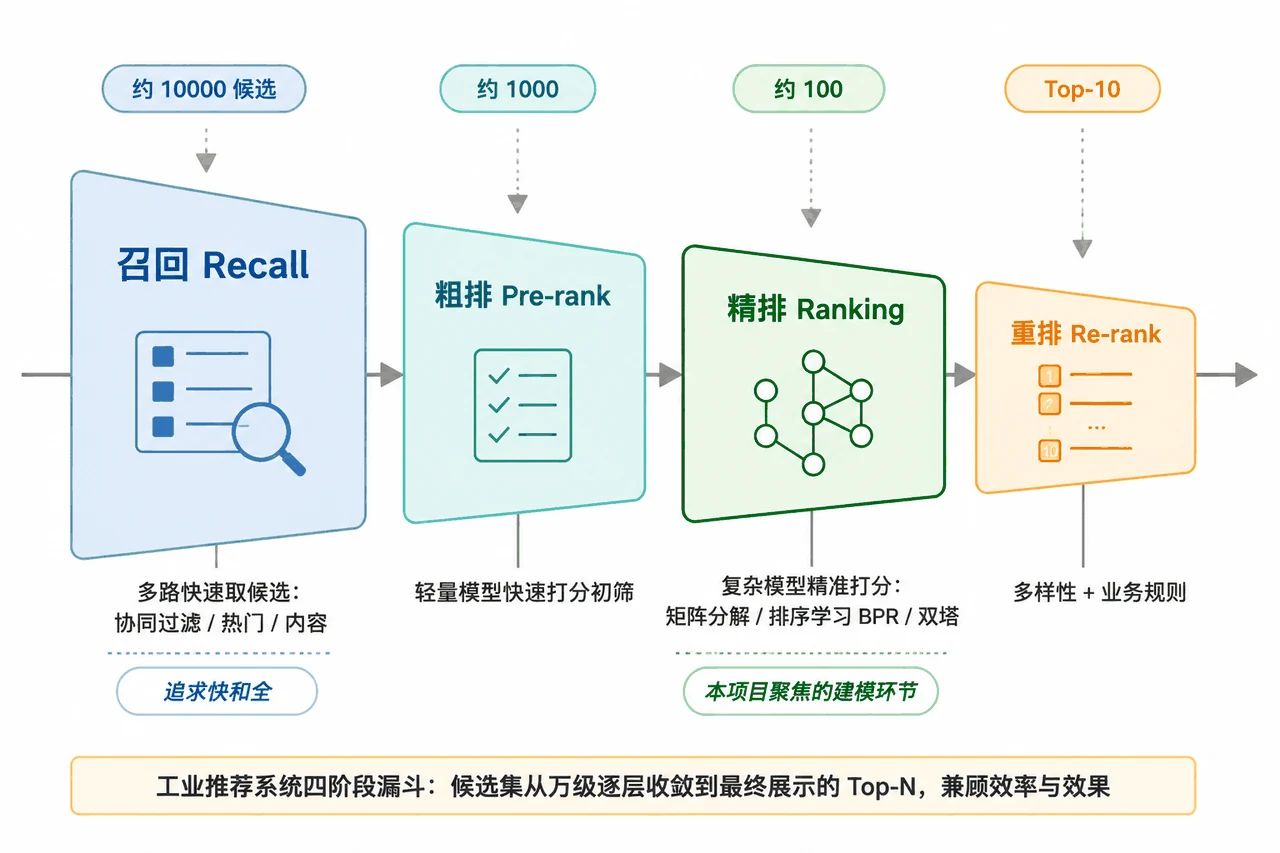
讲清楚召回—排序的工业漏斗,你就跳出了「只会跑模型」的层次。 真实的推荐系统不是一个模型搞定,而是一条流水线:从上万候选里召回一批,粗排初筛,精排用复杂模型精准打分,最后重排兼顾多样性和业务规则。这个项目聚焦的四类模型,正对应工业漏斗里「精排」那一环。能把这张漏斗讲明白,面试官就知道你理解的是整个系统,而不是一个孤立算法。
