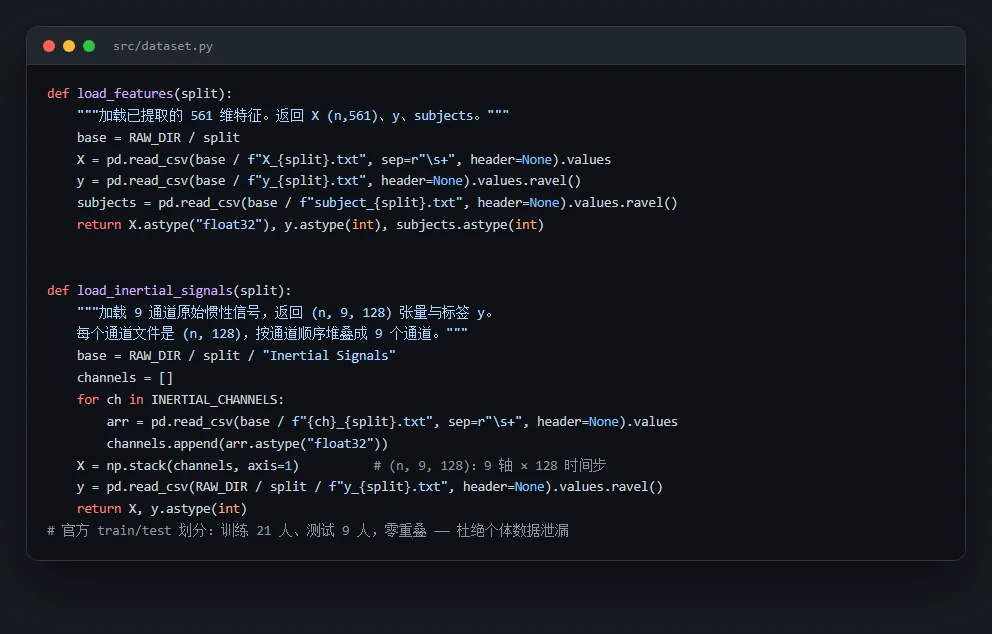
基于可穿戴传感器的人体活动识别与康复监测
用手机和手环里的惯性传感器(加速度+陀螺仪),自动识别走路、上下楼、坐、站、躺六种日常活动,服务运动量统计与居家康复监测。手工特征 vs 深度学习两条路线对比,受试者独立评测更贴近真实泛化。
项目亮点
- LogisticRegression:标准化后的 561 维时频特征上的多类线性分类器,强基线。
- RandomForest:561 维特征上的树集成(300 棵),无需标准化、抗噪。
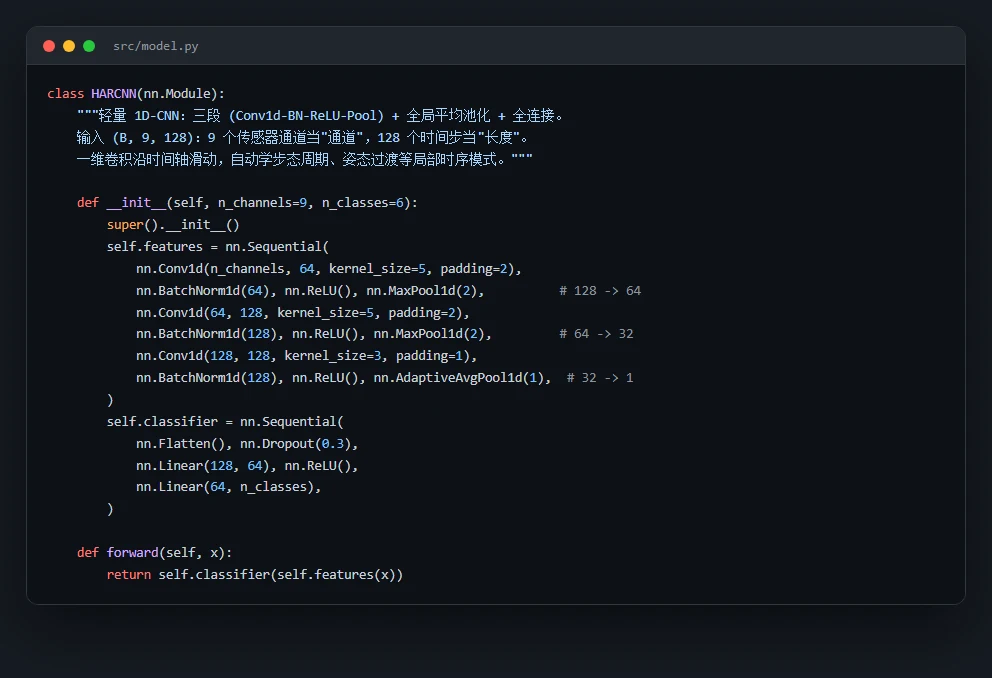
- 1D-CNN(HARCNN):直接吃 9 通道×128 原始惯性信号,三段 Conv1d-BN-ReLU-Pool + 全局平均池化,Adam/lr=1e-3/20 轮/batch=64,CUDA 加速。
