基于地震目录数据的地震活动时空聚类与风险热区识别
用 DBSCAN 时空聚类,从 USGS 全球约 2 万次地震里自动找出活跃热区,画出环太平洋「火环」。科学严谨、只做活动性分析不预测地震——配套带注释代码、技术文档、面试问答和整套配图,适合做毕设、给简历加亮点、准备面试。
项目亮点
- 地震总数:19998 次(M≥4.5),时间跨度约 2.58 年,震级 4.5–8.2,平均深度 55.2 km。
- 古登堡-里希特 b 值:1.16(a=9.48,Mc=4.7),与全球地震学典型取值一致。
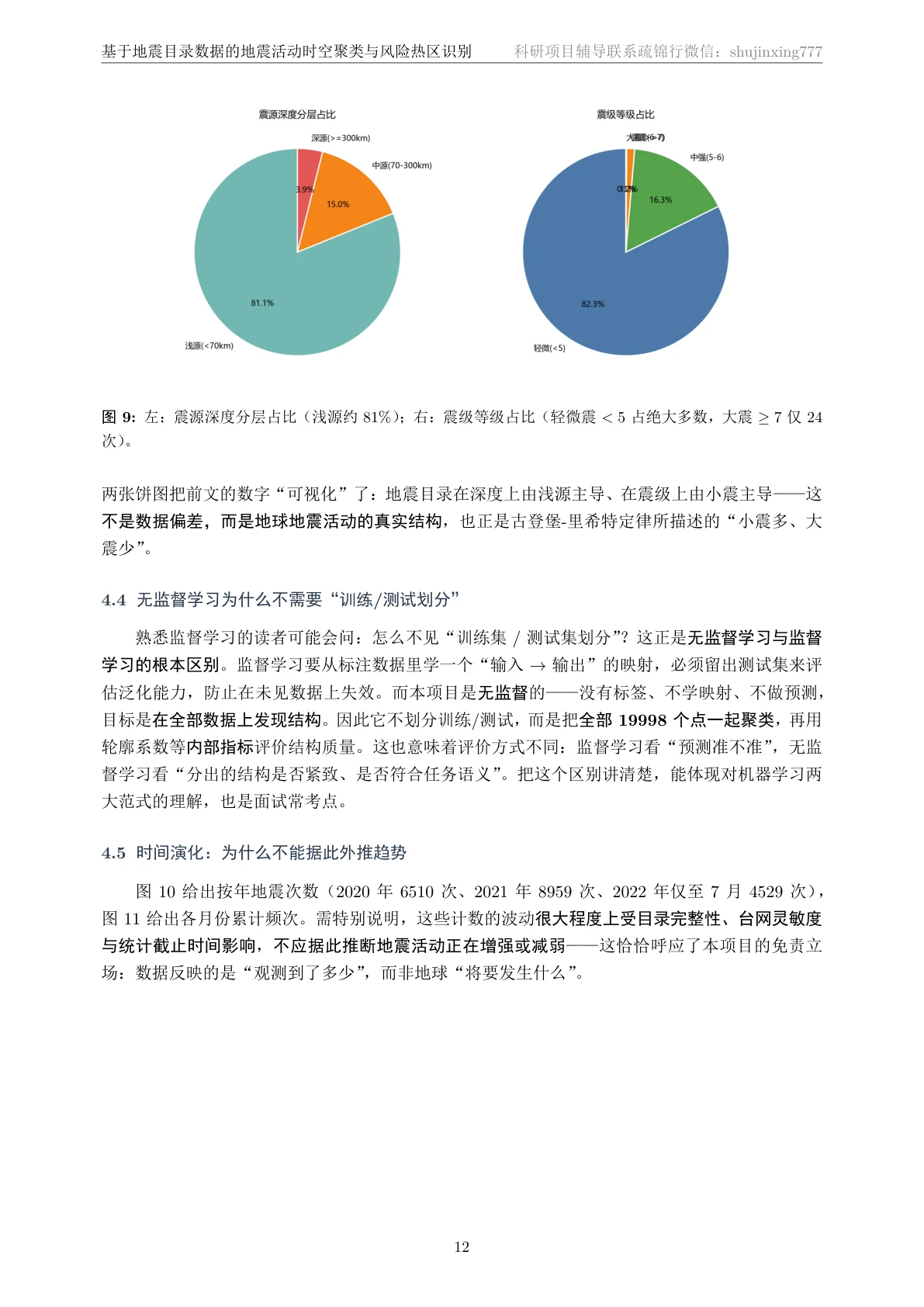
- 深度分层:浅源(<70km) 16221 / 中源 2991 / 深源(≥300km) 786,浅源占 81%。
