隐私约束下的本地大模型工业控制:把开源 LLM 当作可靠的结构先验整定强耦合 MIMO
工业现场两条红线:过程数据不许出厂上云、专有接口无法审计离线部署。本项目把开源大模型搬到厂内一台工作站本机部署,不联网地帮强耦合 MIMO 过程整定控制器——但不让 LLM 去逐个数字搜增益,而是让它从实测耦合矩阵里推理出反直觉的“结构先验”(哪个回路该主导),再交给数值优化器精修大小,关上一个稳、平滑、可审计的闭环。
数据与任务
| 样本量 | 四水箱强耦合 MIMO + 单回路 CSTR + 3×3 对象 · 阶跃测耦合 · 仿真测试床 |
|---|---|
| 核心方法 | 本机开源 LLM 结构先验 + Nelder-Mead 优化器精修 + RGA 廉价边界诊断 |
| 技术栈 | PyTorch · transformers(开源权重 bf16) · pc-gym · scipy |
如果你想找一个把"大模型"和"硬核工业控制"真正接在一起、又能讲清楚"LLM 到底贡献了什么别的方法给不了的东西"的项目,这个「本地部署大模型的工业控制系统」很合适。
它的设定一上来就很扎实:工业现场有两条谁都绕不开的红线——实时过程数据不许出厂上云(安全合规),专有云接口无法审计、无法离线部署。所以这个项目把开源大模型搬进厂内一台工作站,不联网、可审计、本机部署,去解一个经典难题:强耦合的多输入多输出(MIMO)过程,控制器到底怎么整定。配套也帮你备齐了,让你真正搞懂它、在面试和答辩里讲明白:带中文注释、能读懂的代码,一份从背景一路讲到方法、公式与实验的技术说明文档(连简历描述和会被追问的面试问题都连答案写好了),还有一整套能直接做 PPT 的配图。
