少即是多:机制感知的高效多智能体推理
多智能体推理很贵,盲目堆智能体收益递减。这个项目把问题反过来问:到底在什么机制区间下,对一道题多采样、多智能体才真正划算?用 vote-K 采样饱和、推理多样性塌缩(RDC)、效率-准确率帕累托前沿三个可测量的诊断,得出一条可操作的部署原则——少即是多。
数据与任务
| 样本量 | AIME / GPQA 等推理 benchmark · 多模型多次采样 · Wilson 95% 置信区间 |
|---|---|
| 核心方法 | vote-K 采样饱和 + 推理多样性塌缩 RDC + 效率-准确率帕累托前沿 + 自适应投票 |
| 技术栈 | Python · 多模型 API · 统计诊断 |
如果你想找一个 LLM / Agent 味道浓、又能把"多智能体推理到底值不值"这件事讲到有数据、有机制、有判断的项目,这个「高效多智能体推理框架」很合适。
它的切入角度很犀利——现在大家默认"多上几个智能体、多采样几次准确率就会涨",但算力是要花真金白银的。这个项目不跟风堆智能体,而是冷静地问一句:到底在什么机制区间下,多采样、多智能体才真的划算? 配套也帮你备齐了,让你真正搞懂它、在面试和答辩里讲明白:带中文注释、能读懂的代码,一份从背景一路讲到形式化定义与实验的 34 页技术文档(连简历描述和会被追问的面试问题都连答案写好了),还有一整套能直接做 PPT 的配图。
先说清楚,它到底在做什么
多智能体推理(让多个智能体各采样一次、再投票或辩论出答案)这两年迅速成了默认策略,几乎成了"想让模型更准就多堆几个"的条件反射。但这里藏着一笔长期被掩盖的算力账:每多一个智能体、每多采样一次,token 成本就线性上涨,而准确率的提升却收益递减——尤其当底座换成强推理模型(LRM)之后,多采样的边际增益会迅速耗尽。
