基于大模型的社交媒体舆情分析与观点挖掘
在中英双语社交媒体文本上做情感分析与观点挖掘,把传统机器学习、预训练语言模型微调、大语言模型提示三种范式同台对比,再用熵权-TOPSIS 客观选模、用大模型抽取细粒度观点——一条把舆情分析从特征工程一路打通到大模型的完整研究流水线。
项目亮点
- 情感分析:判断社交媒体文本的情感极性(正面 / 负面)
- 观点挖掘:从评论中抽取高频观点词与情感倾向,刻画舆论焦点
- 中英双语:英文用 Twitter Sentiment140,中文用微博 weibo_senti_100k
- 传统机器学习:TF-IDF 特征 + 逻辑回归 / SVM / 随机森林 / XGBoost / LightGBM 五模型对比。
数据与任务
| 样本量 | 中英双语社交媒体文本 · Sentiment140 + 微博 weibo_senti_100k |
|---|---|
| 核心方法 | 三范式对比(ML / BERT微调 / 大模型提示)+ 熵权-TOPSIS 选模 + 观点挖掘 |
| 技术栈 | DeepSeek-V3 · Qwen-Max · GPT-4o · BERT/RoBERTa · scikit-learn |
如果你正在找一个紧跟大模型、又能写进简历、面试时还能讲清楚的 AI 项目,这个「用大模型做社交媒体舆情分析」的题目会很合适。
它的方向既有话题度也有方法论分量——情感分析是 NLP 最经典的落地任务,而这个项目没有停在"调个模型出个准确率",而是把同一件事用三种技术范式各做一遍、再客观比一比谁更合适:从传统机器学习,到 BERT 微调,再到当下最火的大模型提示。配套也都给你备齐了,帮你真正搞懂它、在面试和答辩里讲明白:带中文注释、能读懂的代码,一份从数据到三范式对比再到大模型观点挖掘的技术文档,里面连简历描述和会被追问的面试问题都连答案写好了,还有一整套能直接做 PPT 的配图。