讲明白矩阵分解的原理,这是推荐系统面试的必考题。 把稀疏的评分矩阵拆成「用户隐向量」和「电影隐向量」两张小表,预测评分 = 全局均值 + 用户偏置 + 电影偏置 + 两个隐向量的内积。为什么加偏置?因为评分里很大一部分来自「这人打分宽不宽」和「这片本身好不好」,跟个性化无关——把它们单独拎出来,隐向量才能专心去学真正的兴趣匹配。这套逻辑配着架构图讲,三句话就能说清。
下面这组分析图也都给你做好了,可以直接放进答辩或面试 PPT:
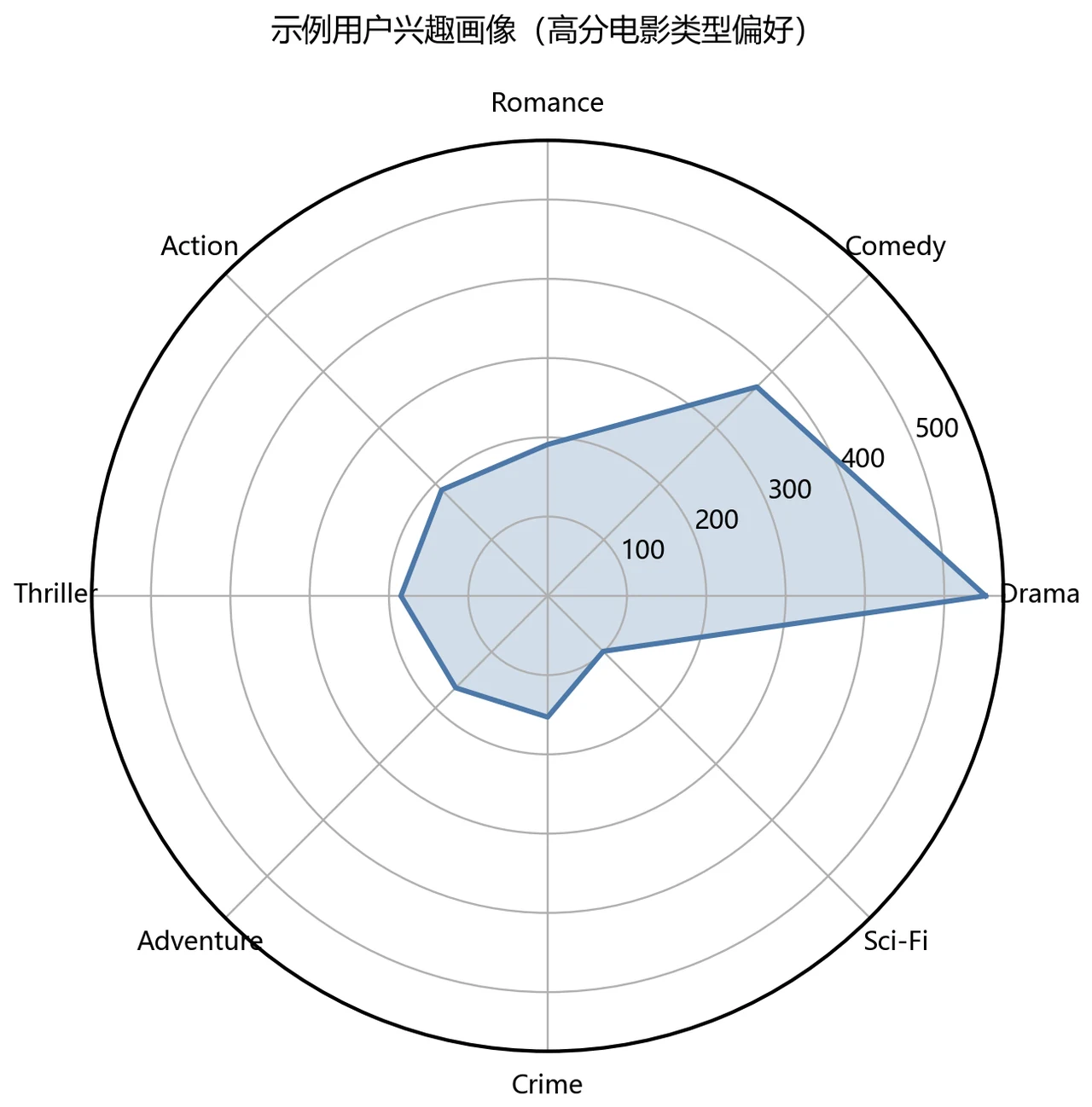
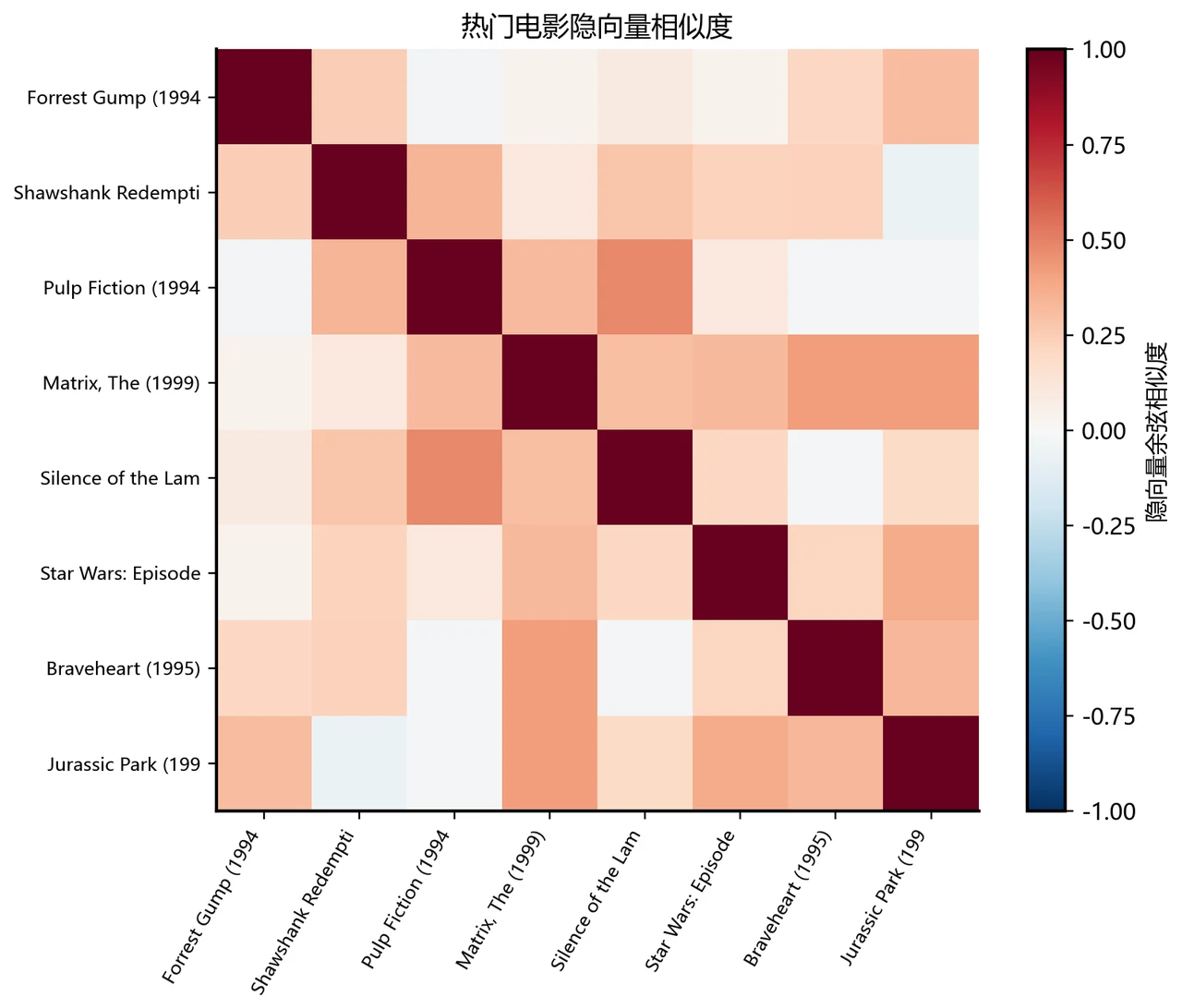
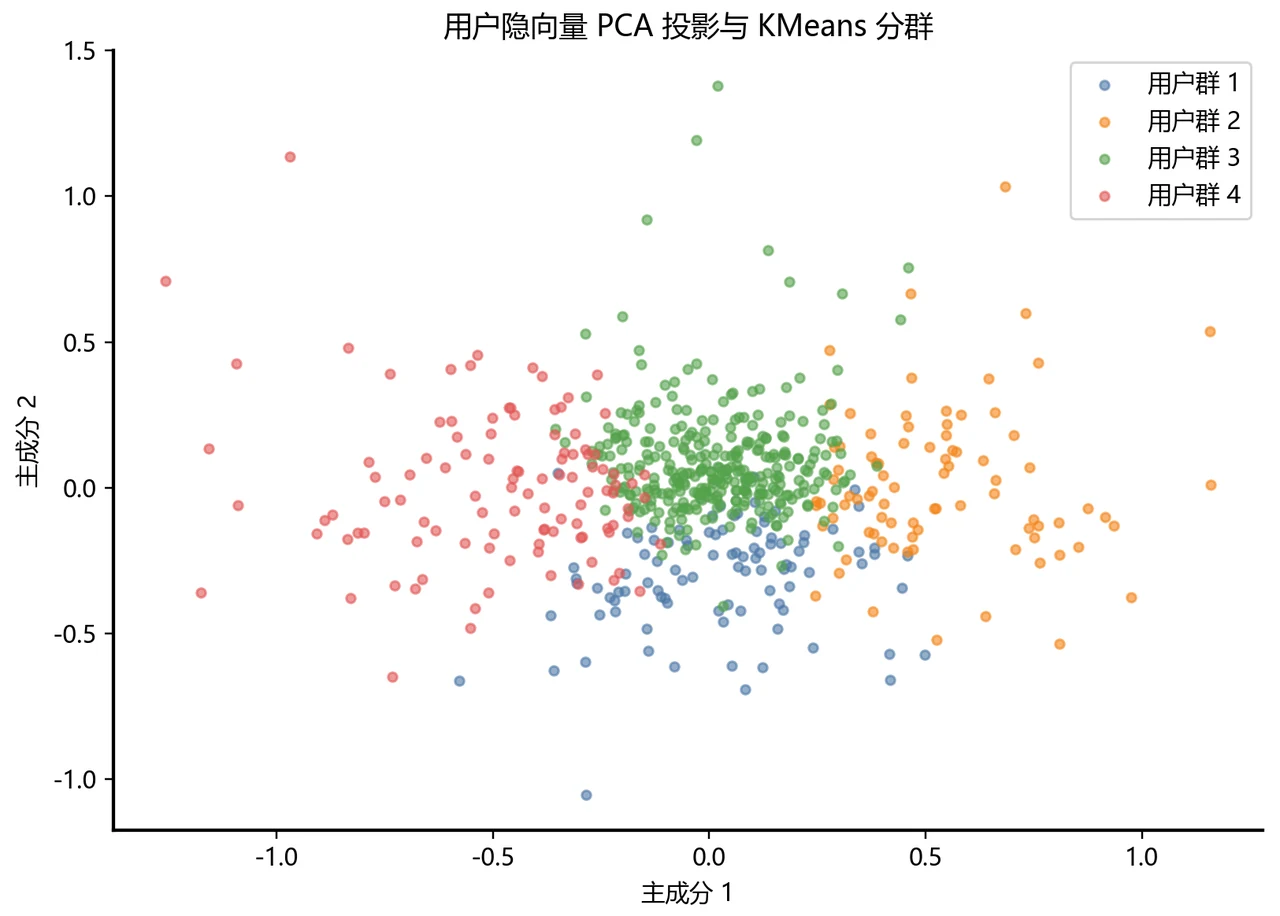
更关键的是,每一张图怎么跑出来的、该怎么解读,技术文档里都讲清楚了——你不是只会往 PPT 上贴图,而是能说明白每张图到底说明了什么。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
- 为什么不能只看 RMSE?评分预测准的模型,推荐效果怎么反而更差?
- 协同过滤和矩阵分解,本质区别在哪?矩阵分解为什么对稀疏数据更扛得住?
- Precision@K、Recall@K、NDCG@K 分别在衡量什么?NDCG 多出来的「位置敏感」是什么意思?