先说清楚,它到底在做什么
工业过程靠反馈控制器(多是 PID 回路)实时调节,而控制器的增益必须被整定:太小系统迟钝、太大震荡失稳。单回路整定是半个世纪前就解决了的例行公事;真正的麻烦出在强耦合的 MIMO 上——一台泵同时牵动好几个液位,回路之间互相打架,A 一动把 B 带偏、B 一纠又把 A 带偏。教科书里那句话很扎心:强耦合对象上,把每个回路单独整定,可能比根本不控还差。
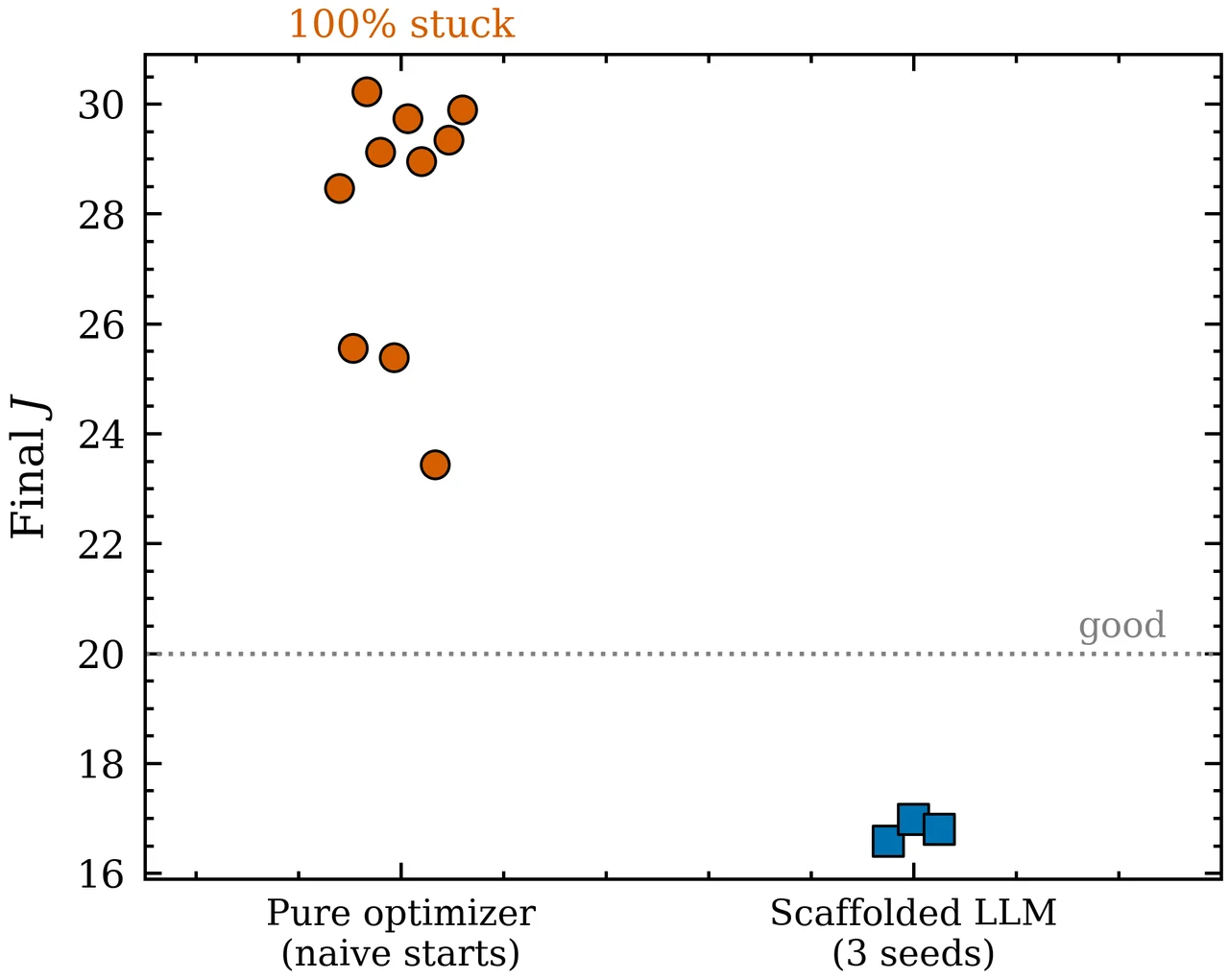
经典解法要么靠昂贵难维护的过程模型(解耦设计、MPC),要么靠纯数值优化——后者又把"目标函数、增益边界、控制器结构统统写对"的重担压回工程师身上,而强耦合对象的代价地形非凸、布满伪极小,优化结果严重依赖初始点,一个看起来合理的起点很可能一头扎进糟糕的局部解。