自信地犯错:大模型能否充当控制系统的“前向模型”
把大语言模型放进控制回路、让它读着对象描述去整定 PID 增益,正成为热门设想;但它真的'懂'动力学、能预测一个动作的后果吗?本项目用探针式实证把'控制知识'和'前向预测技能'干净拆开单独考,在三个物理本质迥异的对象、四个开源模型上钉死结论:知识满分,前向预测却近乎随机、甚至显著低于瞎猜。
项目亮点
- 唯一主版本 = `mdpi-template/main_p2.tex`,所有内容改这里。
- 所有数字以 `docs/findings-ledger.md` 为准;故事跟着数据走,绝不编造。
- Fig1 改图从 `mdpi-template/figures/_fig1_source/` 编辑,导出 no-title pdf 覆盖 `fig1_concept.pdf` 再重编译。
数据与任务
| 样本量 | 三个物理本质迥异的 MIMO 对象 · 仿真给客观真值 · 4 开源模型(加测 32B) |
|---|---|
| 核心方法 | 探针式实证(知识/前向双探针) + 启发式反推 + 2×2 消融/思维链/规模三组对照 |
| 技术栈 | PyTorch · 开源 LLM 推理 · 控制仿真 · Wilson CI 统计 |
如果你想找一个把"大语言模型到底会不会推理"这件事真正问透、又带着工程判断力的项目,这个「大模型作为控制前向模型的探究」很合适。
它的切口又新又锋利——眼下"用 LLM 来整定控制器、读着对象描述就把 PID 增益调好"正是热门设想,可这股热潮底下压着一个几乎没人正面验证过的乐观假设:LLM 既然控制理论考满分,应该也内化了对象的动力学、能预测"把这个增益调大、闭环会更好还是更差"。这个项目就正面拷问这个假设。配套也帮你备齐了,让你真正搞懂它、在面试和答辩里讲明白:带中文注释、能读懂的探针与评测代码,一份从背景讲到方法、实验与边界的 32 页技术说明文档,里面连简历描述和会被追问的面试问题都连参考答案写好了,还有一整套能直接做 PPT 的实验图。
先说清楚,它到底在做什么