- `项目流程图.png`:端到端六阶段流水线(信号采集→滑窗→两套表示→三类模型→多指标评估→康复应用)。
如果你想找一个能写进简历、面试又能讲得透的 AI 项目,这个「用手机和手环识别人在做什么」的题目会很合适——它落在可穿戴、康复、智能硬件这些热门赛道上,但又不玄乎,每一步都看得见、讲得清。
配套也都给你备齐了,帮你真正搞懂它、在面试和答辩里讲明白:带中文注释、能读懂的代码,一份从研究背景讲到每步实现的技术文档,一份把面试可能追问的点连参考答案都写好的问答文档,还有一整套可以直接拿去做 PPT 的配图。
先说清楚,它到底在做什么
你每天揣在兜里的手机、戴在手上的手环,里面都有惯性传感器——加速度计感知你动得多快,陀螺仪感知你怎么转动。人在走路、上楼、坐下时,这些传感器读出来的数值各不相同。这个项目要做的,就是让机器只看这串数值,就能判断出「这个人此刻在做什么」。
为什么值得做?因为它直接接得上真实场景:康复训练里要统计病人今天走了多少步、爬了几层楼、坐了多久;老人看护里要知道老人是正常活动还是长时间躺着不动。把活动自动识别出来,这些事才谈得上自动化。
项目用的是公开的 UCI HAR 数据集——30 个人、6 类活动、上万个滑窗样本,是这个领域最经典的基准。难点在于:传感器读数是一串杂乱的波形,不是现成的标签。怎么把这串波形变成「走路/坐着」的判断,正是项目要解决的。
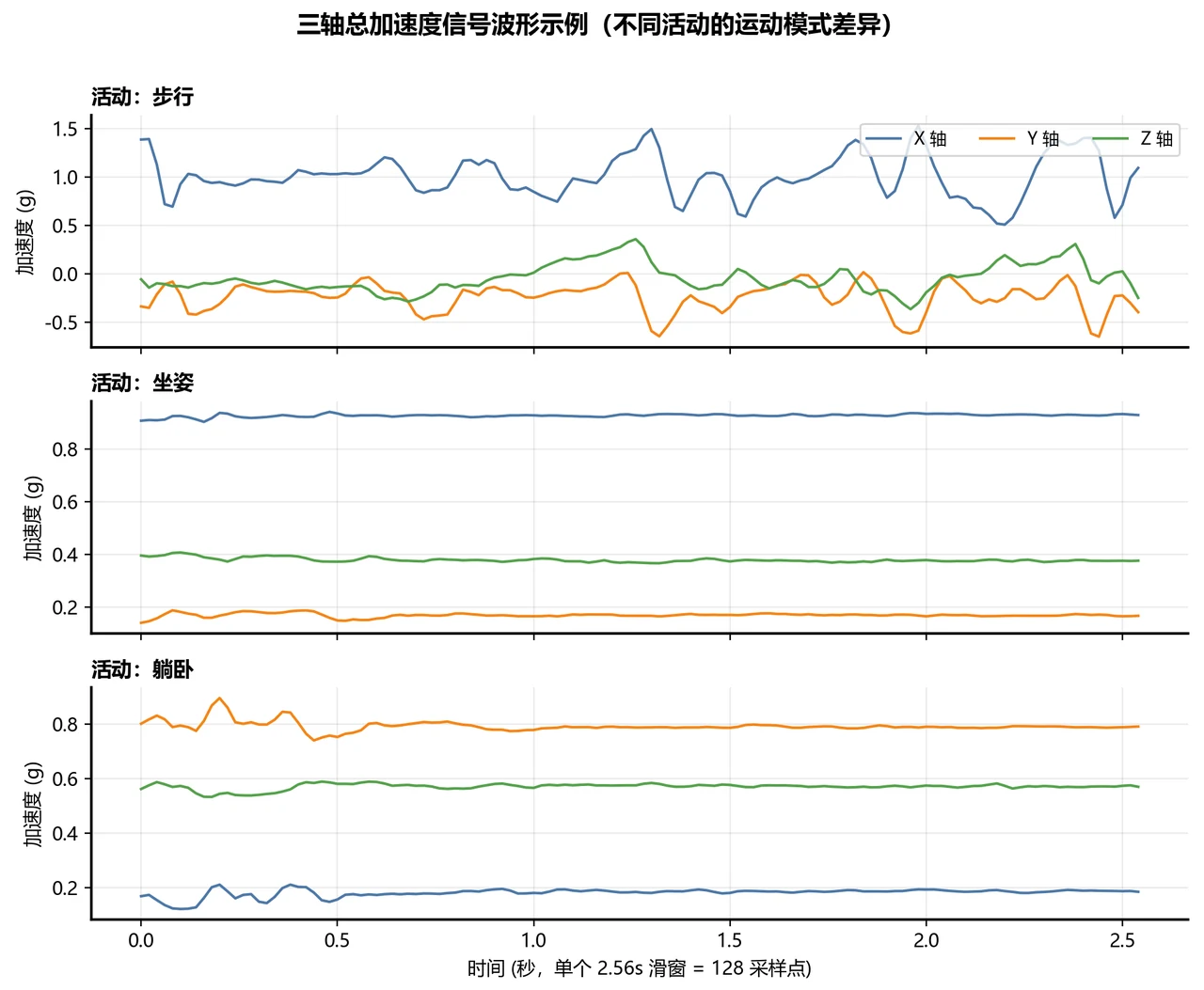
这个项目最大的巧思,是同一件事用两条完全不同的技术路线去做,再摆在一起对比:
- 手工特征路线:先靠领域知识,从波形里算出 561 个统计量(均值、方差、频谱能量……),把一段信号压成一个特征向量,再喂给逻辑回归、随机森林这类经典分类器。