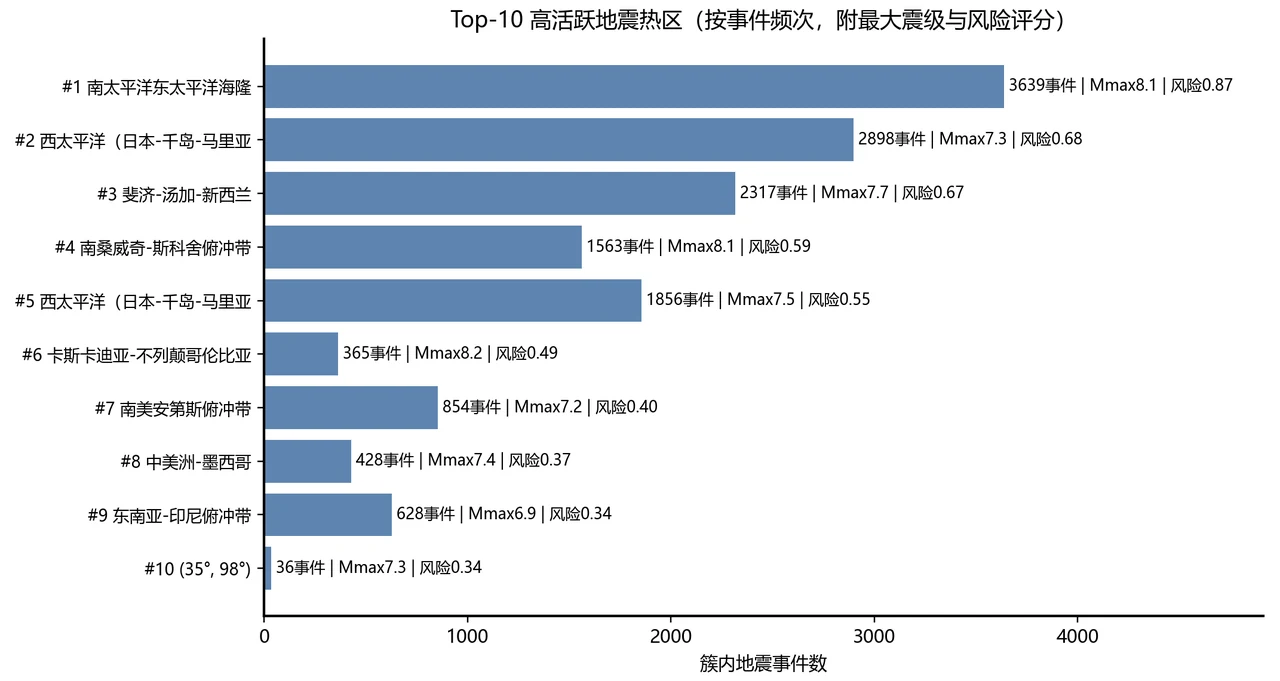
- Top-1 风险热区:南太平洋东太平洋海隆,3639 次事件,最大震级 8.1,风险评分 0.867。
如果你正在找一个能写进简历、面试时又能讲清楚的 AI 项目,这个「用聚类算法在全球地震数据里找出活跃热区」的题目会很合适——方向硬核(无监督学习 + 空间数据 + 地球科学),但讲出来一句话就能让人听懂:把两万次地震点在地图上,让算法自己圈出哪里最活跃。
配套都给你备齐了,帮你真正搞懂它、在面试和答辩里讲明白:带中文注释、能读懂的代码,一份从背景到每步实现的技术文档,一份把面试问题连答案都写好的问答文档,还有一整套可以直接拿去做 PPT 的配图。