先说清楚,它到底在做什么
舆情分析,说白了就是从海量、口语化、还夹着表情符号和噪声的社交媒体文本里,判断大家的态度是正面还是负面,再进一步看大家在议论什么、焦点在哪。这件事的难点不在"分类"本身,而在于:社媒文本太"野"——满屏的 @某人、#话题#、网络黑话和表情符号,先得把它清洗规整成机器能读的样子。
这个项目用了中英双语两套真实数据:英文取自 Twitter 的 Sentiment140,中文取自微博的 weibo_senti_100k,各自做了正负均衡的采样。在统一的清洗、划分和评测口径下,它把社媒情感分类这件事用三条技术路线分别走通,再汇到一处客观比较——这正是它最有分量、也最容易在面试里讲出彩的设计。
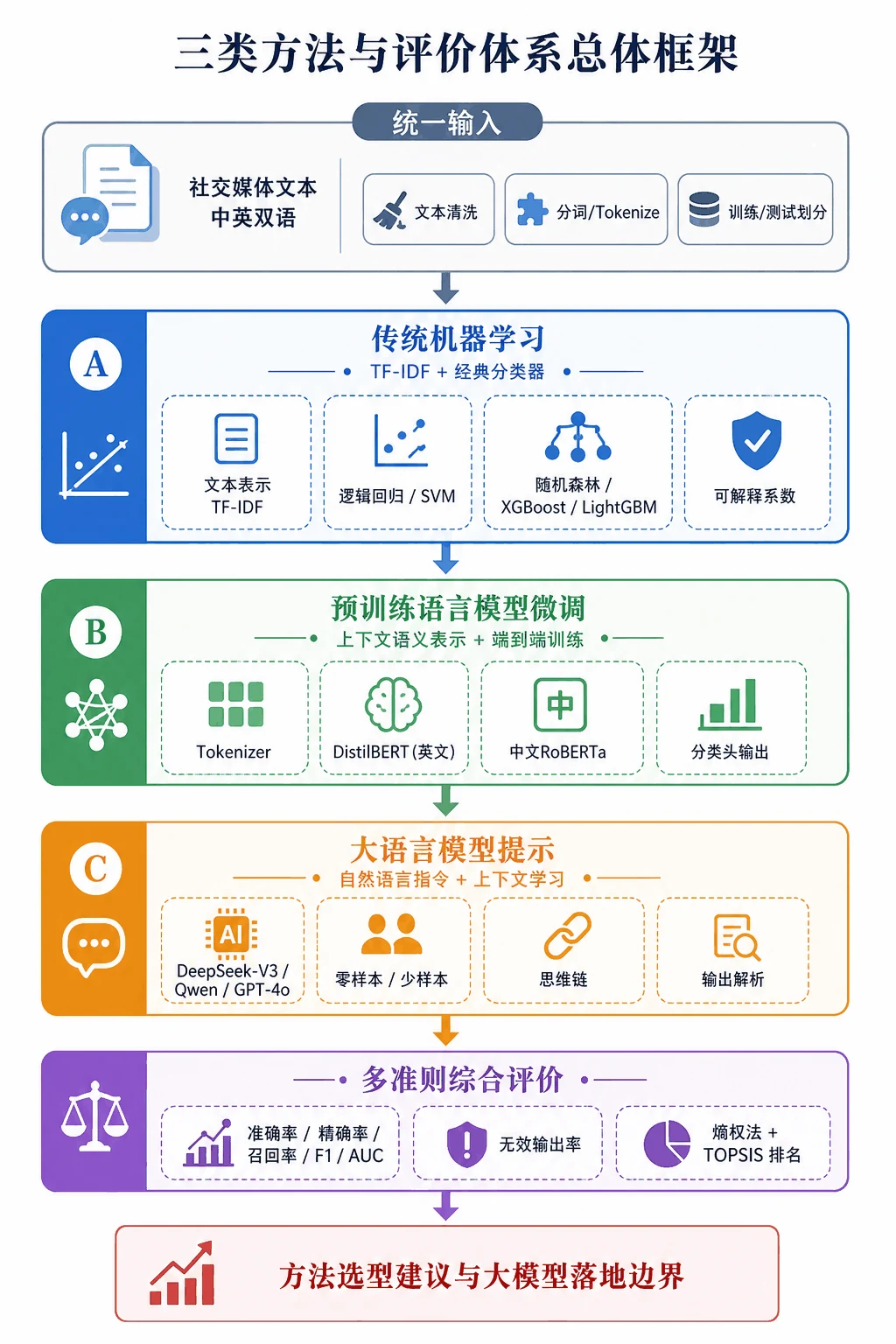
搞懂它,你能在面试里讲清楚什么
把下面几件事吃透,面试官顺着"三范式"和"大模型"这两条线问下来,你都能从容接住。