工业过程控制里最常见的活儿,是给一个对象(水箱液位、反应器浓度……)整定 PID/PI 增益。整定的本质是反复试错的优化:调一组增益、跑闭环、看跟踪误差大不大,再据此决定往哪个方向改。这件事难,是因为它严重依赖对象的动力学——你得"知道"或"猜到"把某个增益调大、闭环会怎么变。传统要么先做系统辨识建精确模型(贵、难、易过时),要么走无模型黑盒优化(采样代价高、易卡坏解)。于是一个诱人的设想浮出水面:让 LLM 来当这个"懂动力学的大脑"。
但这设想站在一个被默认成立的假设上:LLM 既然能答对"积分作用消除稳态误差""强耦合系统盲目增大所有增益会失稳"这类考题,它应该自带一个前向模型(给定状态与动作、预测下一状态/闭环后果)。这个项目要做的,就是把"懂知识"和"会预测动力学"这两件被默认绑在一起的事干净地拆成两套独立探针分别考,看它们之间到底有没有裂缝。
搞懂它,你能在面试里讲清楚什么
把下面几件事吃透,面试官顺着这条线问下来你都能接得住。
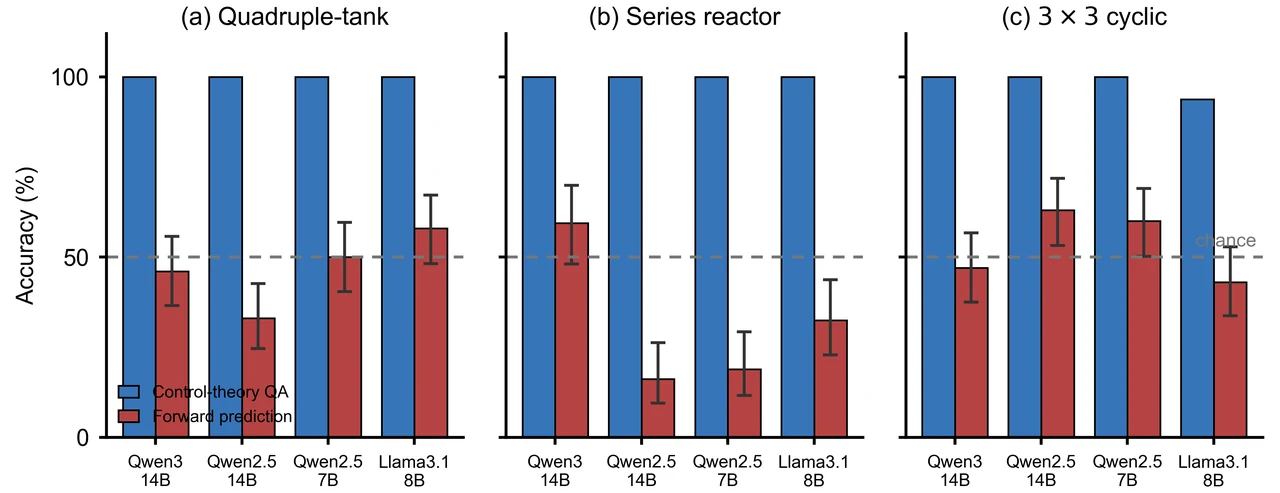