- 深度学习路线:不做人工特征,直接把 9 轴原始时序信号丢给一个 1D-CNN,让网络自己沿时间轴滑动卷积、端到端地学出该关注什么。
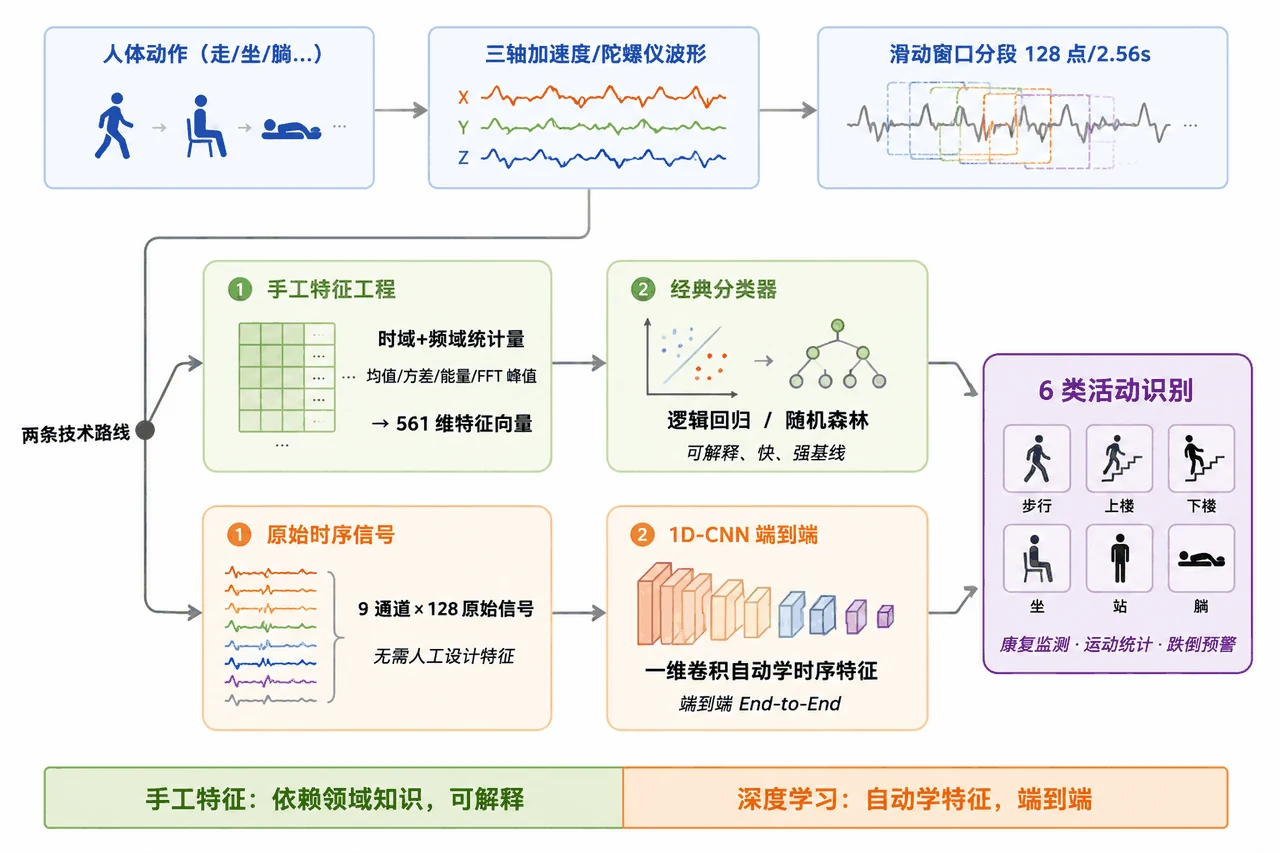
搞懂它,你能在面试里讲清楚什么
这才是这个项目对你最大的价值。把下面几件事吃透,面试官顺着项目往下追问时,你都能从容接住。
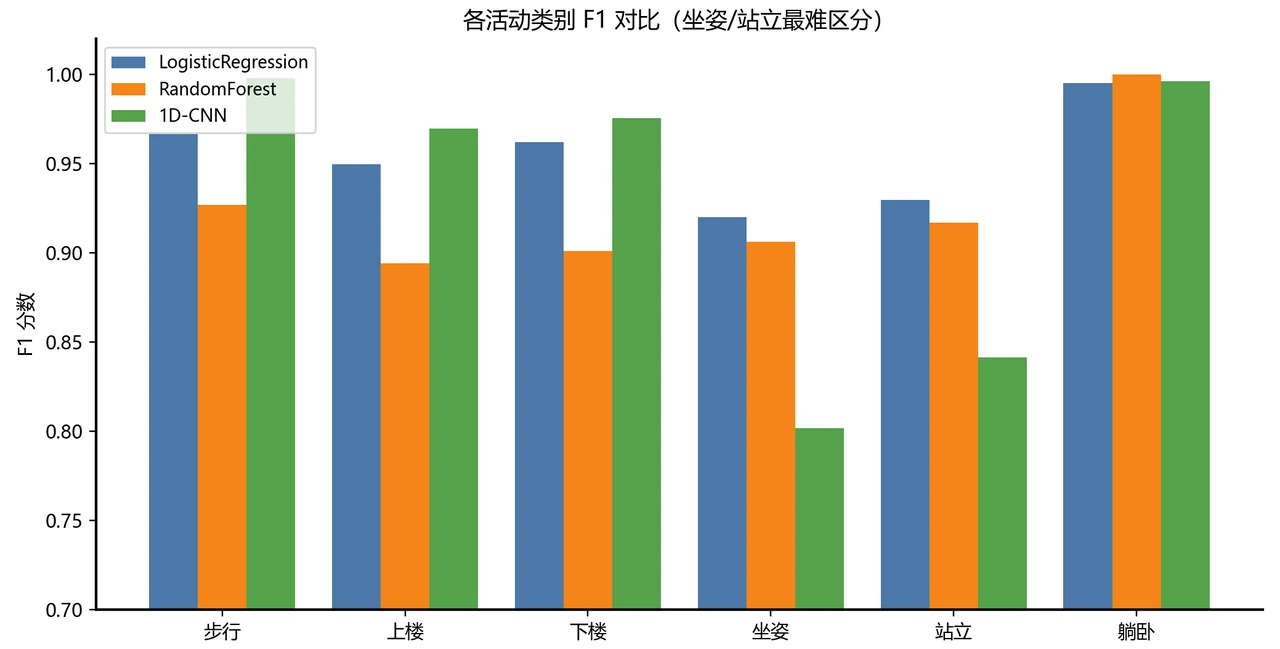
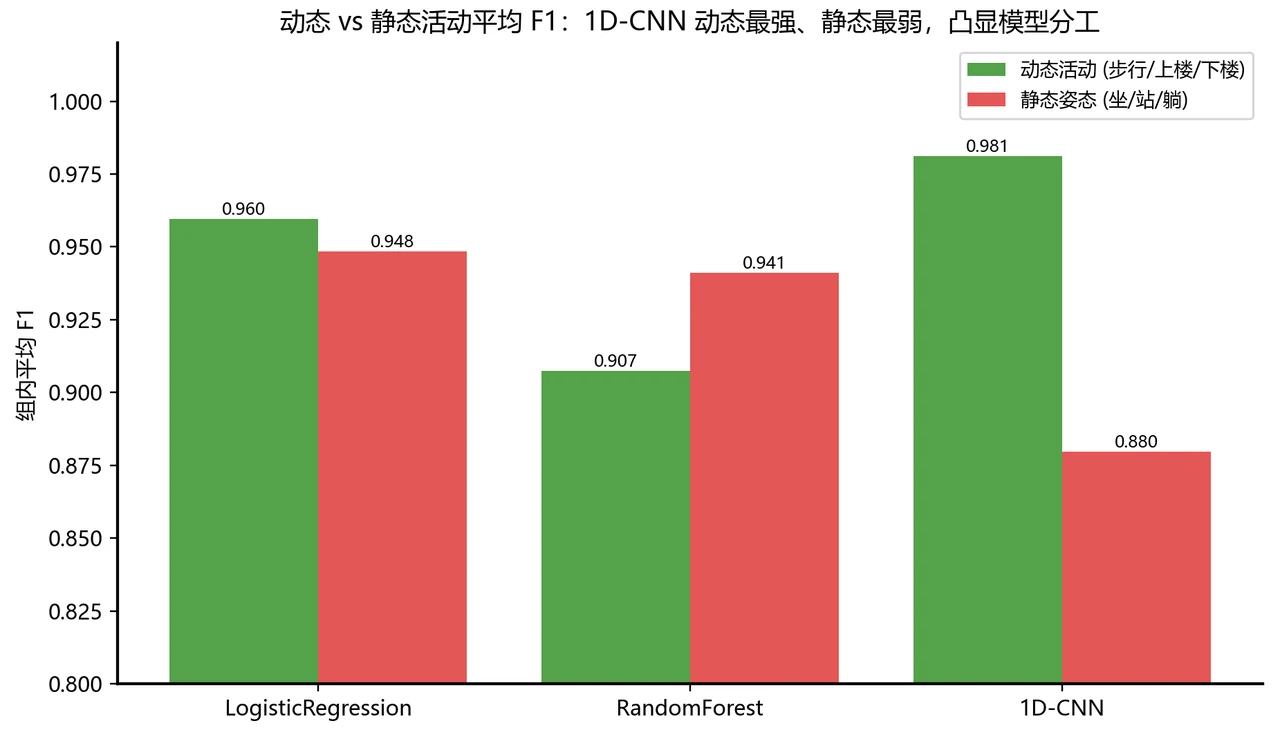
手工特征 vs 端到端深度学习,到底怎么取舍。 这是全项目最值得讲的一条主线。结论很有意思也很反直觉:在这份数据上,最简单的逻辑回归反而整体最准——因为那 561 个手工特征已经把信号里的精华提炼得很到位,好特征 + 简单模型,胜过让深度模型从零硬学。而 1D-CNN 的价值在另一处:它在走路、上下楼这些动态活动上接近完美(F1 全部超过 0.97)。