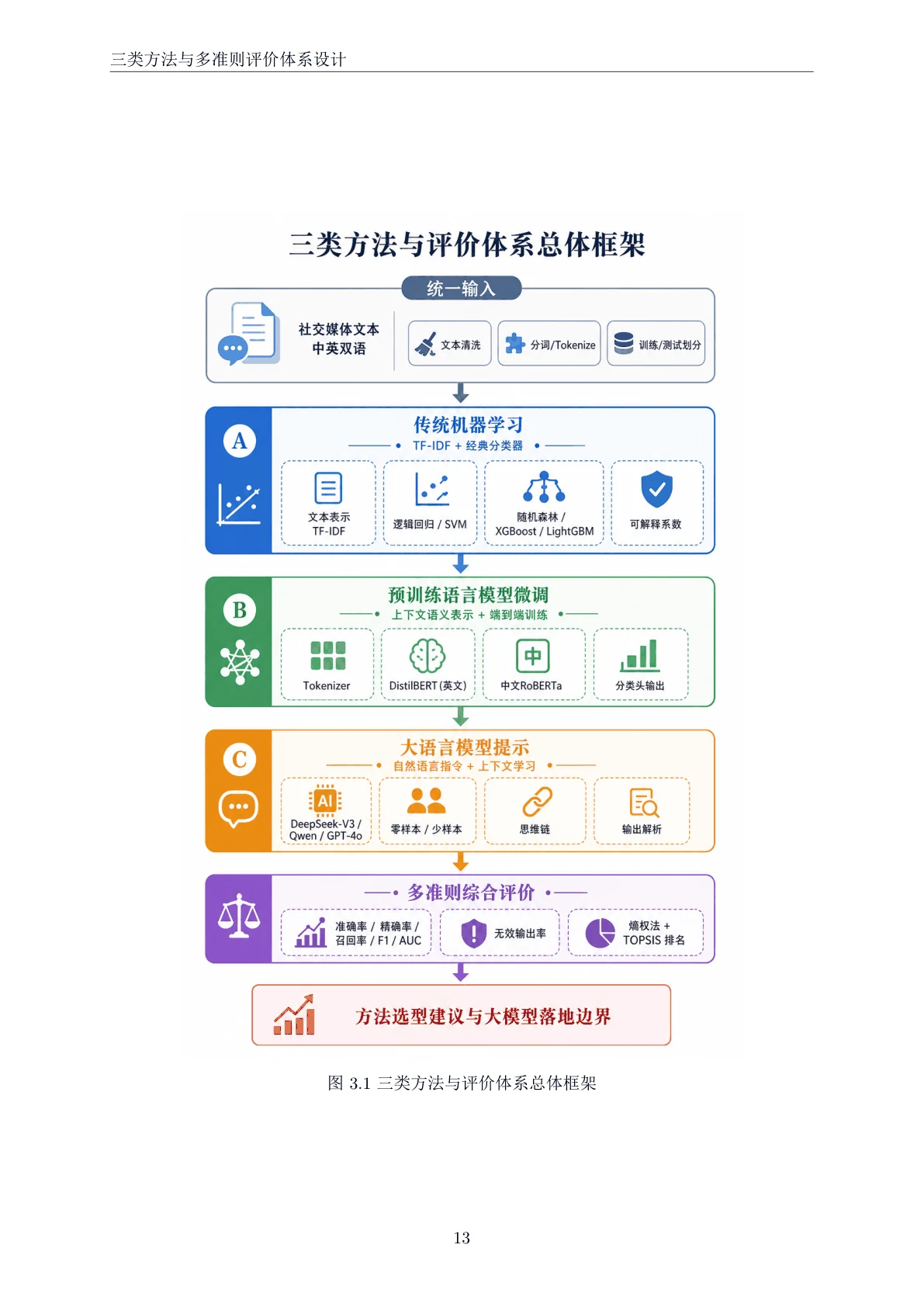
为什么要做"三范式对比",每一种各自强在哪。 这是整个项目的灵魂。你要能讲清楚这条技术演进的脉络:传统机器学习用 TF-IDF 加逻辑回归 / SVM / 随机森林 / XGBoost / LightGBM,胜在轻量、透明、系数可解释;预训练微调用 DistilBERT(英文)和中文 RoBERTa,靠上下文语义表示拿到强劲的端到端表现;大模型提示则不训练、只靠一段指令就能上手,胜在零成本迁移和灵活。把"同一个任务,三把不同的锤子各有什么脾气"讲明白,比只会背一个模型指标的人有分量得多。
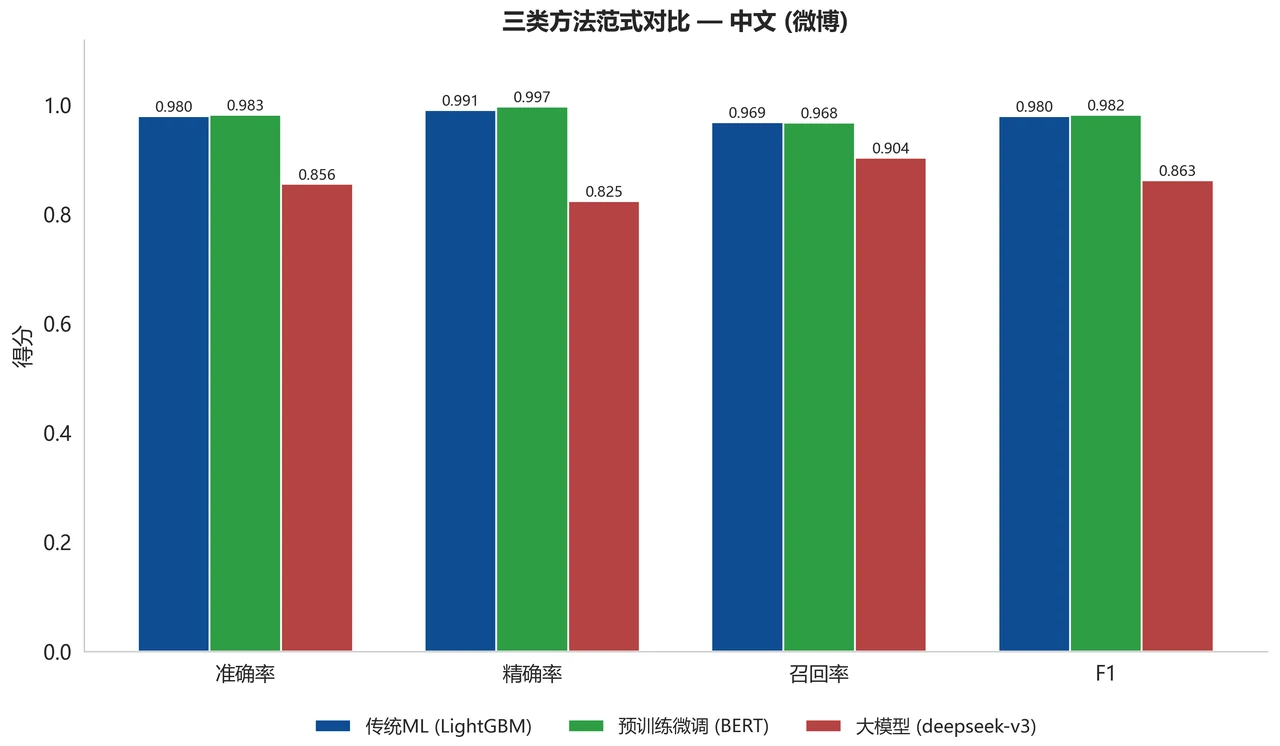
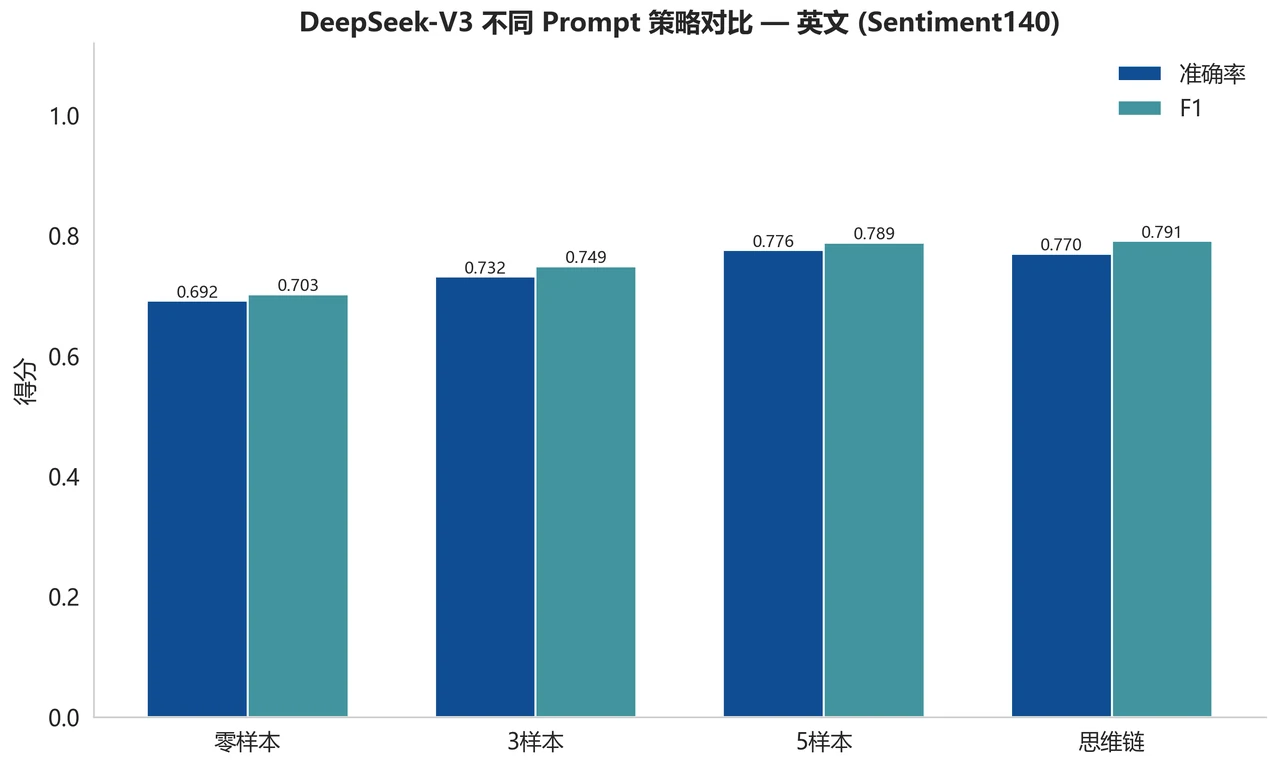
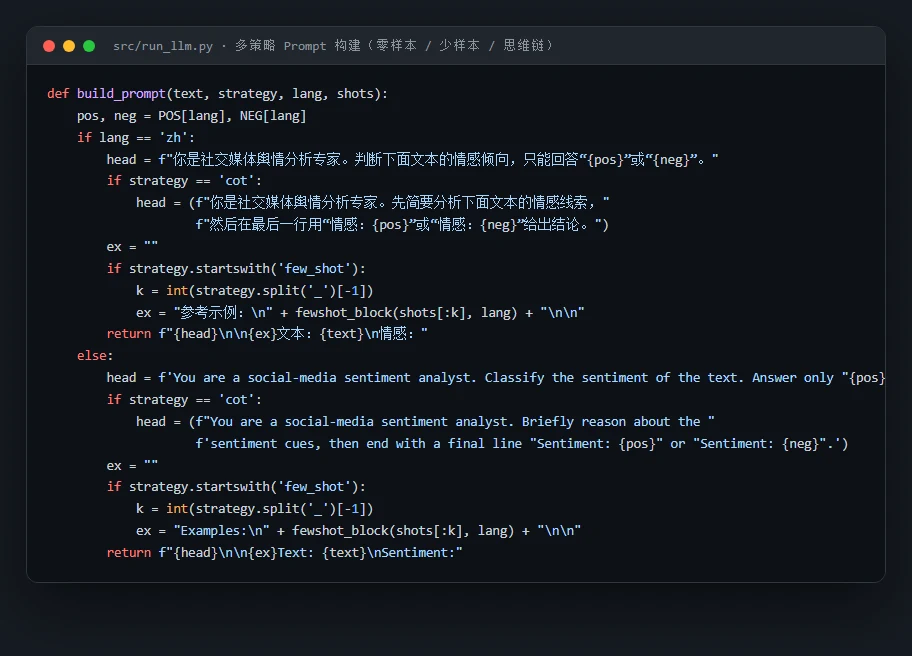