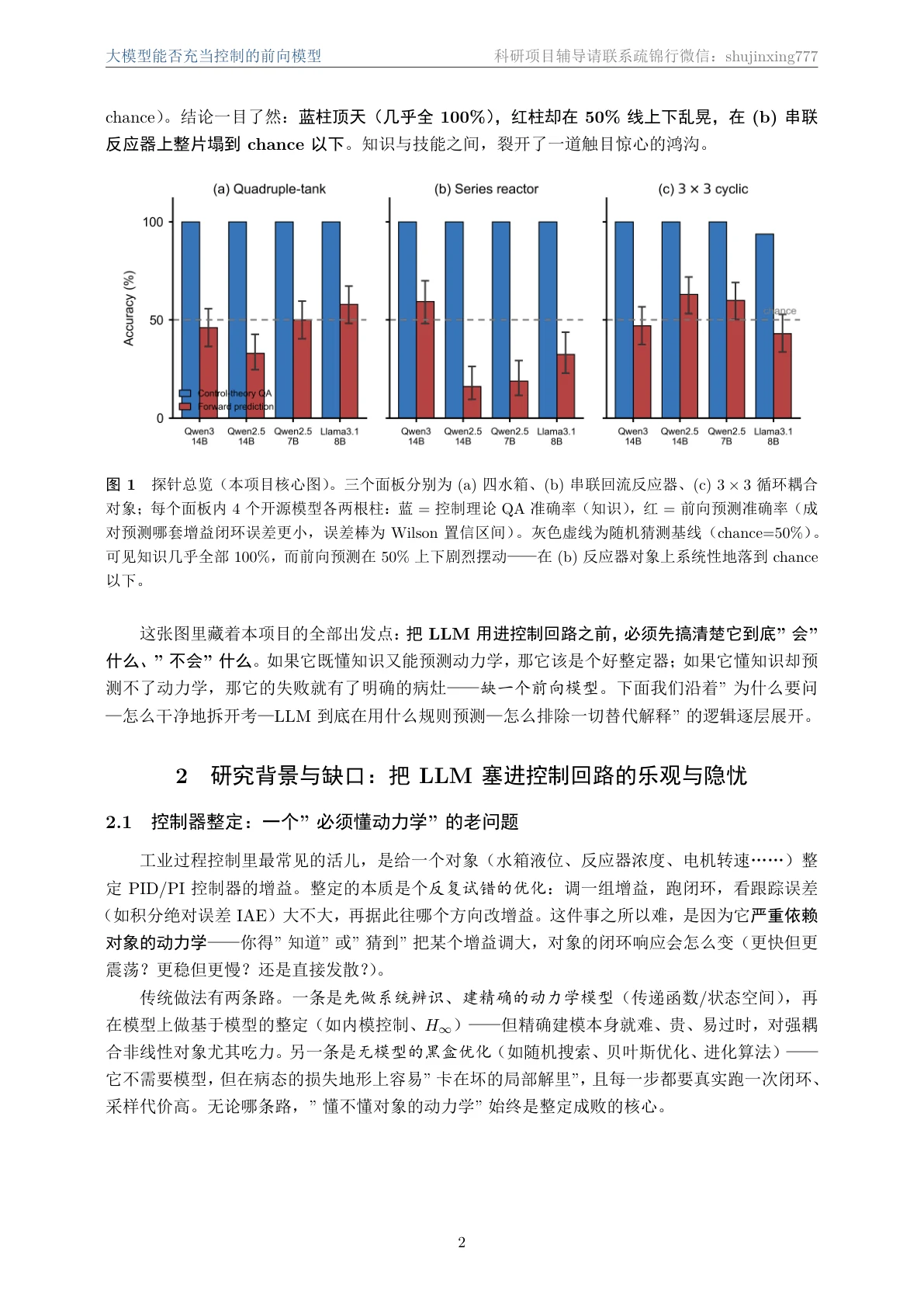
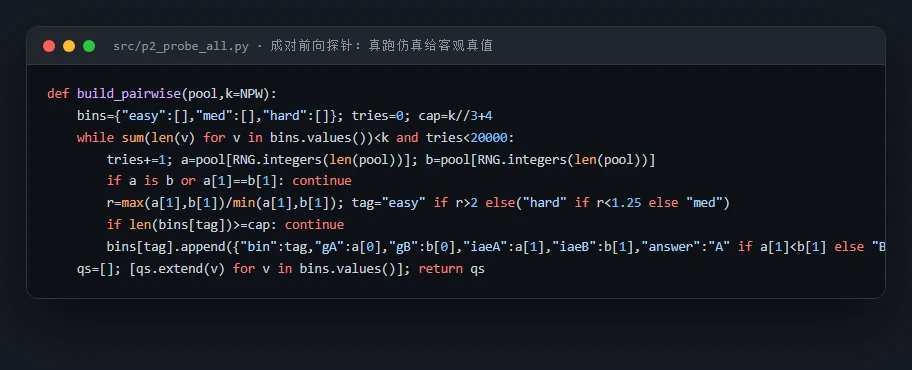
"知识"和"预测"这两件事,怎么被干净地分开测。 这是整个项目方法论的骨架。你要能讲清楚:知识探针(E1)用控制理论 QA + 给定结构的定性推理考教科书;前向探针(E2)用成对预测(两套增益谁的 IAE 小)、方向预测(增益乘 3、误差升还是降)、稳定性预测考零样本动力学。关键不在出题,而在前向题的客观真值——每道题的两套增益都先在对象上真跑仿真、记录真实 IAE,谁小谁就是答案;再配 50% 随机基线和 Wilson 置信区间,"它到底有没有超过瞎猜"就成了可统计检验的硬结论,而不是看图说话。
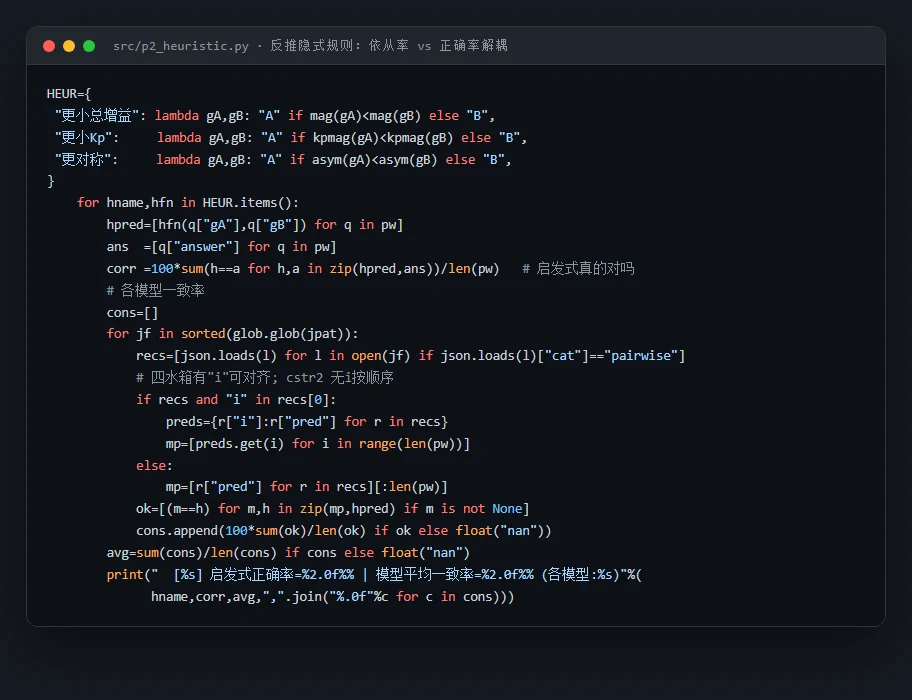
