多智能体推理为何失效:相关错误与多样性坍缩的机理剖析
“多个智能体一起投票,准确率必然更高”是自洽性采样、多智能体辩论、Mixture-of-Agents 的共同前提。本项目证明:在足够难的推理任务上,多个大模型会因共享语料与架构而犯下相关的同质错误,本应靠多样性带来的集成增益于是坍缩为零甚至变负——集成准确率反而低于最强单模型。用 1785 年的 Condorcet 陪审团定理(50% 阈值)框定“投票有益/有害”的分界,并在 AIME-2024、MATH-500、GPQA-Diamond 三个难度递增的真实基准上系统验证。
项目亮点
- ✅ AIME-2024 experiment complete: 6 models × 30 questions.
- ✅ MATH-500 experiment complete: 6 models × 500 questions.
- ✅ GPQA-Diamond experiment complete: 6 models × 198 questions.
- ✅ Multi-reviewer audit (7 MUST-FIX) resolved — see `paper/archive/reviews/main_review_v5.md`.
数据与任务
| 样本量 | AIME-2024 · MATH-500 · GPQA-Diamond · 6 模型真实作答 |
|---|---|
| 核心方法 | Condorcet 阈值框定 + Cohen's κ/同错率量化多样性坍缩 + 三基准多数投票验证 |
| 技术栈 | Python · 多模型 API · NumPy · Bootstrap CI |
如果你想找一个 LLM / Agent 味道浓、又能把"一个被所有人默认成立的前提为什么会崩"讲透的项目,这个「多智能体推理的多样性坍缩」很合适。
它切的角度很硬、也很反直觉——大家都信"智能体越多越好(more agents is all you need)",把一堆模型的答案投个票,错误互相抵消、正确彼此印证,准确率自然更高。这个项目偏要证明:在足够难的题目上,这个前提会悄无声息地反转成"智能体越多越坏"。