Prompt 工程怎么设计、为什么逐级递进。 大模型这条线不是"随手调个 API",而是系统对比了零样本、少样本(3 / 5 个示例)和思维链(CoT)多种提示策略。你能借此讲清楚 Prompt 工程的门道:few-shot 怎么塞进平衡的正负参考样例让模型照着类比,CoT 怎么引导模型先逐句分析情感线索、再在最后一行给出结论;还能讲清一个很实在的工程细节——大模型的自由文本输出要怎么稳定地解析回"正面 / 负面",无法解析的"无效输出率"又怎么作为大模型可用性的真实信号被记录下来。
怎么把结论讲得客观、有科研味。 五种 ML、两种微调模型、多个大模型策略,指标一多就容易"公说公有理"。项目的解法是引入熵权法 + TOPSIS 的多准则综合评价——把准确率、精确率、召回率、F1、AUC 这些指标用客观权重融合成一个排名,避免拍脑袋选模。再加上一份可解释性分析:把传统模型学到的情感关键词画出来,正向词和负向词一目了然,甚至能发现微博数据里"表情符号泄露情感"这种值得一提的现象。能把"我不是只看一个指标,而是有一整套客观的选模与归因逻辑"讲出来,正是面试官想听的判断力。
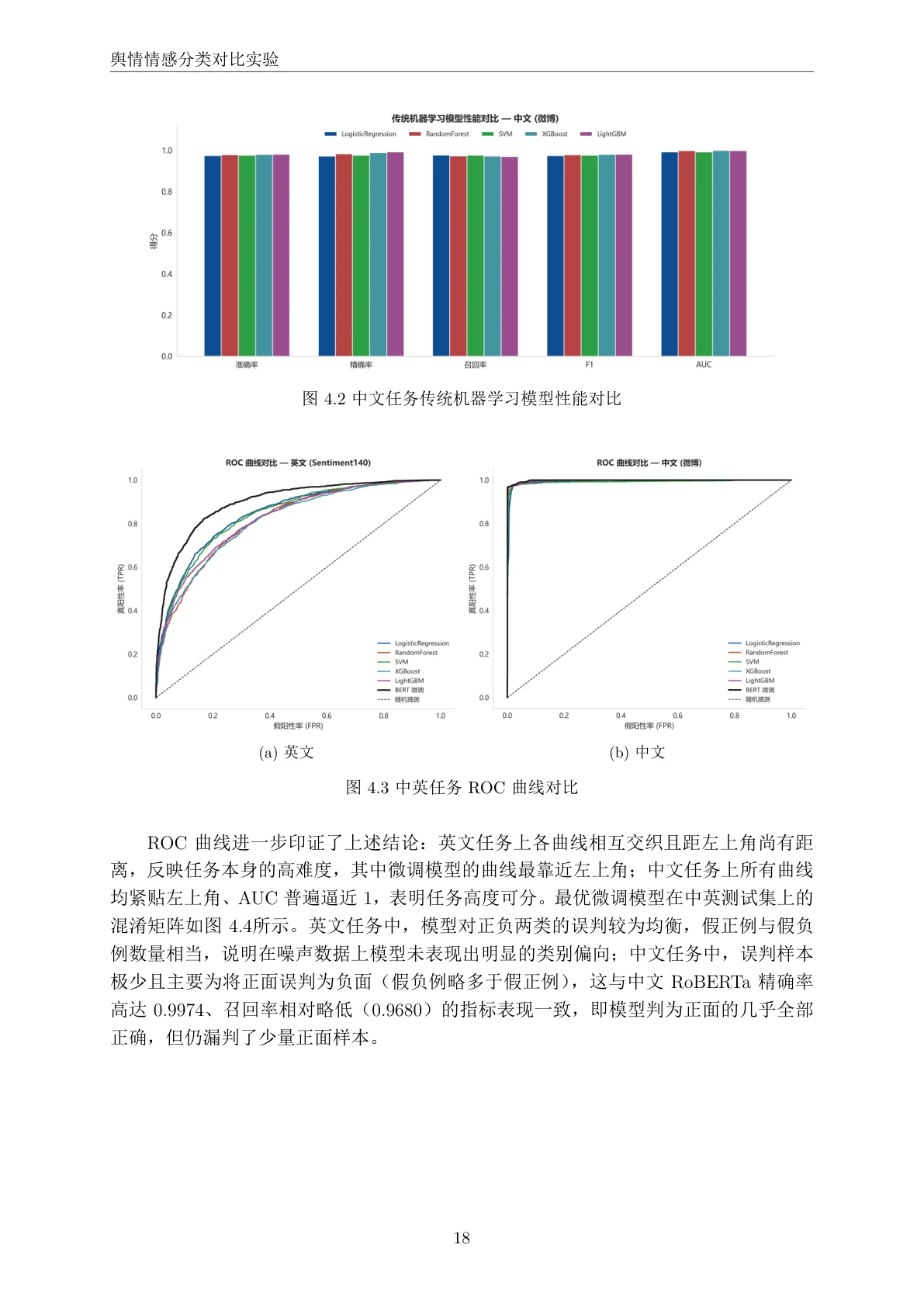
下面这组分析图也都给你做好了,可以直接放进答辩或面试 PPT:
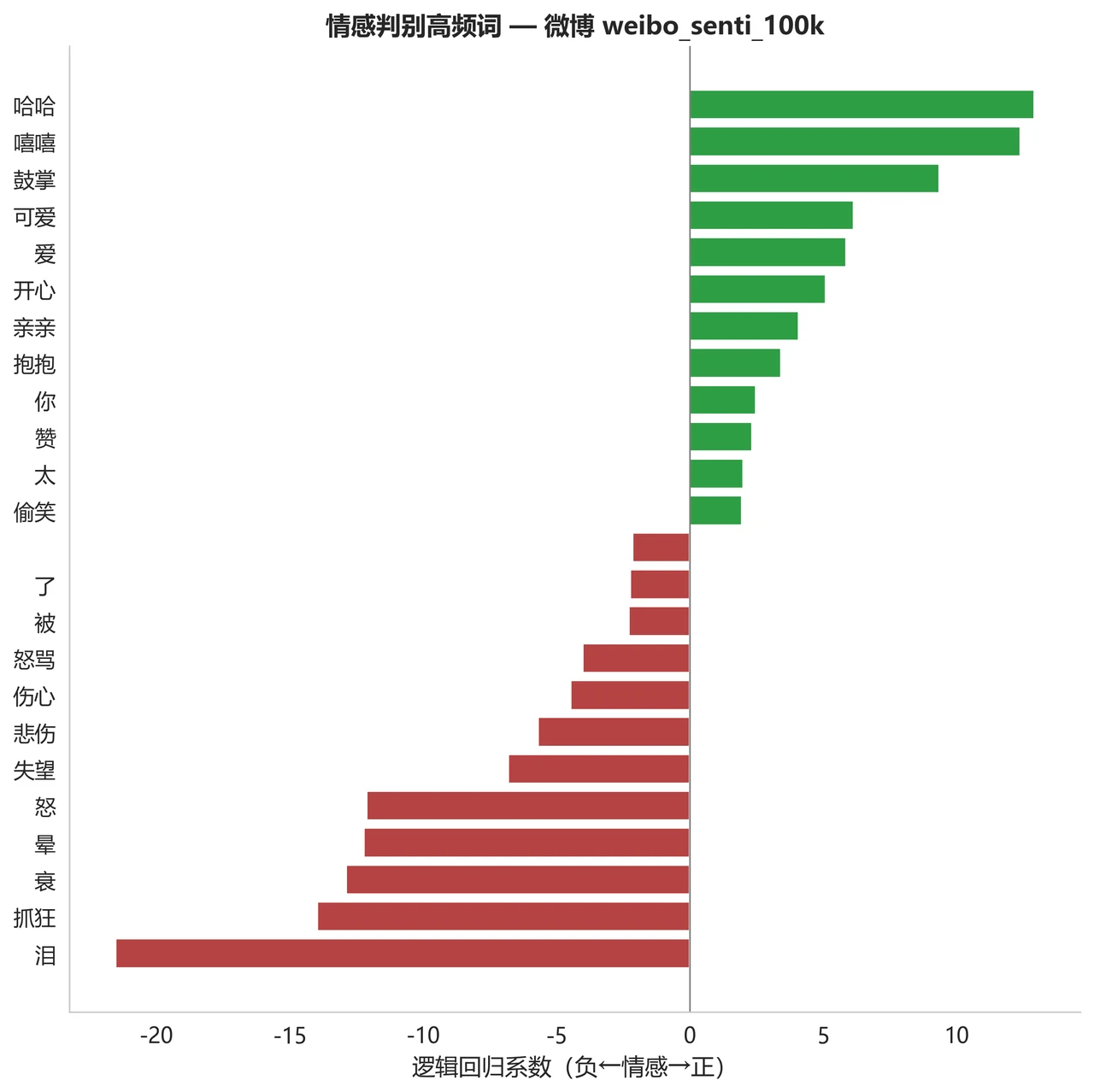
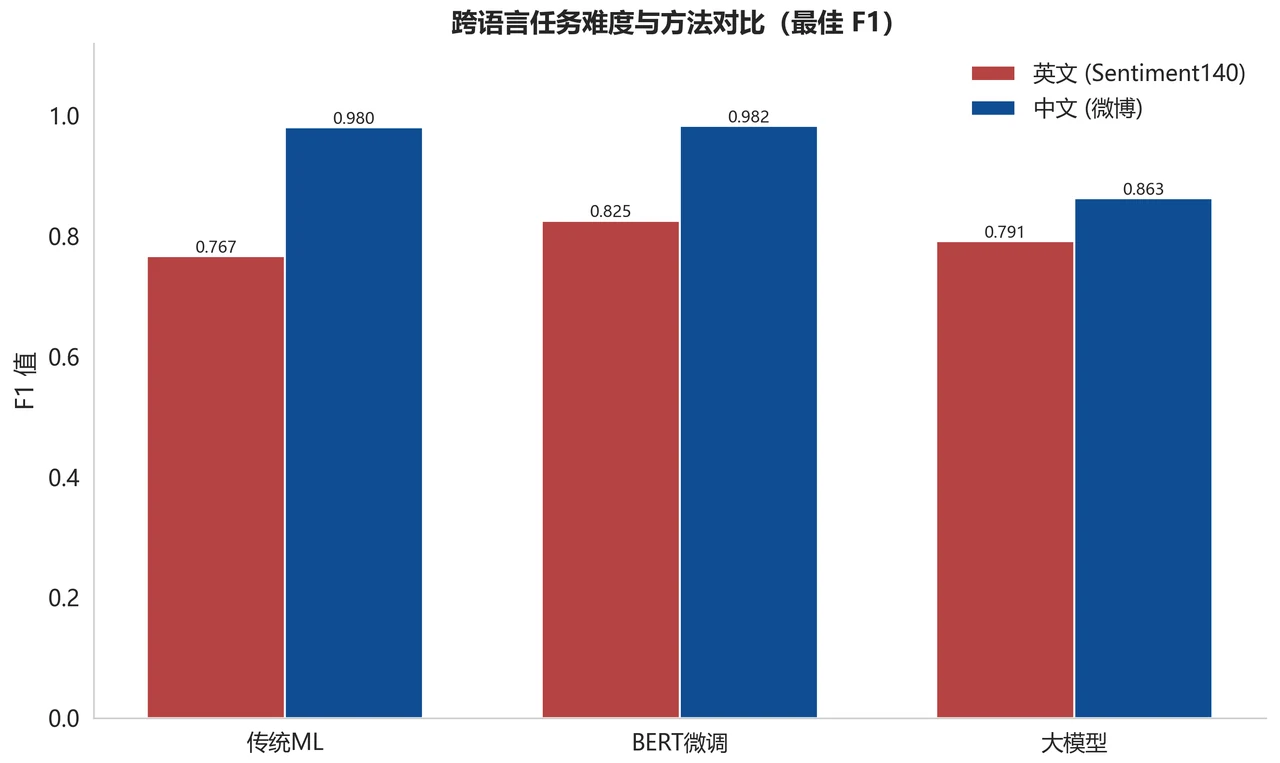
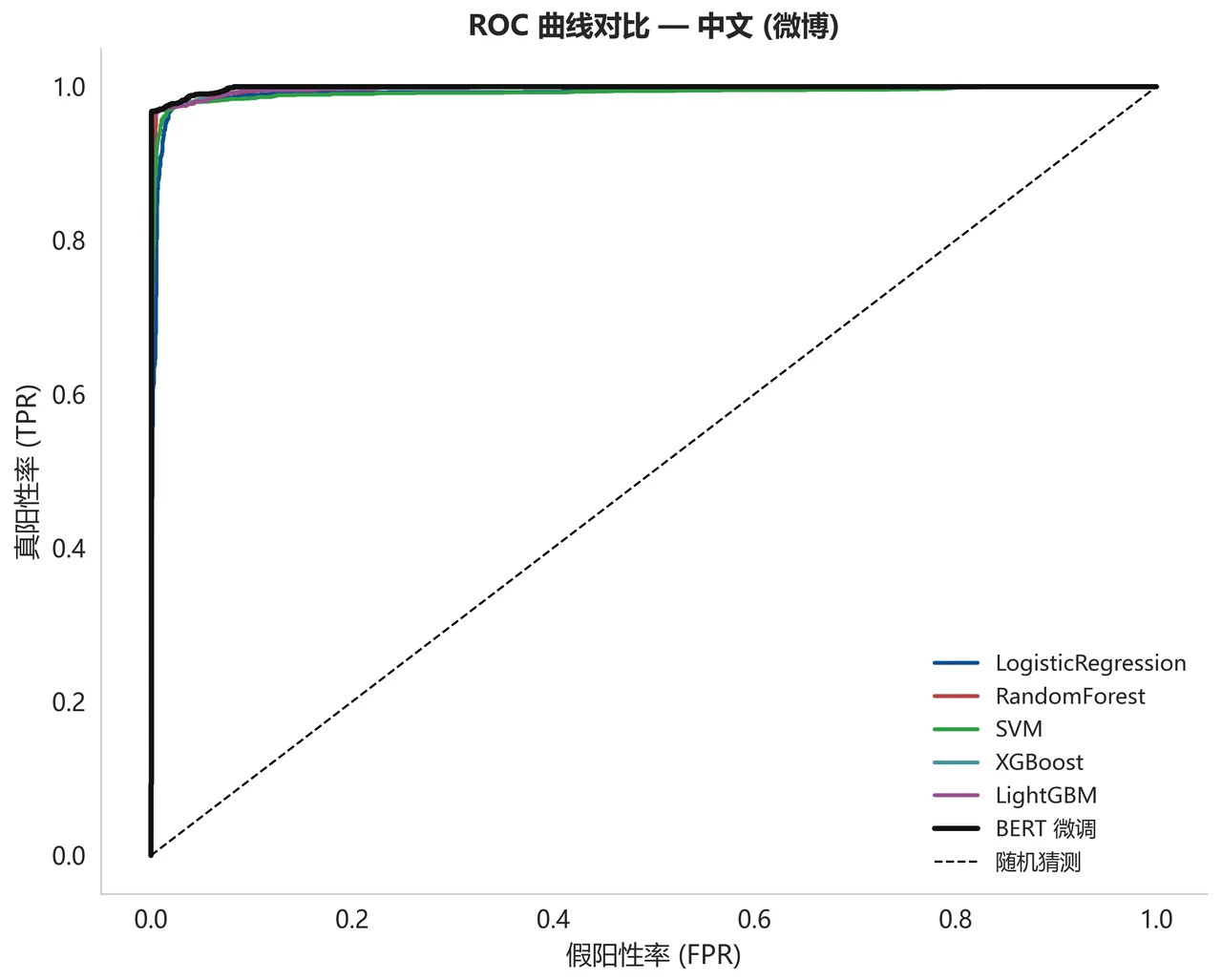
更关键的是,每一张图是怎么跑出来的、该怎么解读,技术文档里都讲清楚了——所以你不是只会往 PPT 上贴图,而是能说明白每张图到底说明了什么。
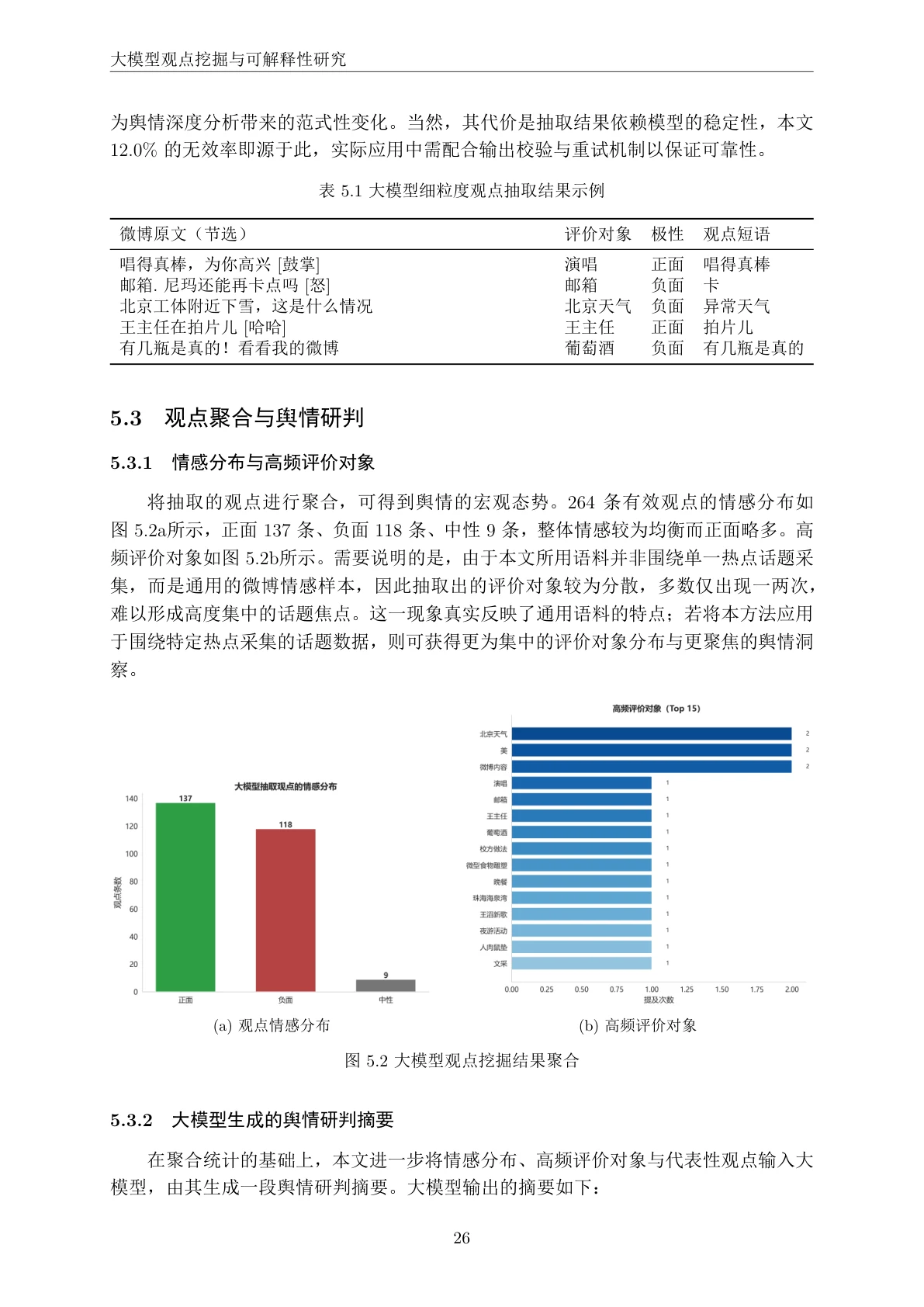