你能借这个对比讲清楚一个成熟工程师才有的判断——不是越深的模型越好,要看数据给了你什么。
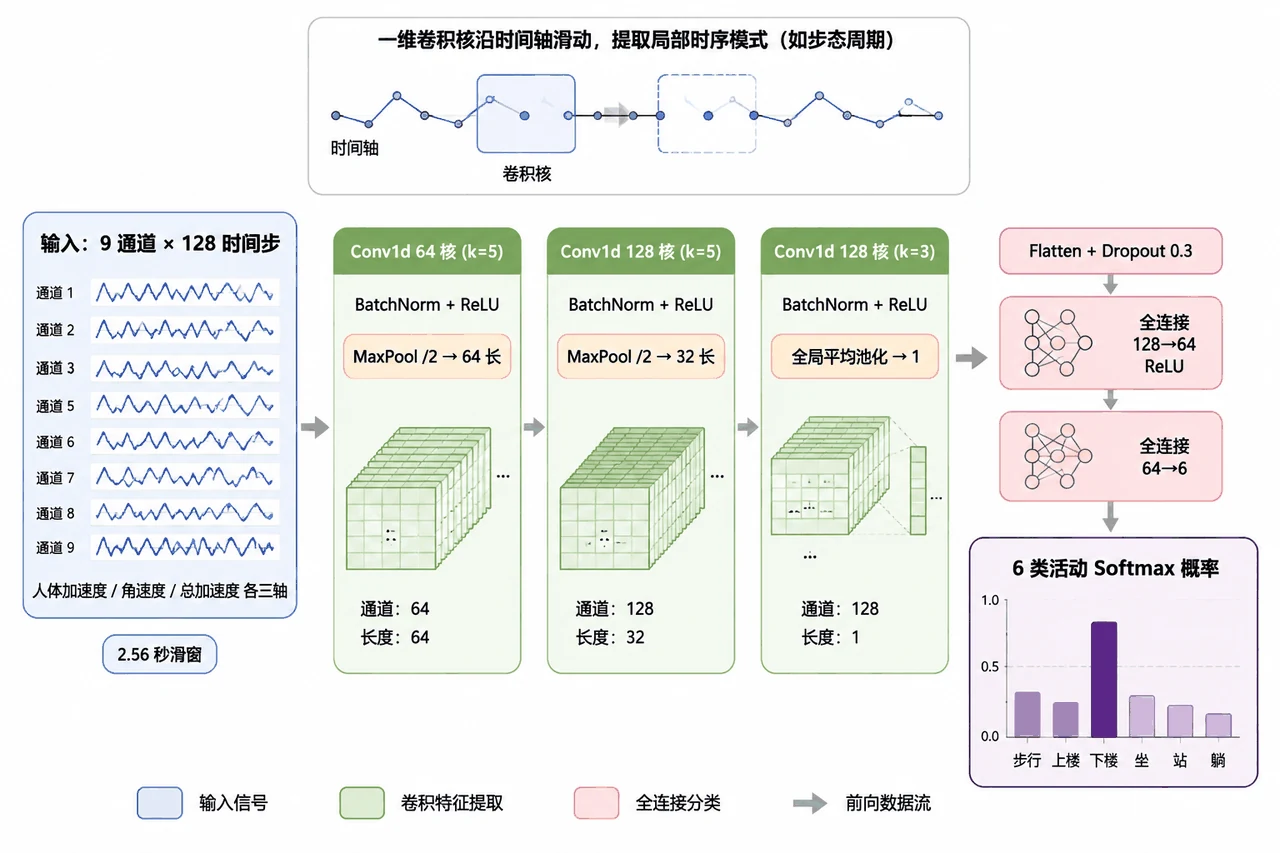
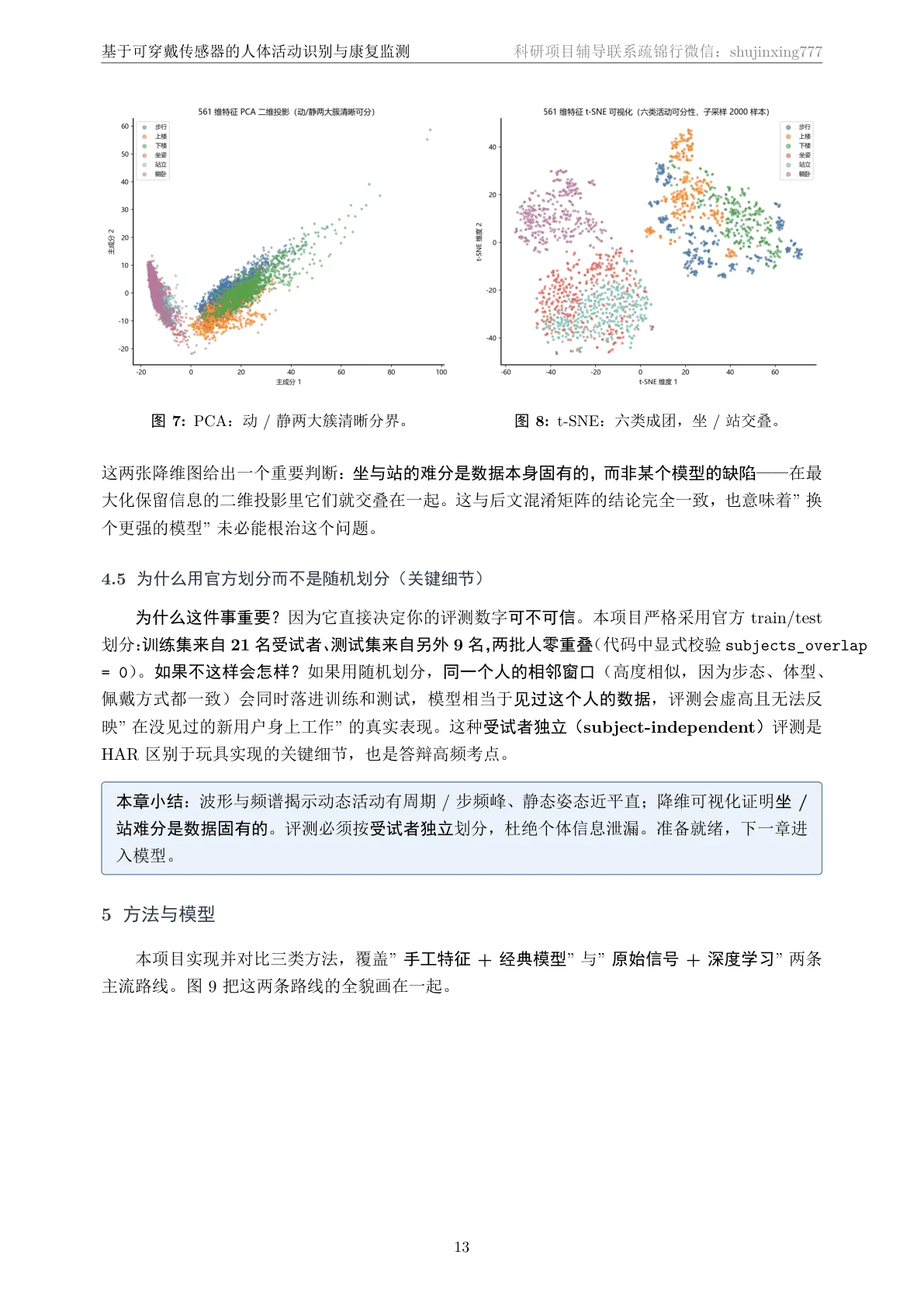
为什么"受试者独立划分"更可信。 这是能让你瞬间显得专业的一个点。很多人做活动识别会把所有人的数据混在一起随机切训练/测试——但这样同一个人的动作会同时进训练集和测试集,模型其实是"记住了这个人",分数虚高。这个项目用官方划分:训练用 21 个人、测试用另外 9 个人,两拨人零重叠。这样测出来的分数,回答的才是真正重要的问题——「换一个模型从没见过的新用户,它还认得准吗」。把这点讲出来,面试官会知道你懂泛化、懂数据泄漏。
下面这组结果图都给你做好了,可以直接放进答辩或面试 PPT:
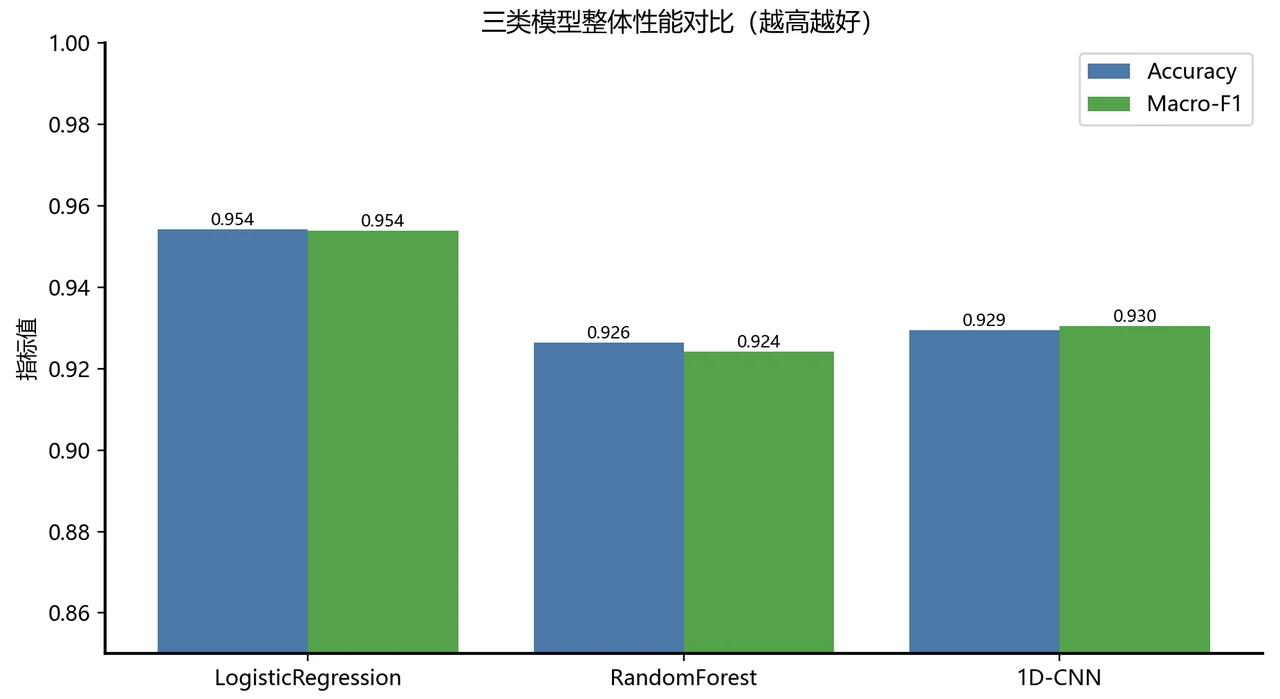
更关键的是,每张图是怎么跑出来的、该怎么解读,技术文档里都讲清楚了——所以你不是只会往 PPT 上贴图,而是能说明白每张图到底在说什么、能撑起一段有逻辑的讲解。
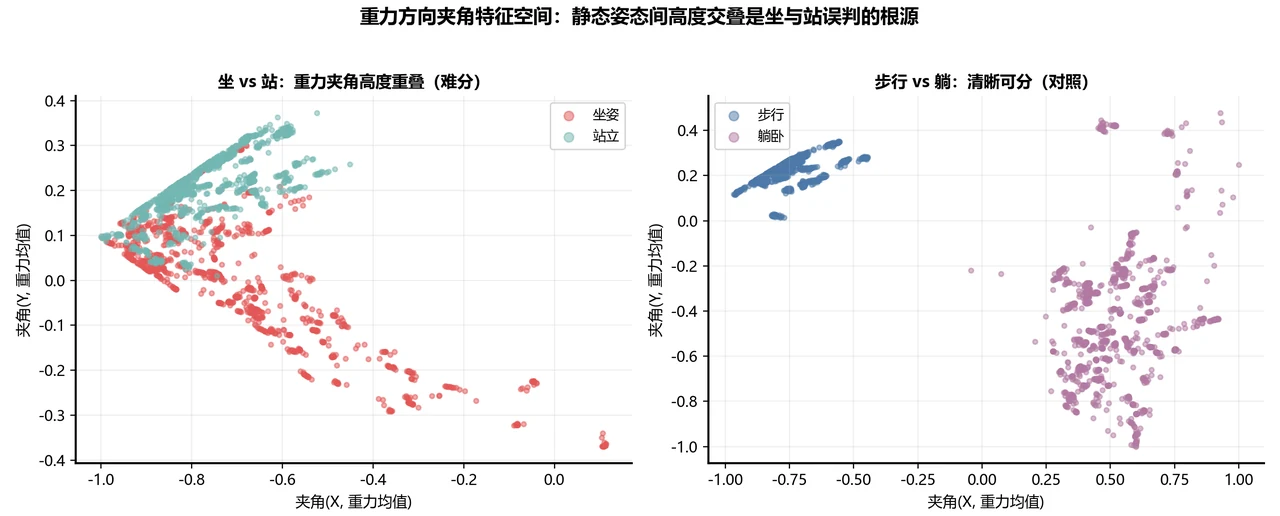
坐和站为什么最难分——把它讲成深度,而不是缺陷。 所有模型都在「坐」和「站」上栽过跟头,但这恰恰是最能体现你功力的地方:它不是模型不行,而是数据本身的固有难点。原因很物理——人坐着和站着时身体几乎不动,传感器读到的几乎只剩一个"重力分量",两种姿态在信号上长得太像。项目没有停在"这俩难分",而是用波形、频谱、降维、混淆矩阵、精确率召回率、重力夹角散点六重证据,一层层论证这个难点的来源。把这套论证讲出来,比报一个高分更能让面试官记住你。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