那条"低增益先验"是怎么被诊断出来的。 这是项目最有思想含量的一点。知识满分、预测却近随机,到底是因为它在乱猜,还是在套一条与动力学无关的固定规则?做法很巧:靠"依从率 vs 正确率"的解耦。对每道成对题,先看候选规则(如"选增益更小的那组")会怎么答,再分别算——① LLM 实际选择对这条规则的依从率(只看 LLM、与真值无关);② 这条规则相对仿真真值的正确率(只看规则、与 LLM 无关)。如果 LLM 在推理,行为该随对象变;如果在套规则,依从率该不随对象动、而预测准确率被规则碰巧对不对牵着走。实测正是后者。
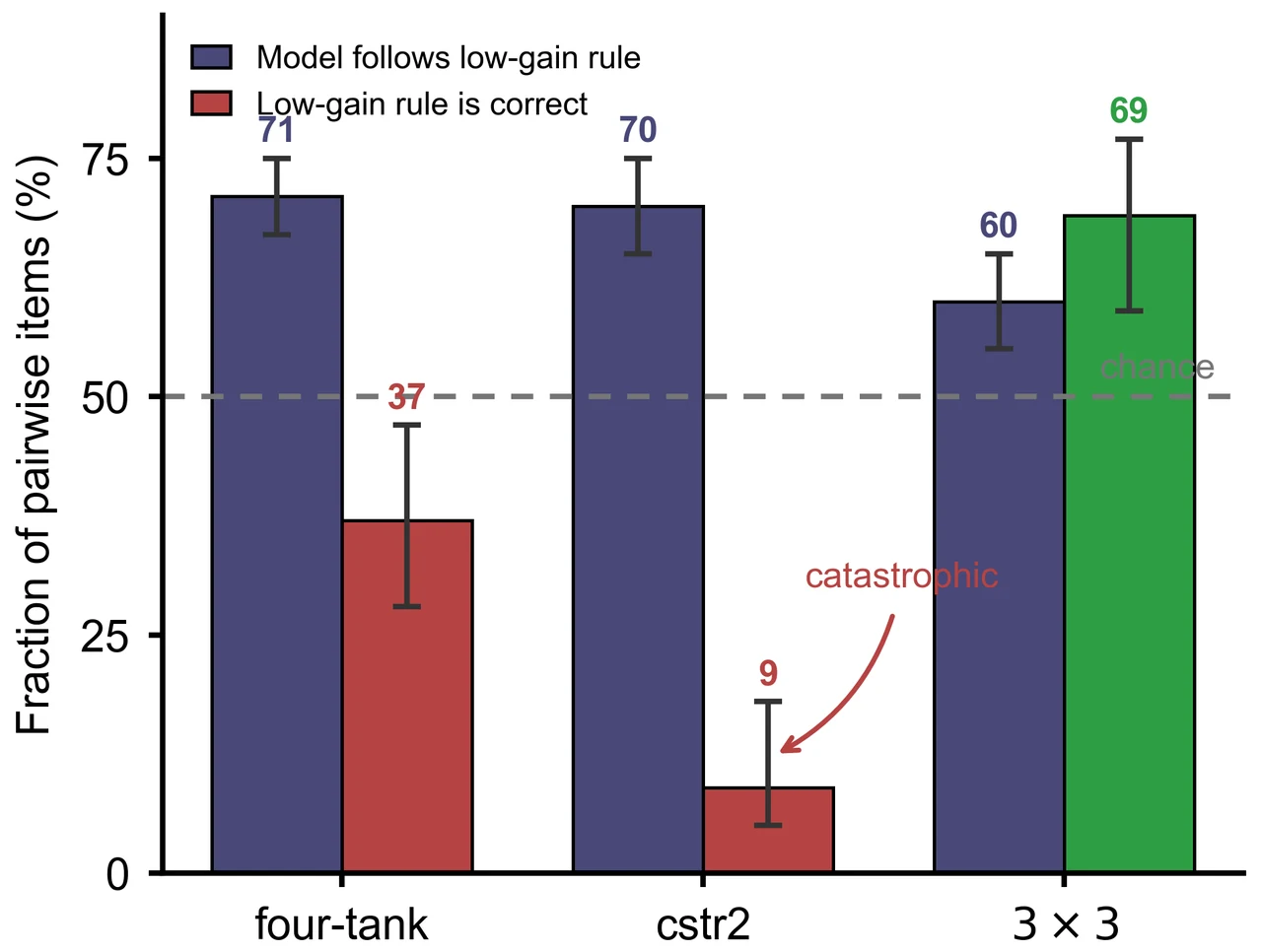
三组对照怎么各自钉死一个替代解释。 这是项目让结论站得住的落点。面对"知识满分、前向预测崩塌",总有人会反问"是不是上下文喂得不够""是不是想得不够多""是不是模型不够大"。项目用三组干预逐一堵死:\(2\times2\) 知识×反馈消融证明有用的是知识、不是反馈(而"从反馈推断动力学"恰恰是前向模型的活儿);思维链开关证明越想越固化、错先验被放大;规模升到 32B 证明更大也学不会预测。三组对照各杀死一个退路,把根因精确坐实在"缺前向模型"本身。