看到这几个是不是会愣一下?正常。配套的面试问答文档把这个项目——从整体思路,到协同过滤、冷启动、长尾、召回排序漏斗这些细节,各种面试可能追问的点——连参考答案都给你写好了。
另外还有现成的简历描述,照着改就能写进简历;那一整套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。你要做的不是背,而是理解,再用自己的话讲一遍。
配套资料:搞懂一个项目需要的,这里全都有
先看那份技术文档——从业务背景、数据探索,一直讲到四类模型怎么搭、双指标怎么算、「评分≠排序」这个核心结论怎么来的,图文并茂,帮你把原理从头吃透:

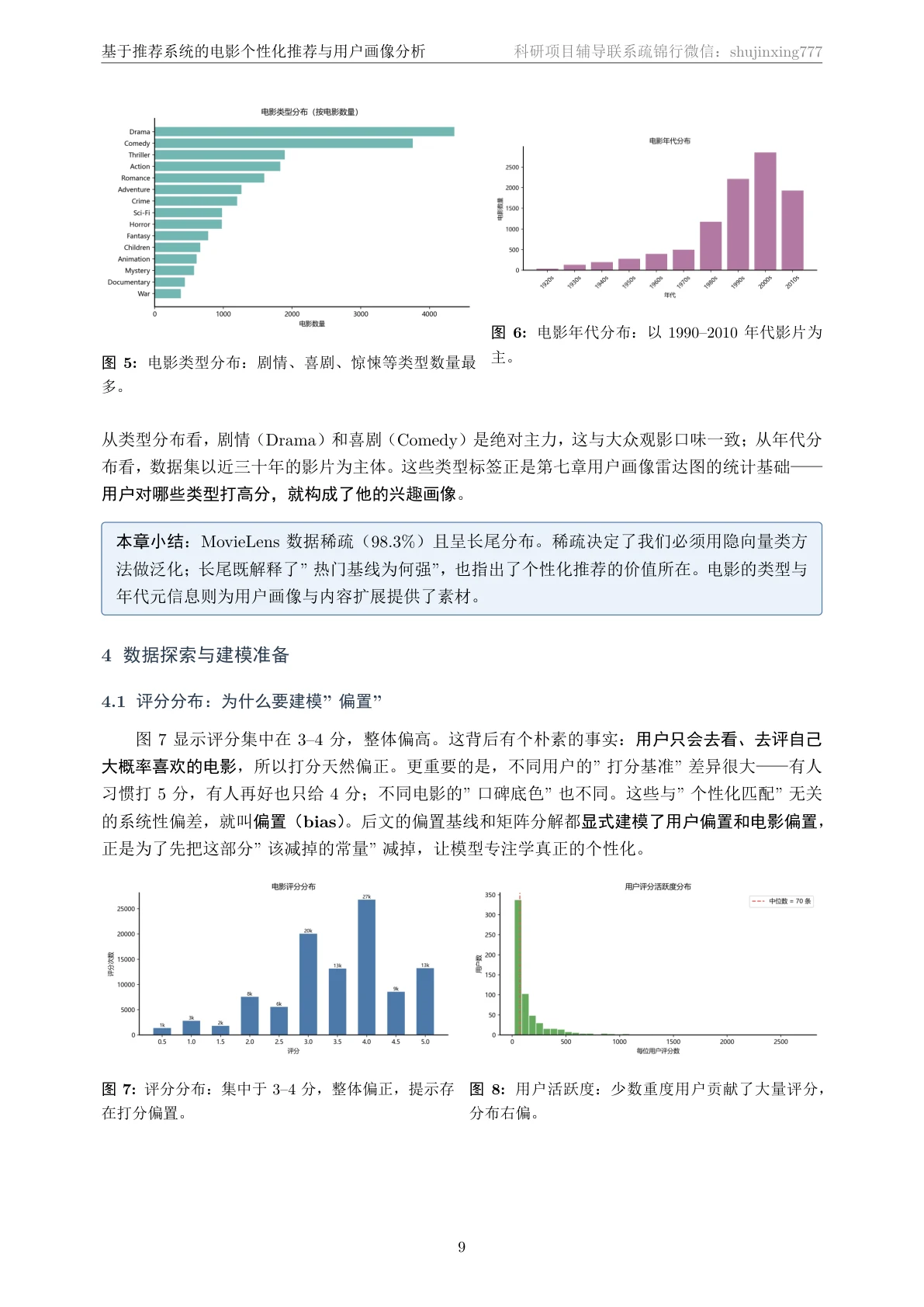
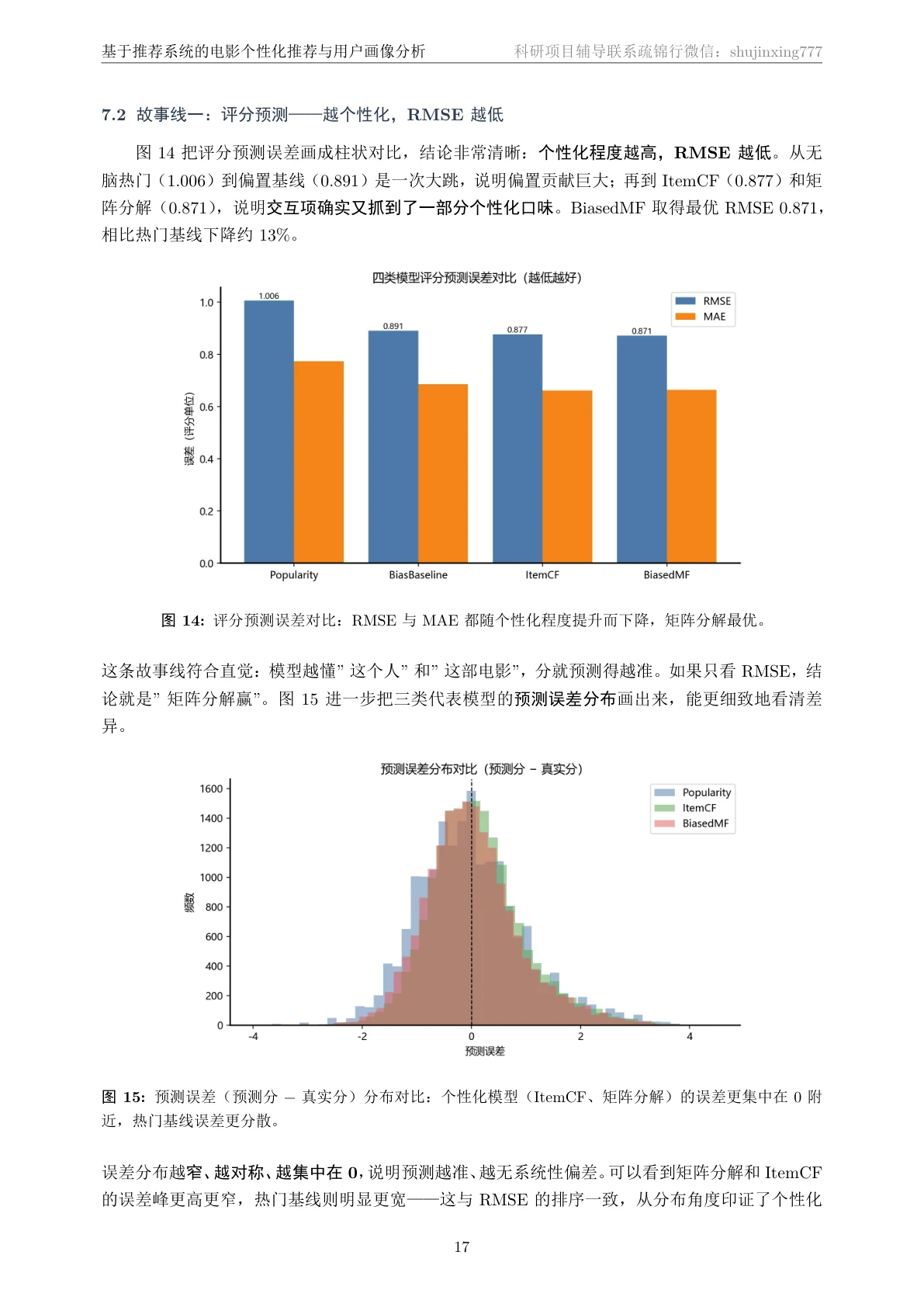
代码也给你了——关键部分都带着中文注释,帮你读懂「它到底是怎么实现的」,面试被追问细节时也答得上来:
技术文档、面试问答、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添个有分量的项目,还是在准备面试,这个题目都接得住——推荐系统是电商、互联网、数据岗位绕不开的方向,讲得好就是加分项。专业上,电子商务、市场营销、信息管理、计算机、数据科学方向都很合适。资料、讲解和面试答案都给你铺好了,把它真正搞懂、能讲出来,就是一个能写进简历、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「基于推荐系统的电影个性化推荐与用户画像分析」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。