更现实的痛点是:现成那些把 LLM 用于控制的工作,几乎清一色依赖云端专有前沿模型——这恰好撞上"数据不出厂、接口要可审计"的两条红线。
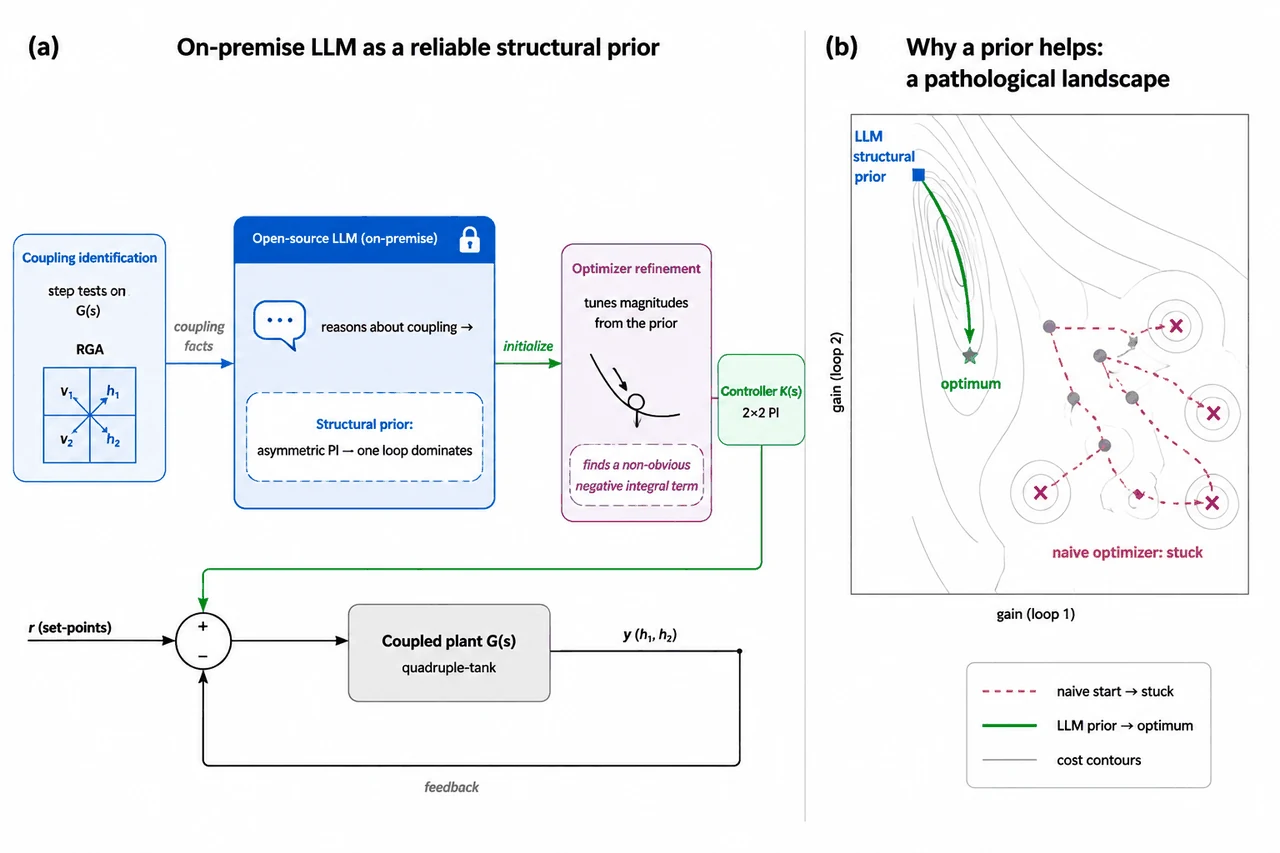
这个项目把研究锚在一个被回避、却最贴近工业现实的设定上:本机部署的开源 LLM,能不能在不联网的约束下,可靠地帮我们整定耦合控制器? 做法很巧——先对过程做阶跃测试量出输入-输出耦合矩阵,把这份耦合事实喂给本地 LLM,让它不去逐个数字搜增益,而是推理出"哪个回路该主导"这个反直觉的结构判断,把后续数值优化器直接放进正确的"盆地",优化器再在盆地里精修增益大小。整条链路里,过程数据始终留厂内、模型可审计、提示词与增益提案都人类可读。
搞懂它,你能在面试里讲清楚什么
把下面几件事吃透,面试官顺着"LLM + 工业控制"这条线问下来你都能接得住。