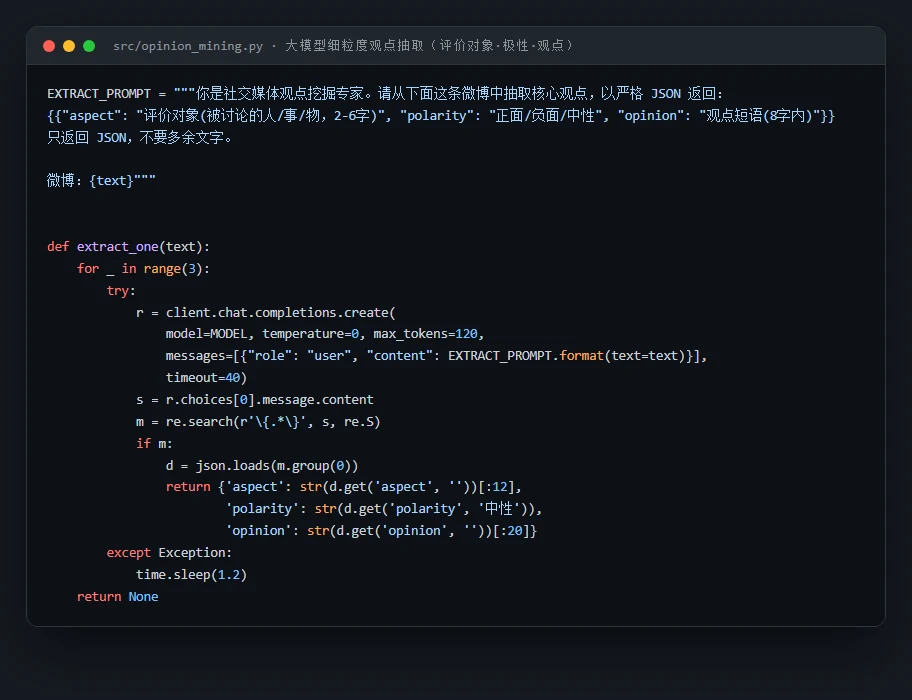
大模型不止会分类,还能"挖观点"。 这是项目里最能体现大模型独特价值的一环。情感分类只回答"正面还是负面",而项目进一步让大模型对每条微博抽取细粒度的三元组——评价对象(在说谁 / 什么)、情感极性、观点短语,全部以严格 JSON 结构化输出;再把这些观点聚合成情感分布、高频评价对象,最后让大模型生成一段舆情研判摘要。你能借此讲清楚:这种"开箱即用"的细粒度理解能力,传统方法要靠大量人工标注才做得到,而大模型一段提示就能完成,灵活迁移到任意新话题。
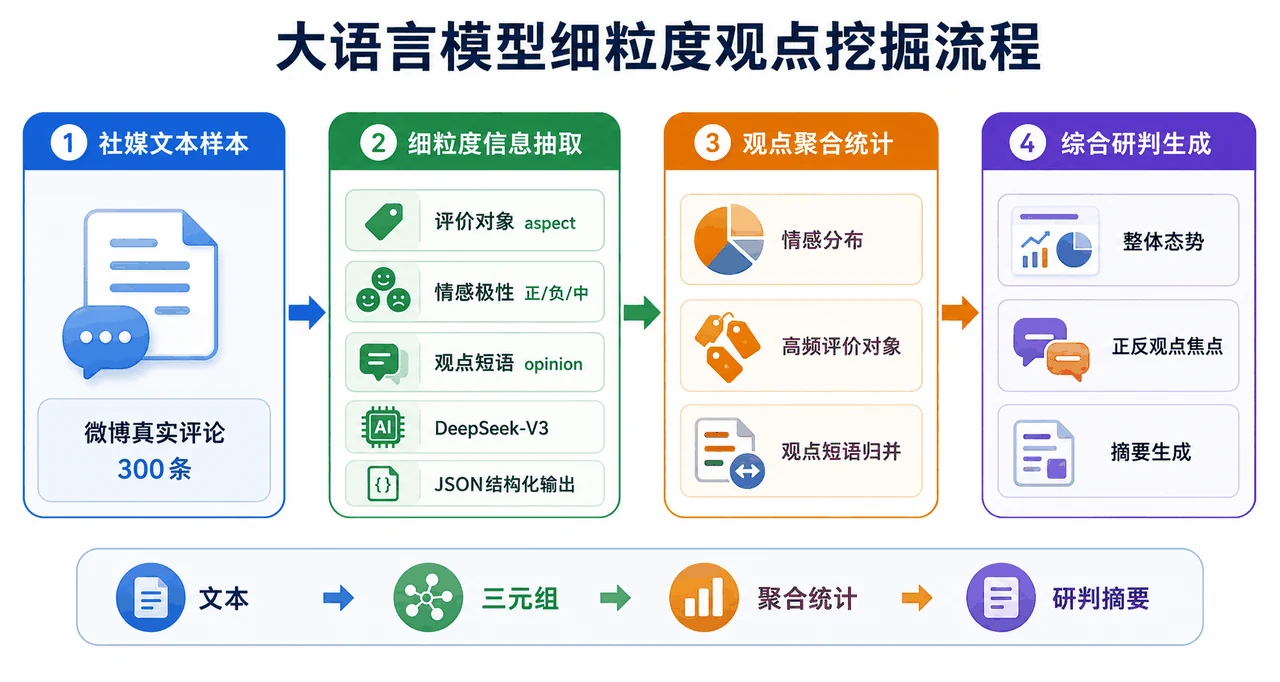
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
- 同一个情感分类任务,传统机器学习、BERT 微调、大模型提示这三条路线你觉得各自强在哪?