配套也给你备齐了,帮你真正搞懂它、在面试和答辩里讲明白:带中文注释、能读懂的代码,一份从痛点讲到机理与三基准实验的 32 页技术文档,里面连简历描述和会被追问的面试问题都连答案写好了,还有一整套能直接做 PPT 的论文级配图。
先说清楚,它到底在做什么
"多个智能体一起投票,准确率必然更高"——这是自洽性采样(self-consistency)、多智能体辩论、Mixture-of-Agents 一整套主流框架默认成立的前提。直觉很诱人:每个模型各有所长,把不同视角聚合起来,随机错误会互相抵消。但这个项目从一个被长期忽视的角度切入:这个前提在难推理任务上会崩塌。当多个大模型面对足够难的题,它们并不犯彼此独立、能互相抵消的随机错误,而是因为共享训练语料和架构犯下相关的、同质化的错误——本应靠多样性带来的集成增益于是坍缩为零甚至变负:集成后的准确率反而低于其中最强的单个模型。
项目把 1785 年的 Condorcet 陪审团定理重新请回大模型集成:用单模型 50% 准确率这条阈值,精确框定"投票有益"与"投票有害"的分界线——成员准确率高于 50% 时纳入投票会提升集成(HELP 区),一旦低于 50% 纳入它反而拉低集成(HARM 区)。已有"多智能体更强"的工作,恰恰只在阈值之上的简单基准上验证过。