为什么是"结构先验",而不是"换壳的数值搜索"。 这是整个项目的灵魂论证。把控制器整定拆成两层:结构层(哪个回路主导、怎么配对、积分该正该负)是低维、离散、组合的决策,对错由对象耦合物理决定;数值层(每个增益的精确大小)是高维、连续的精修。数值优化器的强项完全落在数值层,但在结构层是"瞎的"——它手里只有标量代价值,读不懂耦合的符号结构,只能靠多撒起点碰运气。LLM 的强项天然在结构层:它见过海量控制教材、RGA 配对规则,能把一堆耦合数字翻译成"必须让一个回路主导"的工程判断。你要能讲清楚:把 LLM 误用成"换壳优化器"正是已有工作"可有可无"的根因,而把它放在结构先验的位置上,它才贡献了优化器原理上给不了的东西。
LLM 怎么从实测耦合里推出"非对称"的耦合控制结构。 强耦合四水箱的反直觉之处在于:自然配对会失稳(RGA 的 λ₁₁ 为负就提前预告了这一点),最优控制器必须让一个回路主导、另一个保持弱——这是一个非对称的结构。你要能讲清楚:本地 LLM 是怎么从阶跃测出的耦合矩阵里读出这个反直觉判断的,以及为什么这正是人类资深工程师的做法,而纯优化器看不到。
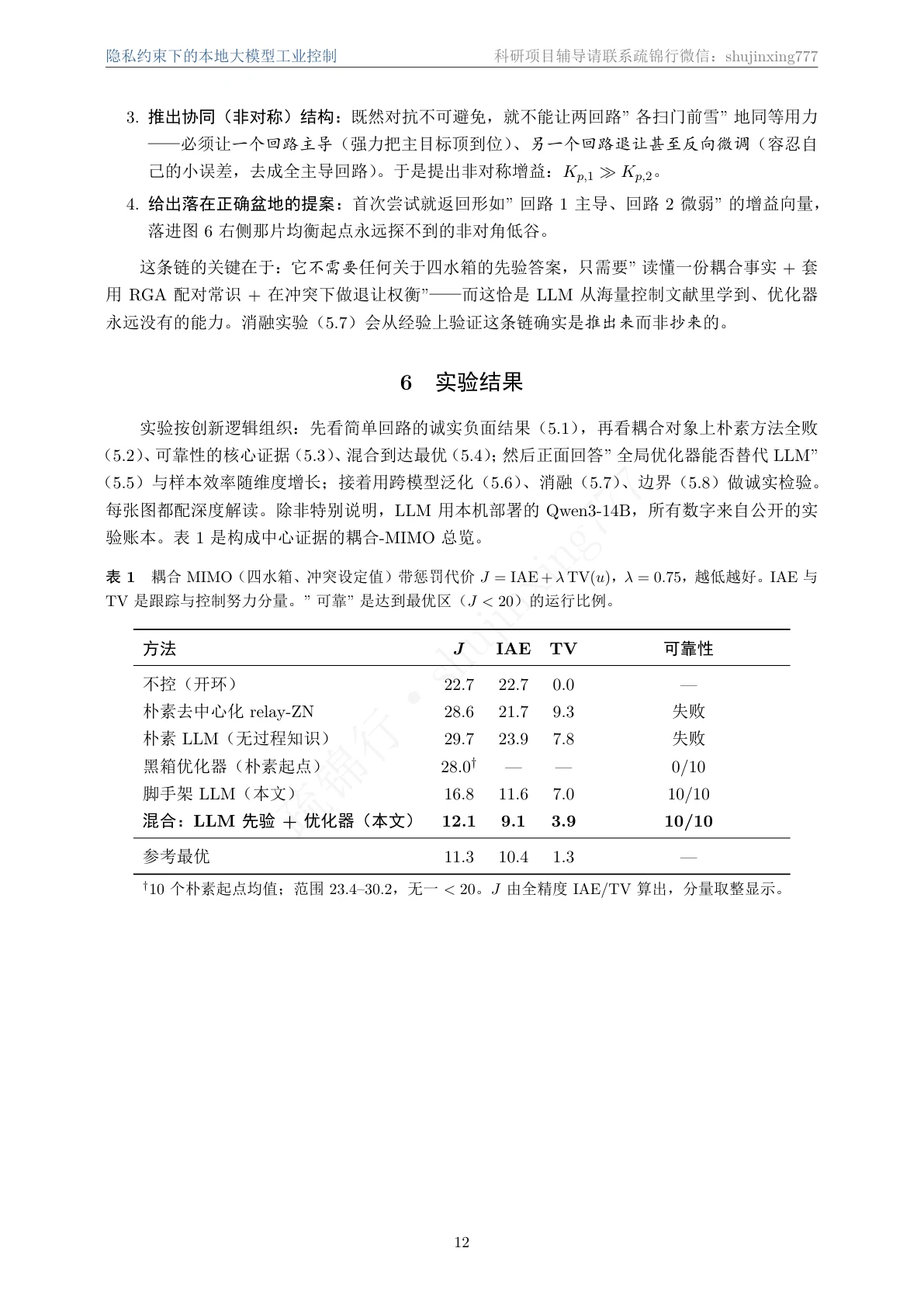
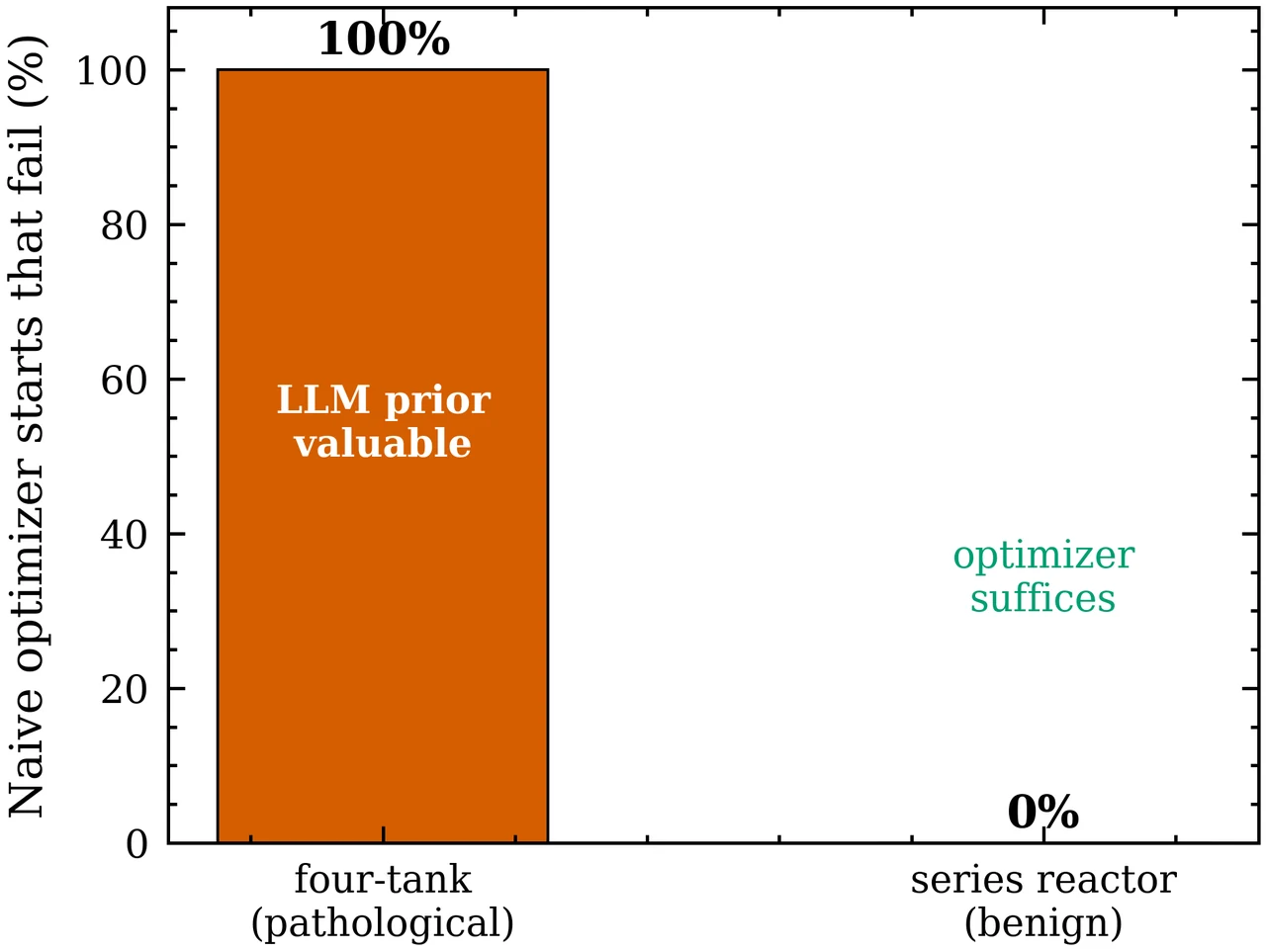
混合范式怎么取长补短、边界又划在哪。 这是项目的落点,也是它"刻意诚实"的地方。它不吹 LLM 万能:在单回路 CSTR 上坦白承认经典继电整定胜出、LLM 多余,借此立下一把不偏不倚的尺子;只有在"协调解反直觉"的病态对象上 LLM 才有用,而这条边界能用 RGA 等廉价诊断事先判定。