下面这组实验图也都给你做好了,可以直接放进答辩或面试 PPT:
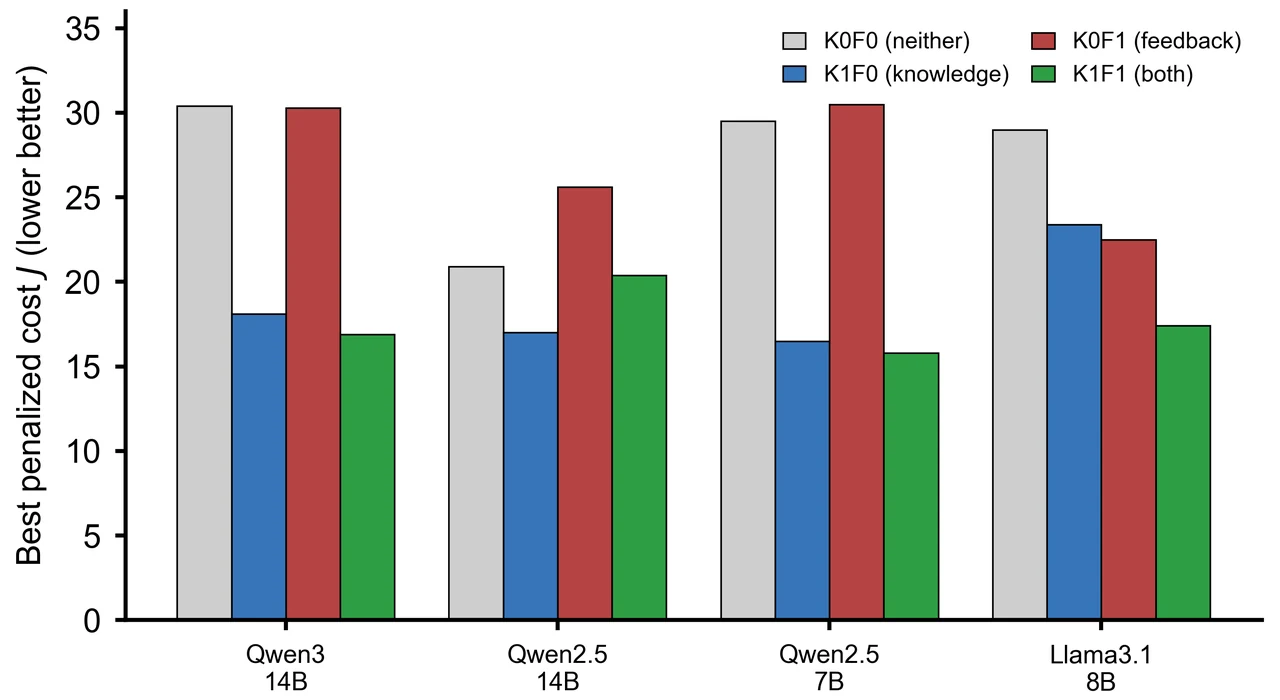
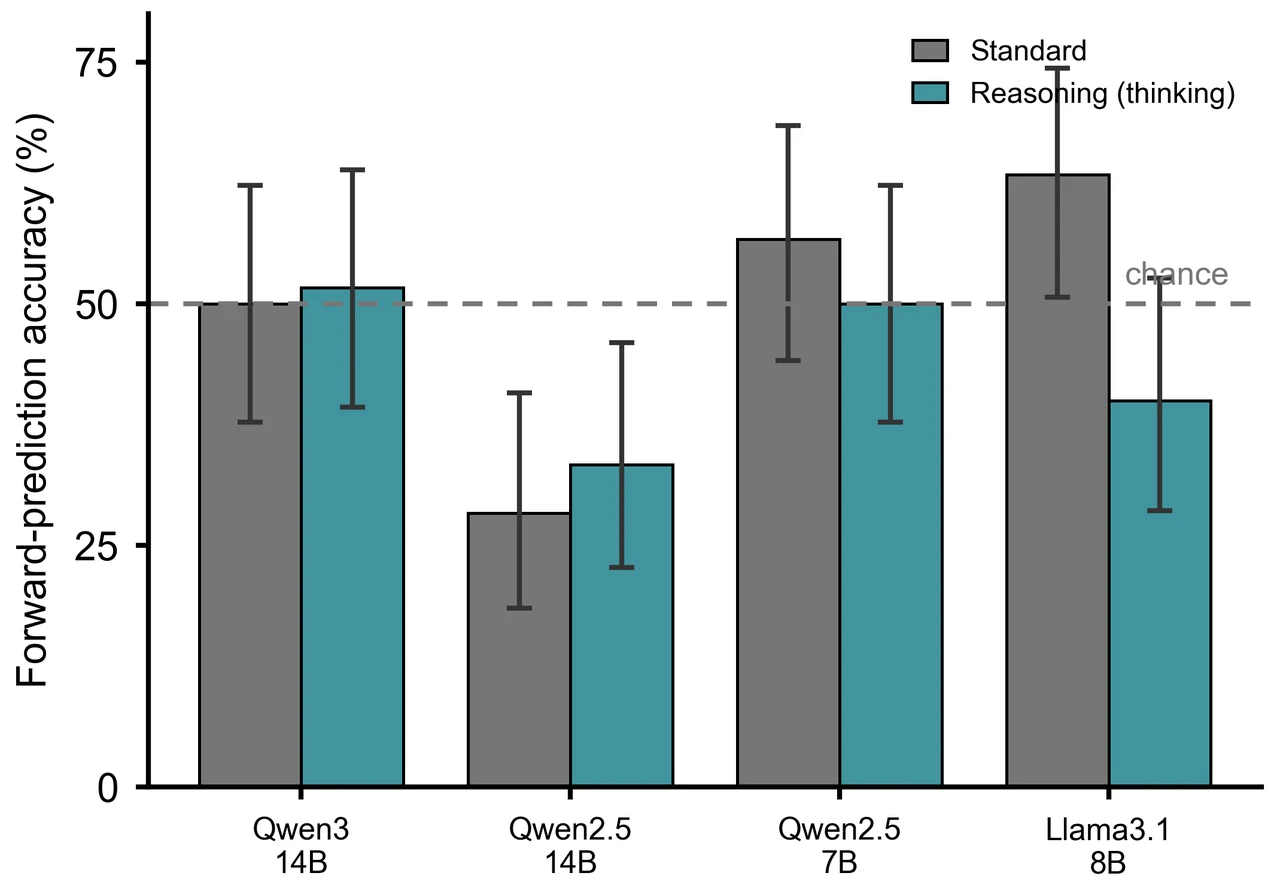
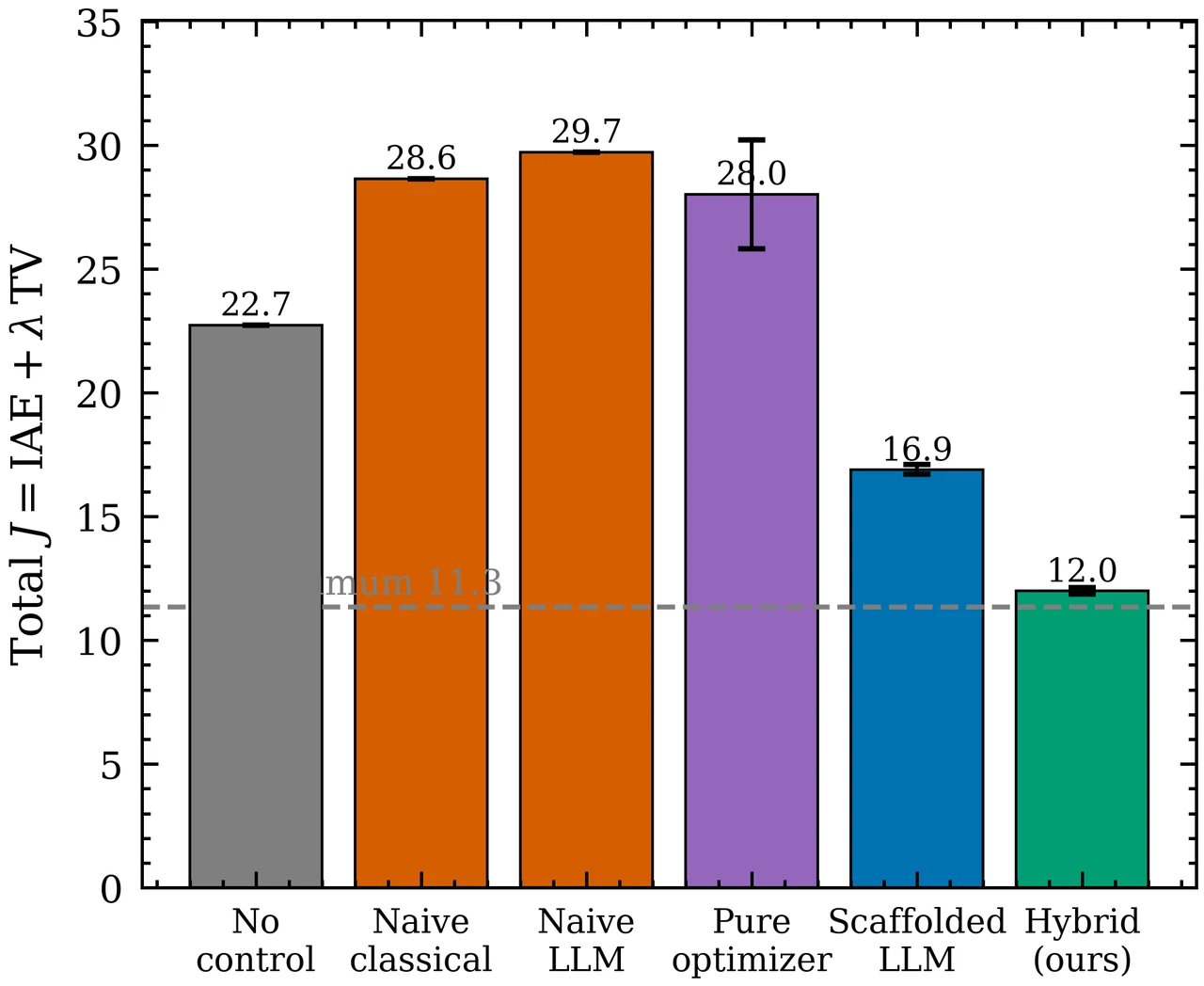
更关键的是,每张图怎么跑出来的、该怎么解读,技术文档里都讲清楚了——比如反应器上 32% 这个"显著低于随机"的数字到底意味着什么(不是没信息,而是被一条系统性错误的规则带偏、且深信不疑),以及为什么"自信地错"比"预测不了"在控制、医疗这类后果敏感场景里危险得多。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
既然 LLM 控制理论考满分,这个课题还有什么可做的?知识满分到底是噪声还是关键证据?
你怎么证明 LLM 是在"套规则"而不是在"推理"?"依从率 vs 正确率"的解耦到底解耦了什么?