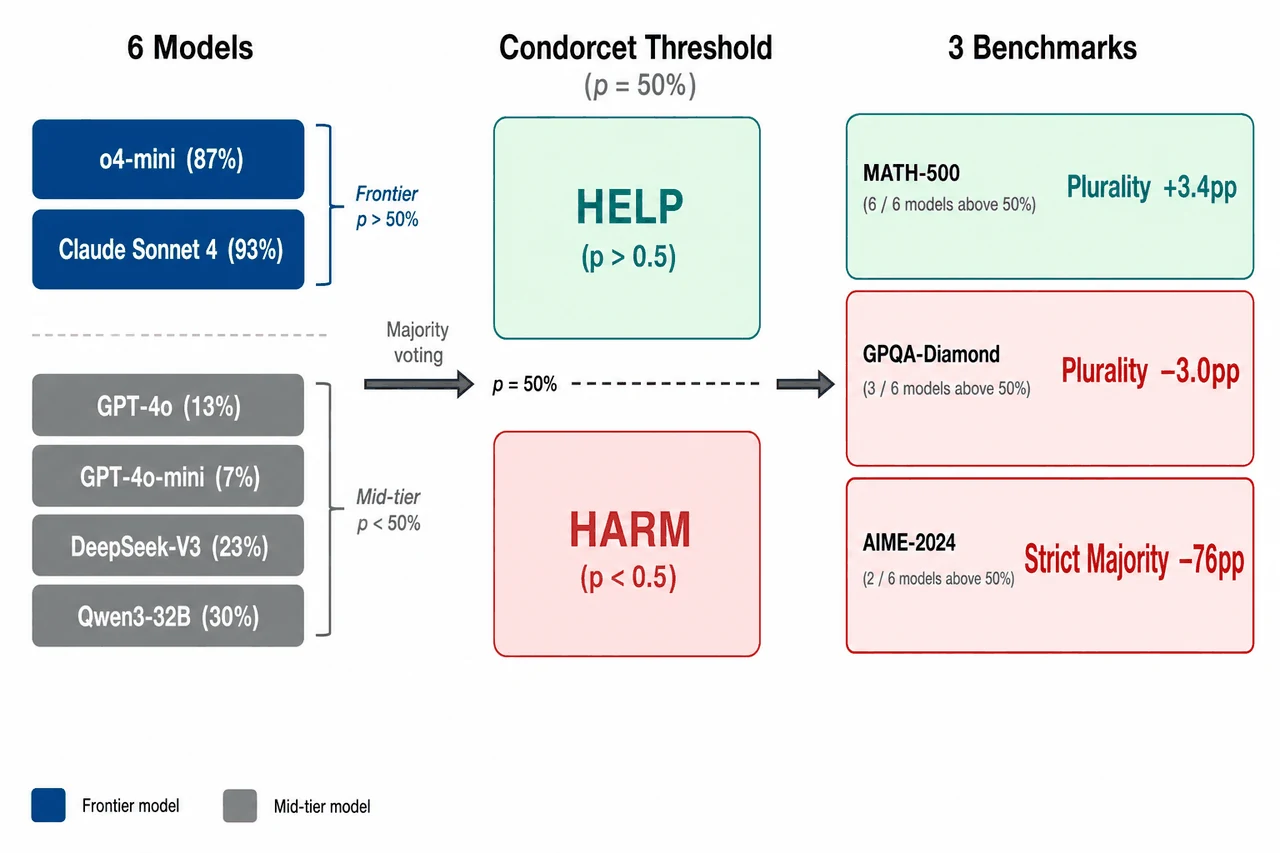
搞懂它,你能在面试里讲清楚什么
把下面几件事吃透,面试官顺着"多智能体集成为什么会反噬"这条线问下来你都能接得住。
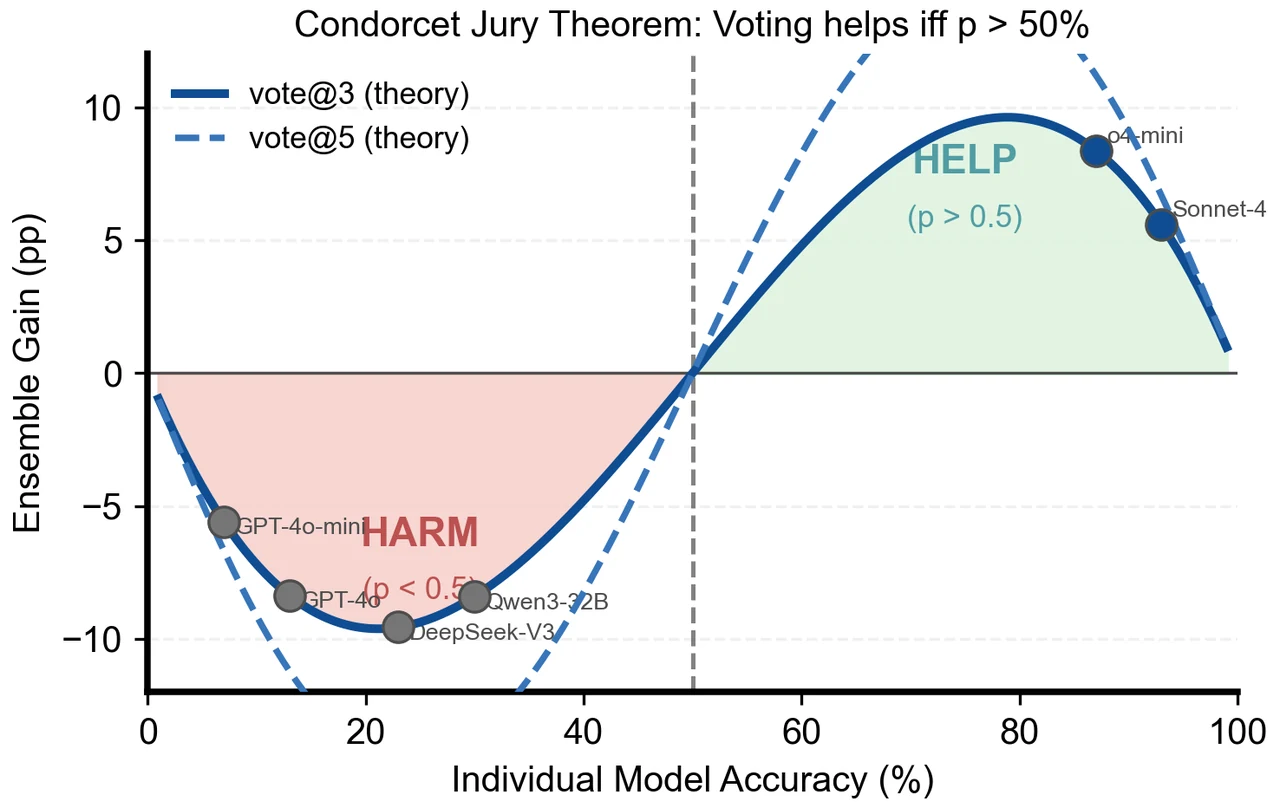
Condorcet 陪审团定理和它的独立性假设,怎么框定"投票有益"的边界。 这是整个项目的标尺。你要能讲清楚:为什么个体准确率 p>50% 时多数投票会让集成更准、p<50% 时反而更差,以及这条定理有一个致命的前提——成员错误相互独立。难任务上这个前提被打破,定理的"保证"随之失效。照着下面这张理论曲线,你能把"为什么 50% 是红线、强模型落在 HELP 区、中档模型落在 HARM 区"整条逻辑讲明白。
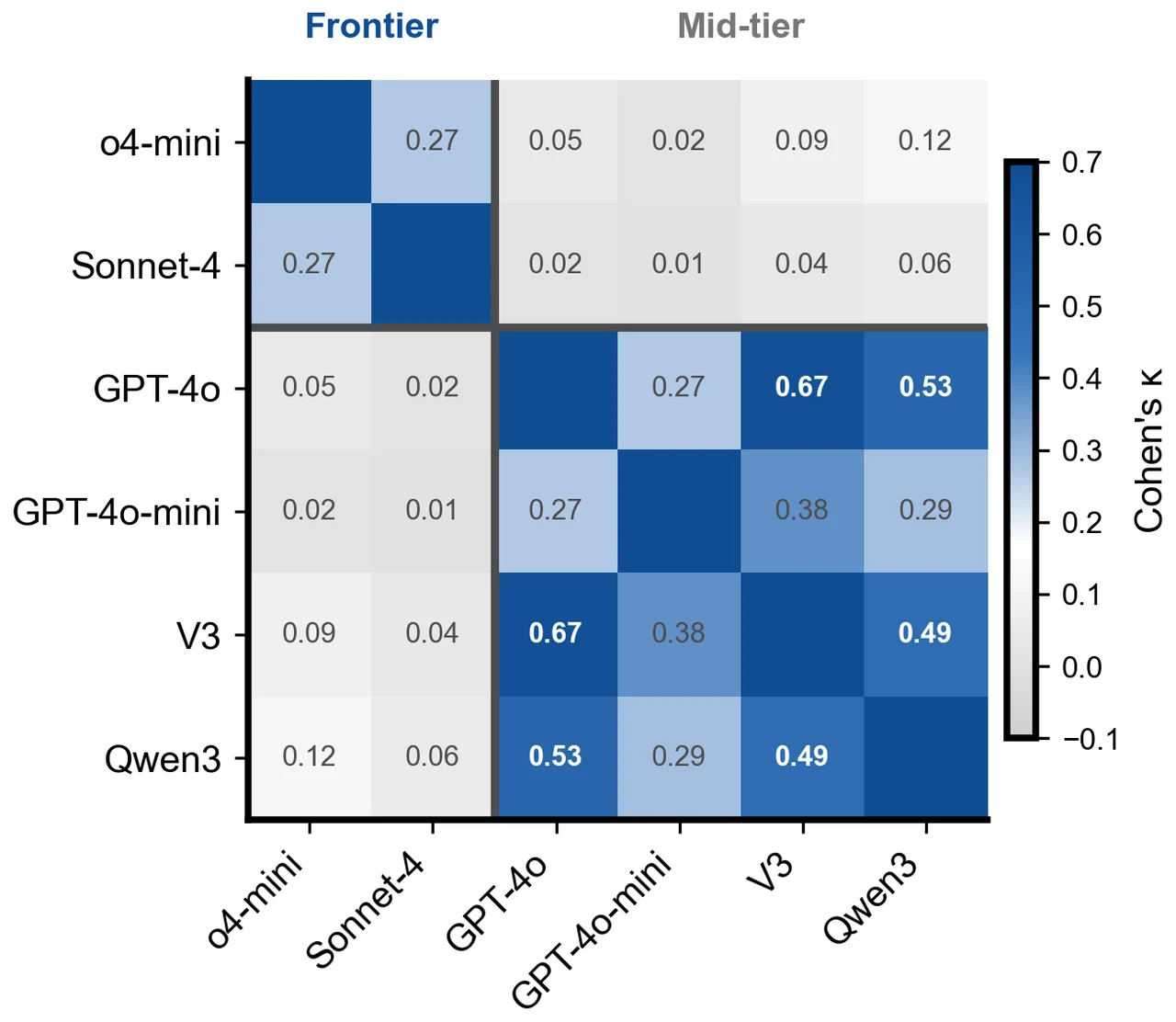
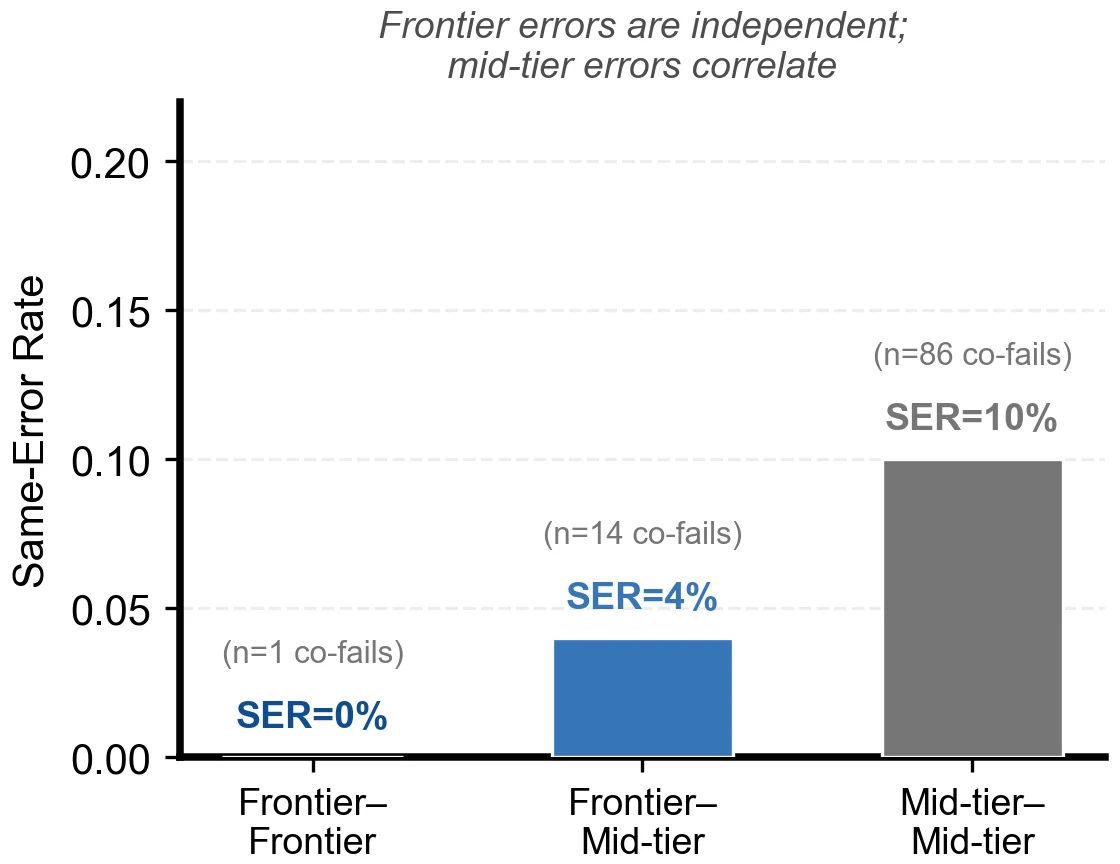