你要能讲清楚:LLM 负责结构判断、优化器负责数值精修、一份事先量好的耦合矩阵把两者对接——以及为什么这套优势随对象维度上升而放大。
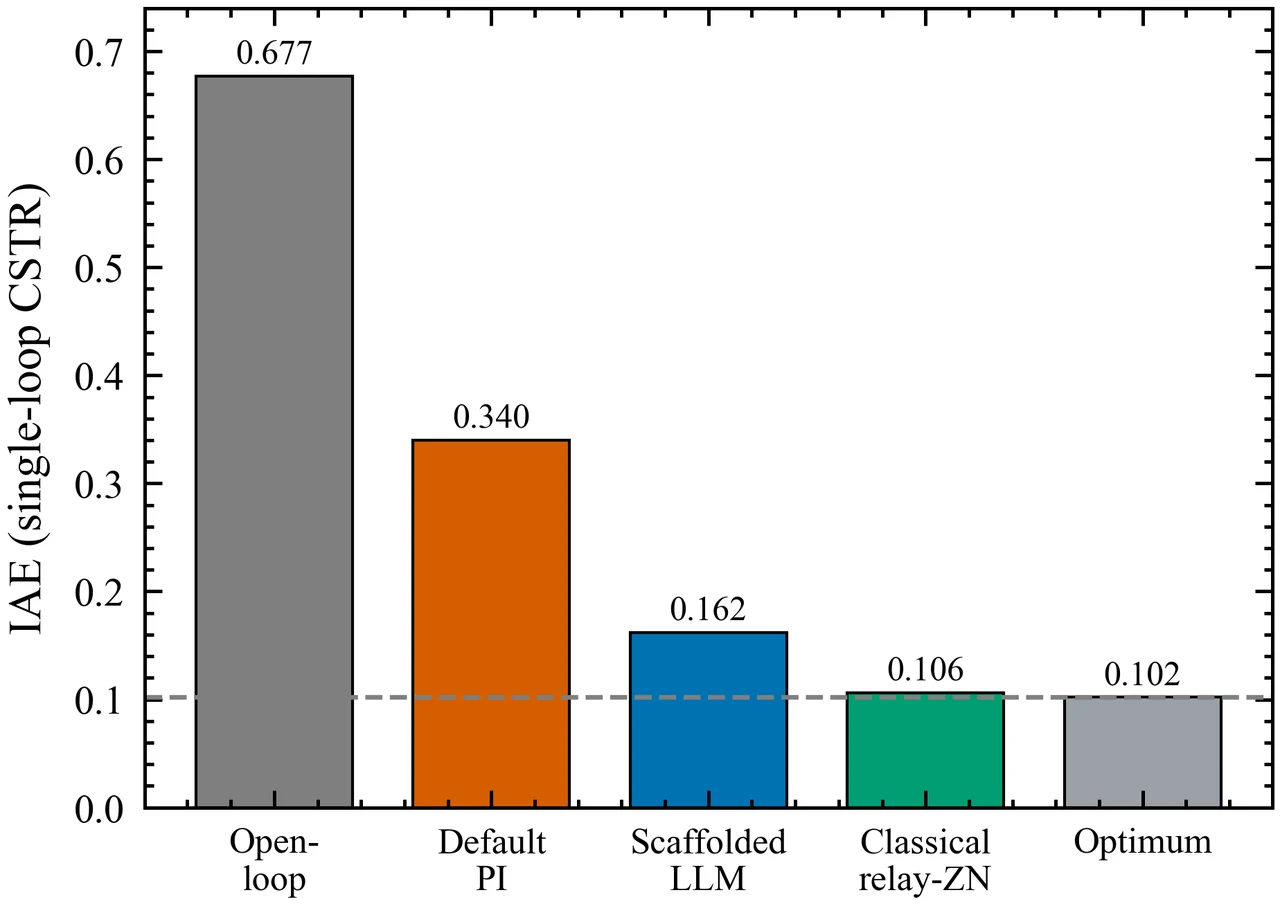
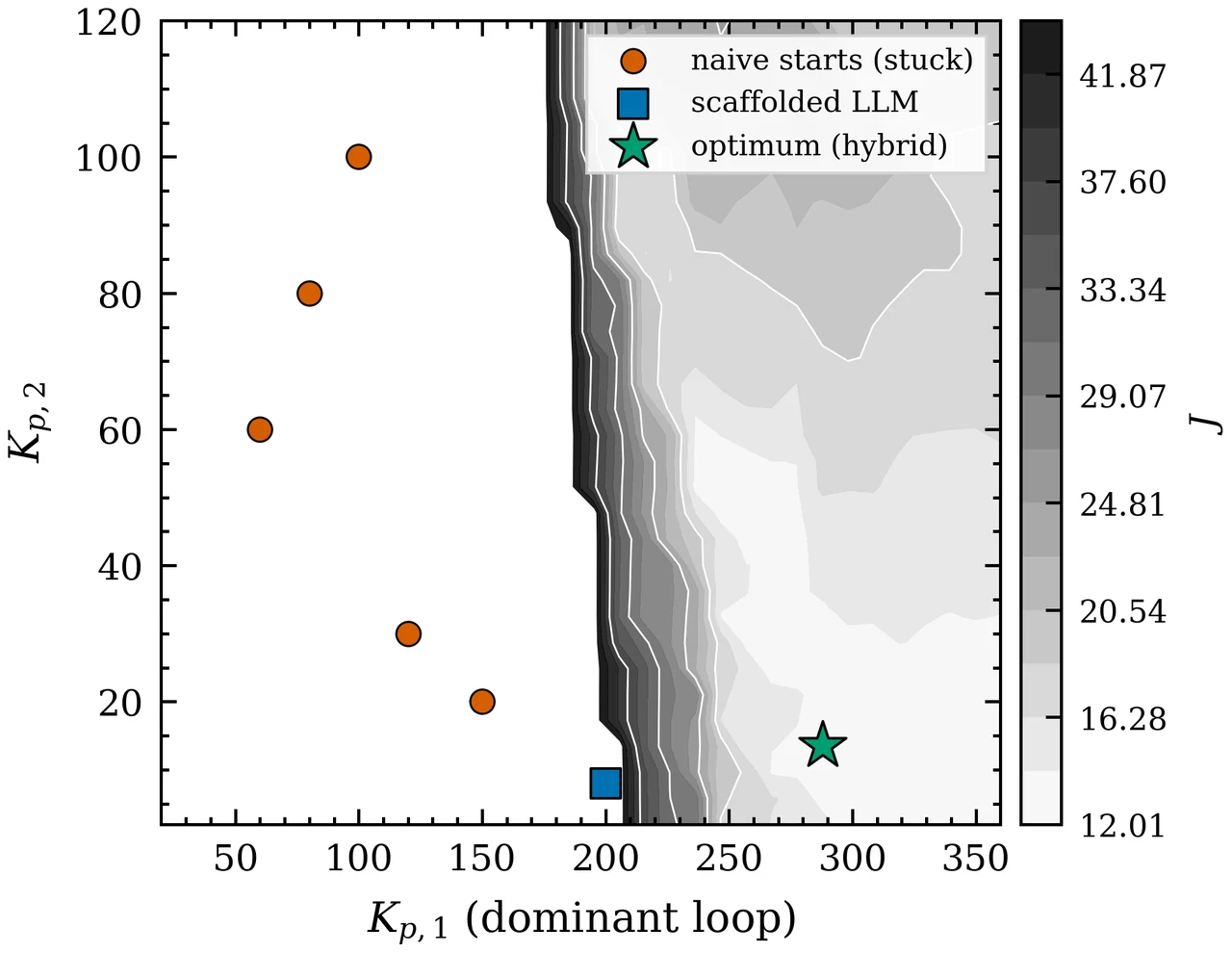
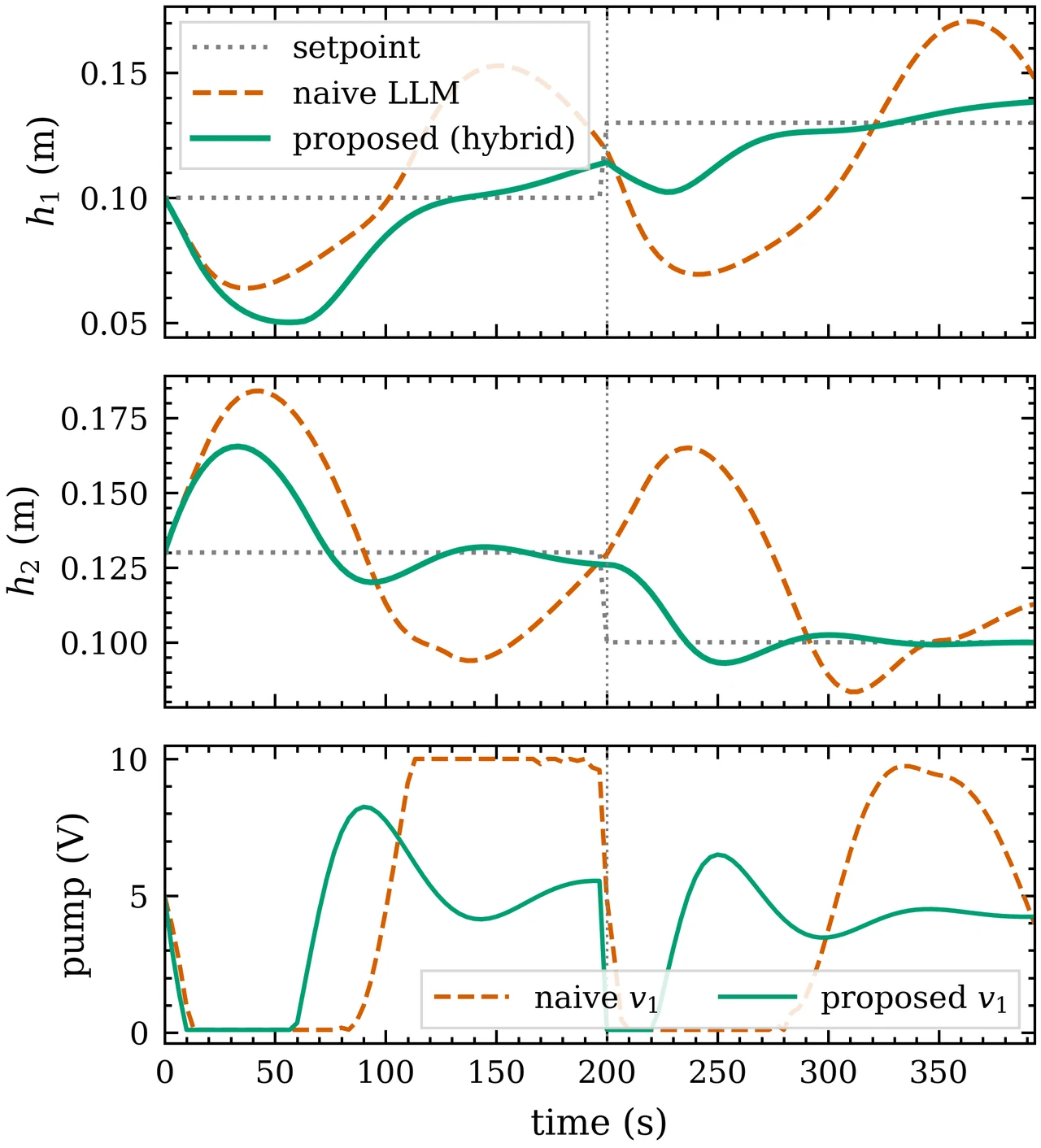
更关键的是,每张图怎么跑出来的、该怎么解读,技术文档里都讲清楚了——比如为什么良性对象上 LLM 多余、病态对象上它才不可替代,这条边界恰恰是项目最有分量的结论。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
工业现场为什么不能直接调云端大模型?本机部署开源 LLM 到底解决了什么红线问题?