这个项目要回答的,正是这个被绕过去的真问题:不是"多智能体有没有用",而是"在什么机制区间下加采样才有用、用到第几次就该收手"。 它把这件事拆成三个可测量的诊断:vote-K 采样饱和点、推理多样性塌缩(RDC)、效率-准确率帕累托前沿。三个诊断串起来,落成一条可操作的部署原则——少即是多。
搞懂它,你能在面试里讲清楚什么
把下面几件事吃透,面试官顺着"多智能体推理效率"这条线问下来你都能接得住。
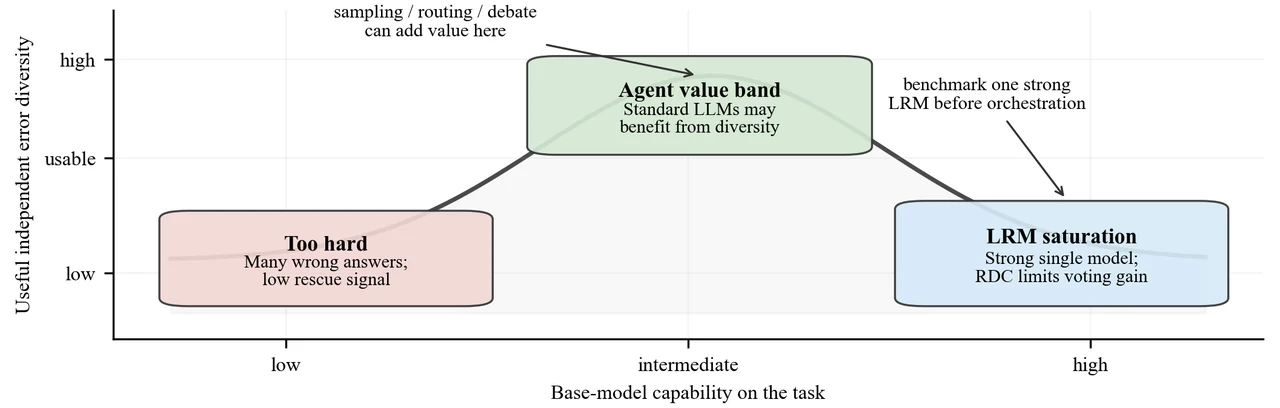
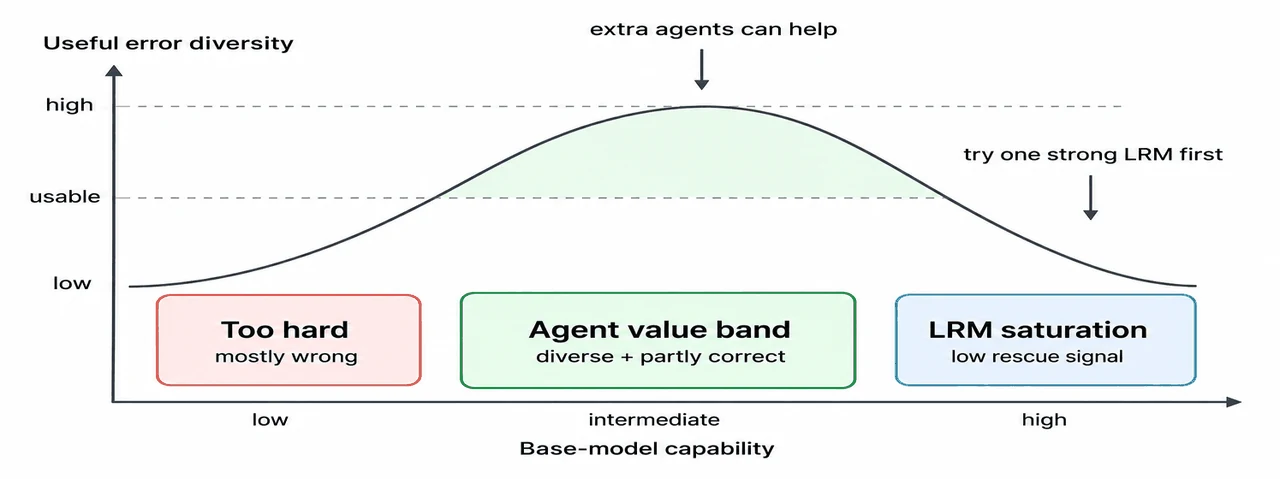
采样饱和:vote-K 往往 K=3 就触顶,再加采样只烧 token 不涨分。 这是项目的第一块实证基石。你要能讲清楚:vote-K(采 K 个答案做多数投票)的准确率曲线,会在很小的 K(实验里 R1 在 K=3)处拐成一条水平线——第 4 次到第 7 次采样没救回任何一道新题,token 却翻倍地烧。更反直觉的是:当底座模型太弱、错误答案占多数时,多采样反而会把错误"投得更实",准确率不增反降。这一条直接戳破了"多采样总是更好"的默认假设。
推理多样性塌缩(RDC):怎么不重训、不靠标签就诊断"采样还有没有救"。 这是项目最有思想含量的一点。强模型为什么更早饱和?因为多次采样之间高度相关、独立错误多样性塌缩了——大家都对就投不出新东西,大家都错也只会一起错。项目用裸一致率 + Cohen's κ(去掉随机猜测基线后的一致度)来量化这种塌缩,完全不需要金标准、不用重训模型就能算出来,是个可在线监控的退化信号。你要能讲清楚:为什么用裸一致率而不只用 κ、为什么 RDC 高就意味着"再采样也救不回"。