用 Cohen's κ 和同错率(SER)两把尺子,怎么把"多样性坍缩"量化出来。 这是项目最有思想含量的一点。"多样性"听起来很虚,项目把它做成两个可计算的数:Cohen's κ 度量两个模型对错模式的一致性(扣掉随机巧合后的真重叠),同错率 SER 度量两个都做错时是否给出了同一个错误答案。结论很反直觉——强模型之间错误几乎不重叠(κ 低、SER≈0)却因为各自太强、可投票的空间太小而无机可乘;中档模型之间错误反而部分相关(κ 高、SER 高),从两端共同绞杀集成增益。你要能讲清楚这两把尺子各测什么、为什么它们一起才说清了"坍缩"。
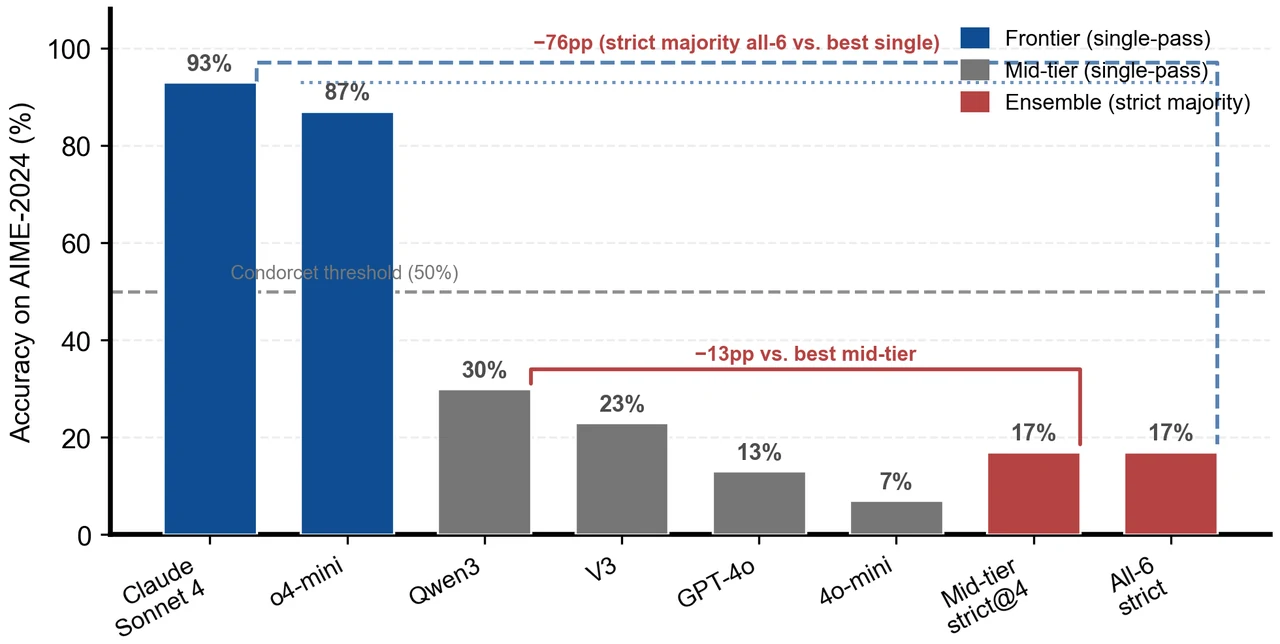
同一批模型,凭什么仅因任务难度就从"投票 +3.4pp"滑到"投票 −76pp"。 这是项目的落点。项目在三个难度递增的真实基准——AIME-2024(竞赛数学)、MATH-500(教材数学)、GPQA-Diamond(研究生科学)——上系统验证:同一批六个模型,MATH-500 上六个全部过线、全员投票 +3.4pp;GPQA 上三上三下、转为 −3.0pp 的轻微反噬;AIME 上只有两个过线,严格多数投票把最强单模型的 93% 直接砸到 17%,损失 −76 个百分点。你要能讲清楚:增益从正变负的完整光谱,恰好对应"跌破阈值的成员越来越多"。
下面这组论文级实验图也都给你做好了,可以直接放进答辩或面试 PPT:
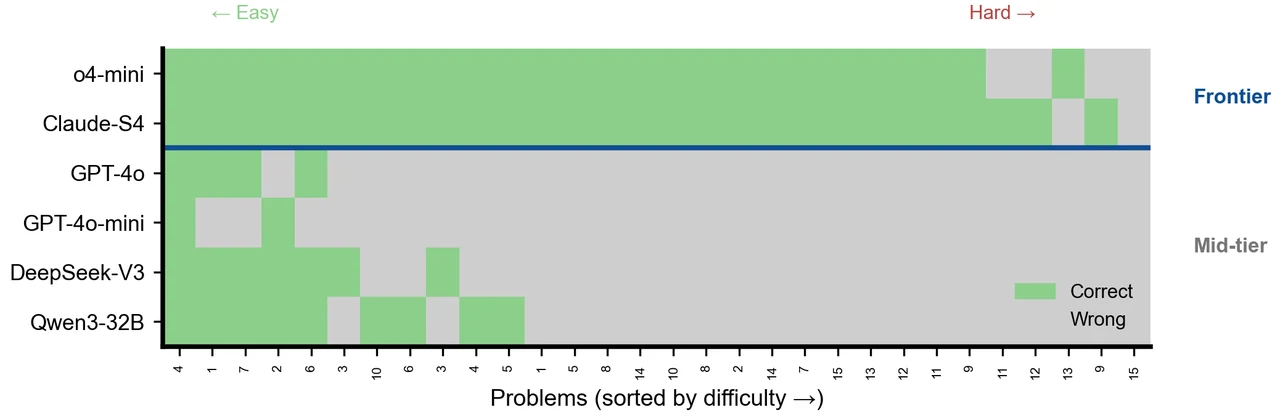
更关键的是,每张图怎么跑出来的、该怎么解读,技术文档里都讲清楚了——比如对错矩阵里为什么难题区会出现"中档模型整片同时翻红",而这恰恰是相关错误最直观的证据。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
Condorcet 陪审团定理凭什么说"投票有益"?它有一个关键假设,难任务上为什么会被打破?
你说的"多样性坍缩"具体怎么量化?Cohen's κ 和同错率分别测的是什么,为什么要用两个指标?
为什么强模型之间错误不重叠却也帮不上集成、中档模型之间错误相关又拖累集成——"两端绞杀"是什么意思?