你说 LLM 是"结构先验"而不是"优化器"——这两者在数学性质上有什么本质区别?怎么证明 LLM 贡献了优化器给不了的东西?
强耦合四水箱的最优控制器为什么是"非对称"的?RGA 的 λ₁₁ 为负预告了什么?
既然全局优化器也能找到最优解,那 LLM 的价值在哪?这种价值为什么会随对象维度上升而放大?
看到会愣一下?正常。配套的项目讲解资料把这个项目——从整体思路到每个流程细节、各种可能被追问的点——连参考答案都给你写好了(文档里就有 5 维度 15 道面试问答),连"经典强在哪、LLM 强在哪、边界怎么事先判定"这种判断题都帮你梳理好了。另外还有现成的两版简历描述,照着改就能写进简历;那套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。
配套资料:搞懂一个项目需要的,这里全都有
先看那份技术说明文档——从控制器整定背景、经典方法(ZN/继电/RGA/解耦/MPC)讲透,一路到本地 LLM 当结构先验、混合范式、公式与实验证据,再到边界与展望,图文并茂:


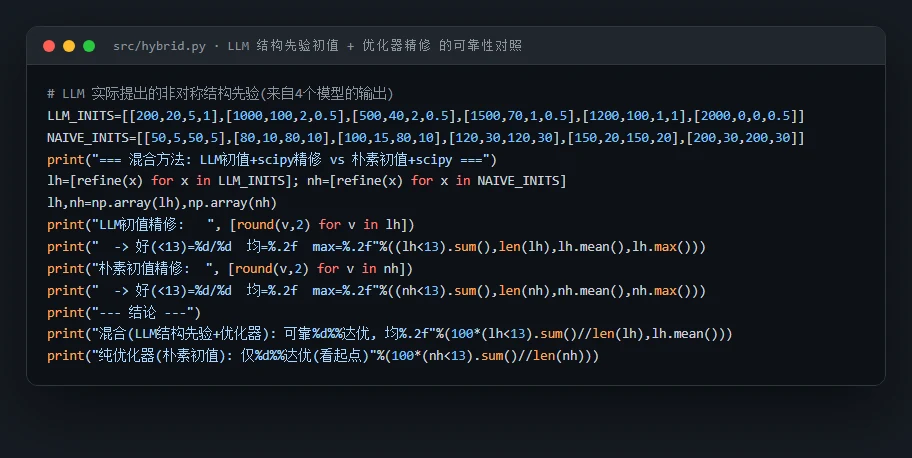
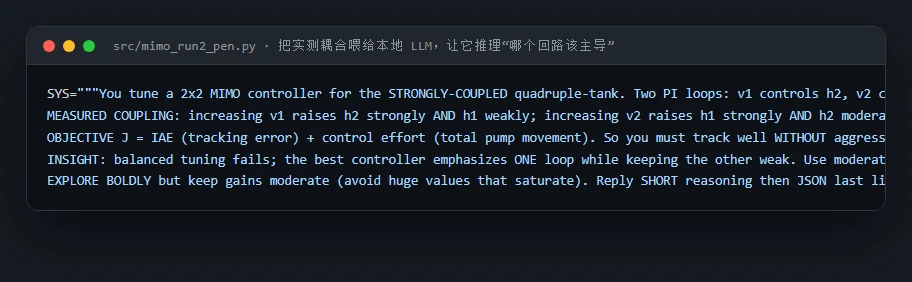
代码也给你了——关键部分都带着中文注释,帮你读懂"它到底是怎么实现的":左边是"LLM 结构先验初值 + 优化器精修"的可靠性对照(混合范式的核心),右边是把实测耦合喂给本地 LLM、让它推理结构判断的提示词主体:
还有这组图也都给你做好了,可以直接放进答辩或面试 PPT:
技术文档、项目讲解资料、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添个"大模型 + 工业落地"分量十足的项目,还是在准备面试,这个题目都接得住。专业上,计算机、人工智能、自动化/控制方向都很合适——尤其是想往工业智能、过程控制、大模型工程化落地方向走的同学。把"为什么是结构先验不是数值搜索、LLM 怎么从耦合里推出非对称结构、混合范式怎么取长补短并事先划定边界"这条完整链路真正搞懂、能讲出来,就是一个既贴近工业现实、又有方法论分量、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「隐私约束下的本地大模型工业控制:把开源 LLM 当作可靠的结构先验整定强耦合 MIMO」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。