- 大模型输出的是自由文本,你是怎么把它稳定解析成"正面 / 负面"的?无效输出又怎么处理?
- 指标那么多,你最后凭什么选出"最好"的模型?熵权法 + TOPSIS 是怎么做客观排序的?
- 观点挖掘里的细粒度三元组(对象·极性·观点)是怎么让大模型一次性抽出来的?
看到这几个是不是会愣一下?正常。配套的项目讲解资料把这个项目——从整体思路到每个流程细节、各种可能被追问的点——连参考答案都给你写好了,连三范式那组对照、Prompt 策略、TOPSIS 选模该怎么讲都帮你梳理清楚了。另外还有现成的简历描述,照着改就能写进简历;那一整套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。你要做的不是背,而是理解,再用自己的话讲一遍。
配套资料:搞懂一个项目需要的,这里全都有
先看那份技术文档——从研究背景、数据构建与探索性分析,到三类方法与评价体系设计,再到对比实验与大模型观点挖掘,图文并茂,帮你把整条研究链路从头吃透:
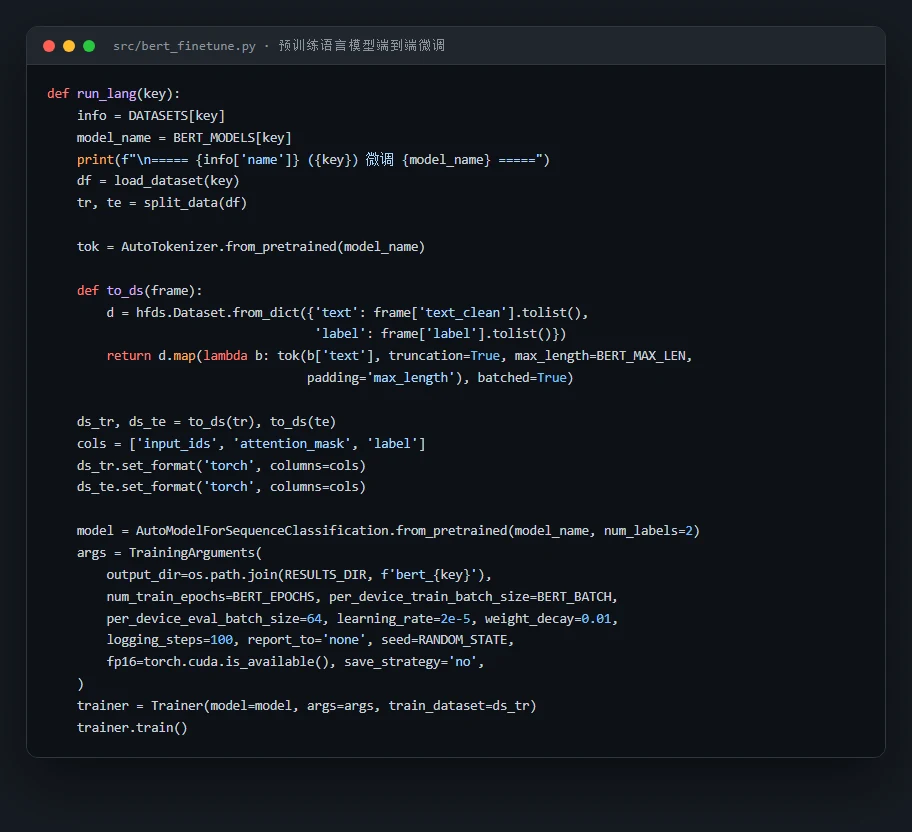
代码也给你了——关键部分都带着中文注释,帮你读懂"它到底是怎么实现的",面试被追问细节时也答得上来:多策略 Prompt 构建、大模型细粒度观点抽取、预训练模型微调,三段核心代码各截一份:
技术文档、项目讲解资料、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添个紧跟大模型潮流的项目,还是在准备面试,这个题目都接得住。专业上,大模型应用、自然语言处理、计算机、人工智能、数据科学,以及传播学、新闻舆情、社会计算方向都很合适——尤其是想往大模型应用、AI+舆情方向走的同学。把"同一个任务怎么用三种范式各做一遍、怎么设计 Prompt、怎么客观选模、怎么让大模型挖出细粒度观点"这条完整链路真正搞懂、能讲出来,就是一个既追热点、又有方法论分量、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「基于大模型的社交媒体舆情分析与观点挖掘」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。