同一批六个模型,凭什么在 MATH-500 上投票 +3.4pp、在 AIME 上 −76pp?这说明部署多智能体投票前应该先做什么?
看到会愣一下?正常。配套的项目讲解资料把这个项目——从整体故事线到每个机理细节、各种可能被追问的点——连参考答案都给你写好了(15 道面试问答),连"为什么这不是否定多智能体、而是刻画它在哪成立在哪反噬"这种判断题都帮你梳理好了。另外还有现成的简历描述(两版),照着改就能写进简历;那套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。
配套资料:搞懂一个项目需要的,这里全都有
先看那份 32 页技术说明文档——从"多智能体投票为什么被寄予厚望"的痛点,讲到 Condorcet 阈值、κ 与同错率的机理量化,再到三个难度基准上的完整实验光谱,图文并茂、每张图后紧跟整段中文深度解读:

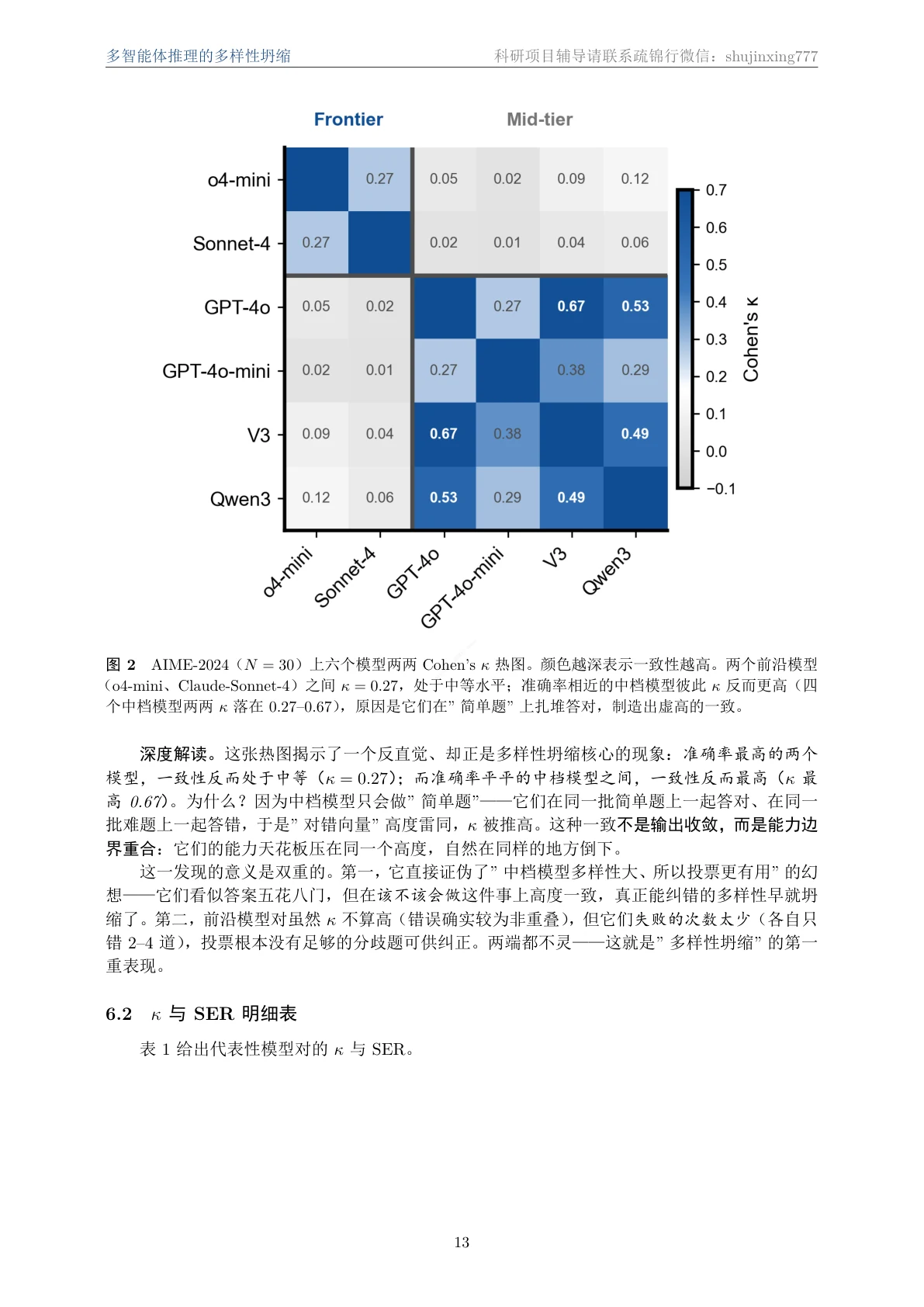

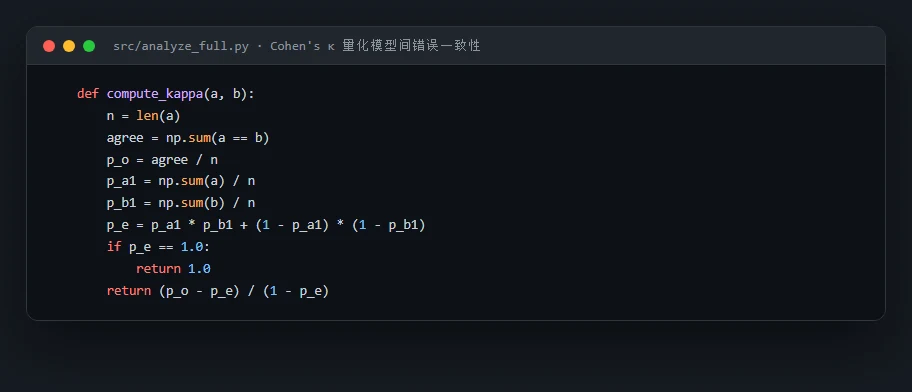
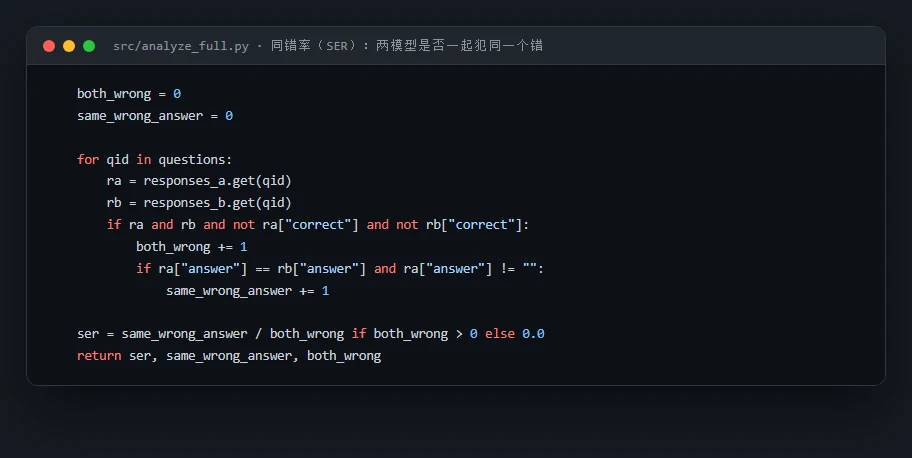
代码也给你了——关键部分都带着中文注释,帮你读懂"多样性坍缩到底是怎么算出来的":左边是 Cohen's κ 怎么扣掉随机巧合度量错误一致性,右边是同错率怎么判断两个模型是否一起犯了同一个错:
技术文档、项目讲解资料、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添个有大模型分量的项目,还是在准备面试,这个题目都接得住。专业上,计算机、人工智能、数据科学方向都很合适——尤其是想往 LLM / Agent、多智能体系统、模型评测方向走的同学。它不需要你训练任何大模型,吃的是"机理与方法论"这碗饭:把"Condorcet 定理怎么框定边界、κ 与同错率怎么量化多样性坍缩、三个难度基准上增益怎么从正变负"这条完整链路真正搞懂、能讲出来,就是一个既有思想深度、又撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「多智能体推理为何失效:相关错误与多样性坍缩的机理剖析」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。