反应器上 32% 这个"显著低于随机"的数字,到底说明了什么?为什么说它比 50% 更危险?
看到会愣一下?正常。配套的项目讲解资料把这个项目——从研究动机、方法设计、实验设计到结果解读、深挖思辨——连参考答案都给你写好了,每道题还分"核心点"(一句话能答出的标准回答)和"延伸思考"(再深一层、把面试官镇住的加分内容)两层。另外还有现成的简历描述,照着改就能写进简历;那套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。
配套资料:搞懂一个项目需要的,这里全都有
先看那份技术说明文档——从"把 LLM 塞进控制回路的乐观与隐忧",讲到前向模型为什么是整定的命门、三个对象怎么各司其职、探针怎么设计,再到低增益先验的反推、三组干预消融,以及"什么场景可以用、什么场景危险"的工程边界,图文并茂:


代码也给你了——关键部分都带着中文注释,帮你读懂"它到底是怎么实现的":左边是成对前向探针怎么真跑仿真给出客观真值,右边是启发式反推怎么把"依从率"和"正确率"解耦开来:
技术文档、项目讲解资料、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添一个"既有判断力又有方法论分量"的项目,还是在准备面试,这个题目都接得住。专业上,计算机、人工智能、自动化/控制方向都很合适——尤其是想往大模型评测、智能体可靠性、智能控制方向走的同学。把"怎么把'懂知识'和'会预测动力学'拆开单独测、怎么从模型行为反推出它套用的隐式规则、怎么用对照实验把根因钉死、再怎么落到能不能用的工程边界"这条完整链路真正搞懂、能讲出来,就是一个不靠堆数据、靠想法和实验设计取胜的、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「自信地犯错:大模型能否充当控制系统的“前向模型”」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。