- 为什么逻辑回归这种最简单的模型,整体反而比 1D-CNN 还准?
- 受试者独立划分和随机划分,测出来的分数差在哪?为什么前者才可信?
- 坐和站为什么所有模型都容易混?你是怎么确认这是数据问题而不是模型问题的?
看到这几个是不是会愣一下?正常。配套的面试问答文档把这个项目——从整体思路到每个流程细节,各种面试可能追问的点——连参考答案都给你写好了。
另外还有现成的简历描述,照着改就能写进简历;那一整套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。你要做的不是背,而是理解,再用自己的话讲一遍。
配套资料:搞懂一个项目需要的,这里全都有
先看那份技术文档——从研究背景一直讲到每一步实现,图文并茂,帮你把原理从头吃透:


代码也给你了——关键部分都带着中文注释,帮你读懂"它到底是怎么实现的",面试被追问细节时也答得上来:
技术文档、面试问答、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添个有分量的项目,还是在准备面试,这个题目都接得住。它既落在可穿戴、康复监测这些有故事的应用场景上,方法上又把"特征工程 vs 深度学习"讲得很透——专业上,计算机、人工智能、数据科学、物联网、智能硬件,乃至体育科学、康复治疗、护理方向都很合适。资料、讲解和面试答案都给你铺好了,把它真正搞懂、能讲出来,就是一个能写进简历、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「基于可穿戴传感器的人体活动识别与康复监测」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。