效率-准确率帕累托前沿:怎么用它指导算力预算怎么花。 这是项目的落点。一旦把 token 成本搬上横轴,整张"性价比地形"就摊开了:强 LRM 单次调用落在左上角(高准确率、个位数 K 的 token),弱模型堆采样被甩到右下(token 多一个数量级、准确率却低得多)。你要能讲清楚:cost-per-correct(每答对一题的成本)这个度量、为什么"换更强底座"是比"多采样"更高一阶的决策,以及固定预算下该怎么把算力挪到答对题量最多的那条路线上。
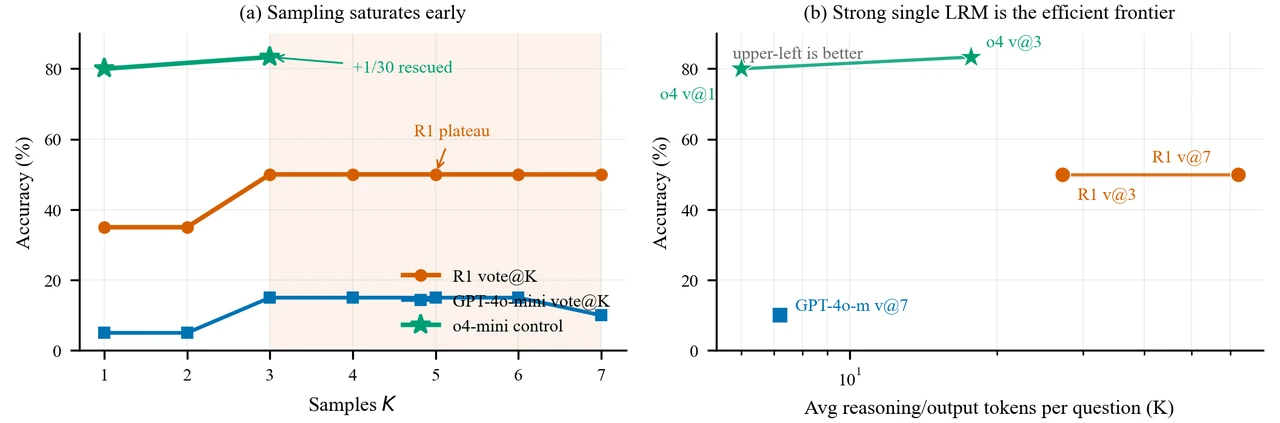
更关键的是,每张图怎么跑出来的、该怎么解读,技术文档里都讲清楚了——比如为什么强模型反而更早饱和、为什么弱模型加采样会越投越错。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
你说"多采样会饱和",那饱和点 K 取决于什么?为什么强模型反而更早饱和?
推理多样性塌缩(RDC)具体怎么算?为什么它不需要金标准、不用重训就能诊断?
帕累托前沿和 cost-per-correct 怎么指导"这笔算力预算到底该加采样还是换模型"?
看到会愣一下?正常。配套的项目讲解资料把这个项目——从整体机制到每个形式化定义、各种可能被追问的点——连参考答案都给你写好了(技术文档里专门有"面试问答专题 5 维度 17 题"),连"什么时候多智能体仍然保值"这种判断题都帮你梳理好了。另外还有现成的简历描述(学术完整版 + 面试精简版两版),照着改就能写进简历;那套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。
配套资料:搞懂一个项目需要的,这里全都有
先看那份 34 页的技术说明文档——从"多智能体为什么流行"的背景、被忽视的算力账,一路讲到 vote-K、RDC、帕累托前沿的形式化定义,再到成本模型与逐项实验结果,图文并茂:



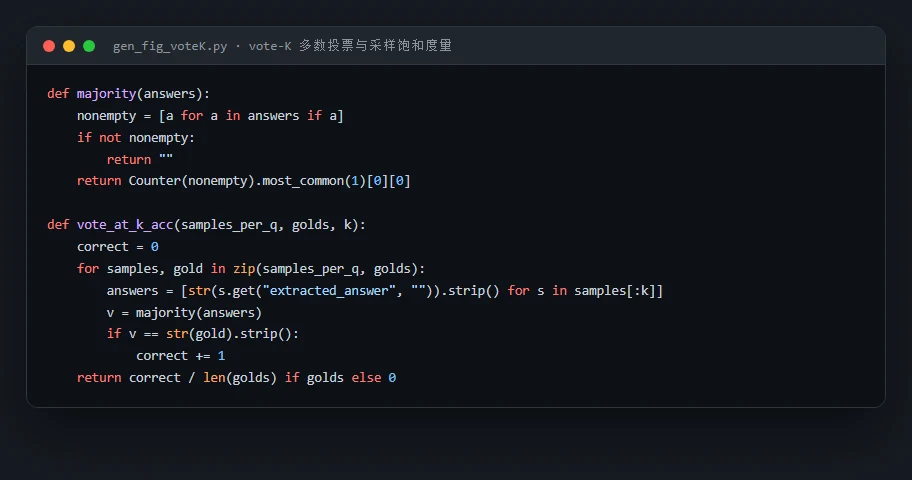
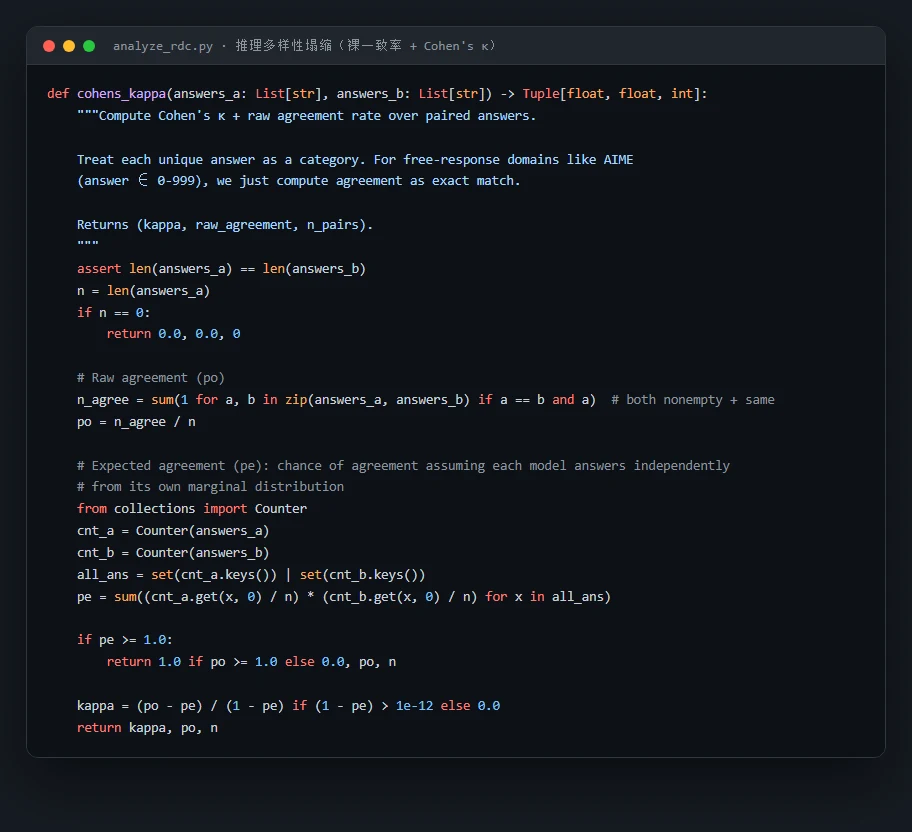
代码也给你了——关键部分都带着中文注释,帮你读懂"它到底是怎么实现的":左边是 vote-K 多数投票与采样饱和的度量,右边是推理多样性塌缩(裸一致率 + Cohen's κ)的计算:
技术文档、项目讲解资料、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添一个有方法论分量又紧跟前沿的项目,还是在准备面试,这个题目都接得住。专业上,计算机、人工智能、数据科学方向都很合适——尤其是想往大模型 / Agent、推理与对齐、高效推理与系统方向走的同学。它的好处是:不靠堆算力堆参数,而是用三个可测量的诊断把"多智能体到底值不值"讲出机制、讲出判断。把"采样为什么会饱和、多样性塌缩怎么不靠标签就测出来、算力预算怎么按帕累托前沿来花"这条完整链路真正搞懂、能讲出来,就是一个既前沿、又有思辨深度、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「少即是多:机制感知的高效多智能体推理」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。