先说清楚,它到底在做什么
地震不是均匀撒在地球上的,它高度集中在板块边界——环太平洋一圈、中大西洋洋中脊那条缝。如果手里有一份全球地震的「流水账」(什么时间、什么地点、多大震级),能不能让算法自己把这些密集成带的活跃区一块块圈出来,而不靠人去画?这就是这个项目要解决的事。
数据用的是美国地质调查局(USGS)的全球地震目录,约 2 万次 M≥4.5 的地震,时间跨度两年多。思路是:先把脏数据洗干净,再用一种叫 DBSCAN 的密度聚类算法——它的特点是不用提前告诉它"分成几类",能顺着地震密集的走向圈出任意形状的活跃带,还能把零散的背景地震当"噪声"剔掉。最后在地图上画出来,并统计大小地震的比例、震级和深度的分布,给热区按历史活动强度排个序。
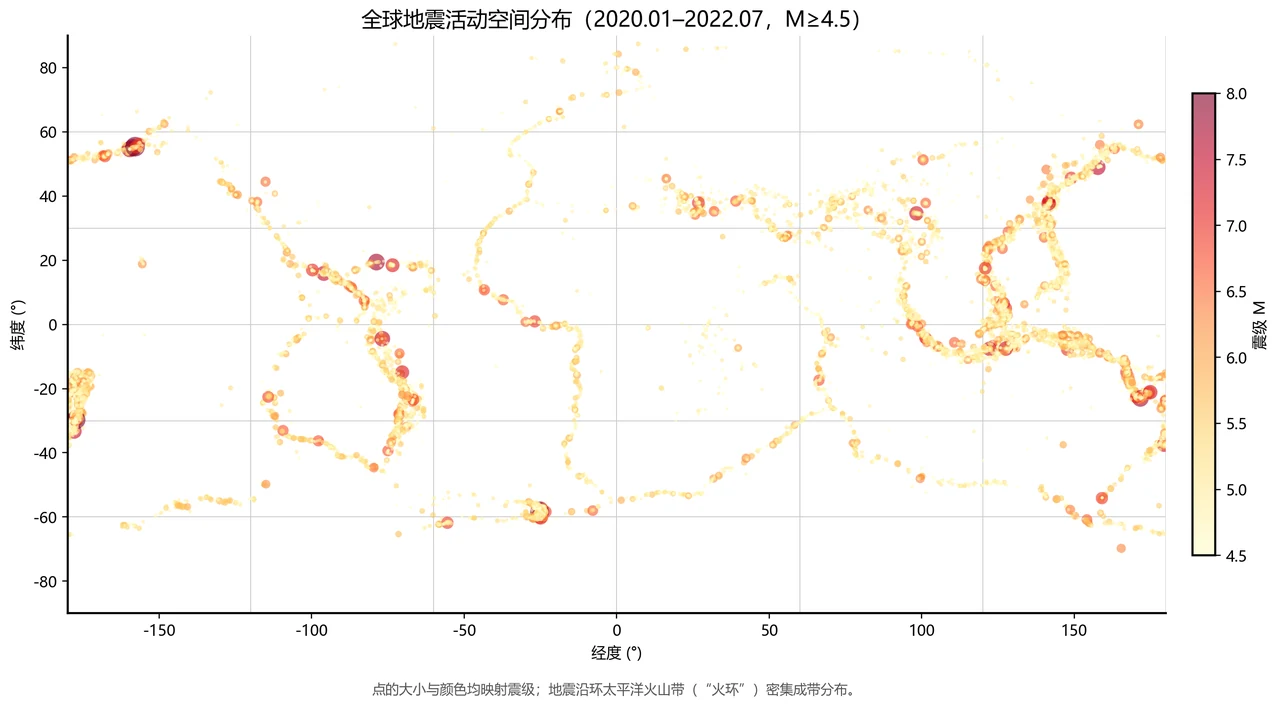
有一条科学边界,必须先讲清楚,它恰恰是这个项目的加分项:本项目只对已经发生的历史地震做活动性分析、热区识别和统计,不预测、也无法预测任何未来地震的时间、地点和震级——地震短临预报至今是世界性未解难题。面试时第一句就把这条边界划出来,反而最能体现你的科学素养:知道什么能做、什么不能宣称,不为吸引眼球而越界。这是地震类项目最容易踩的坑,你提前避开了。
搞懂它,你能在面试里讲清楚什么
这才是这个项目对你最大的价值。把下面几件事吃透,面试官问到相关问题时,你都能从容答上来。
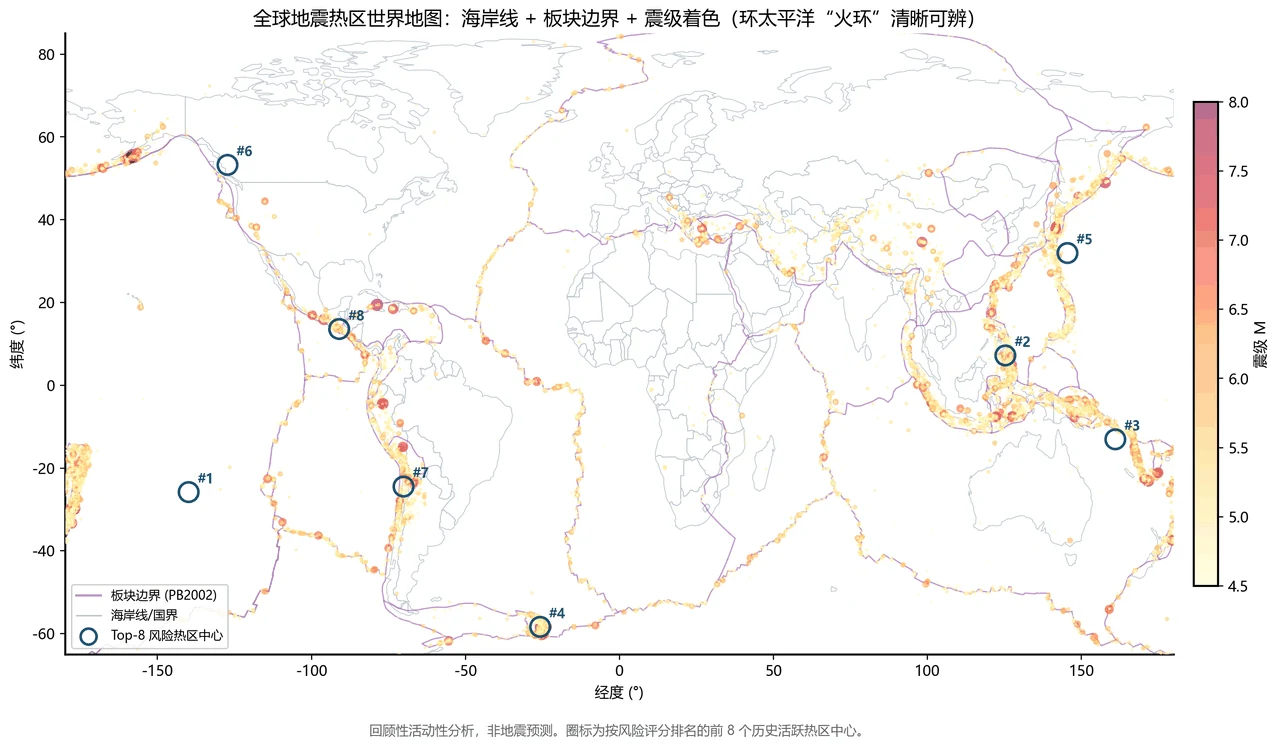
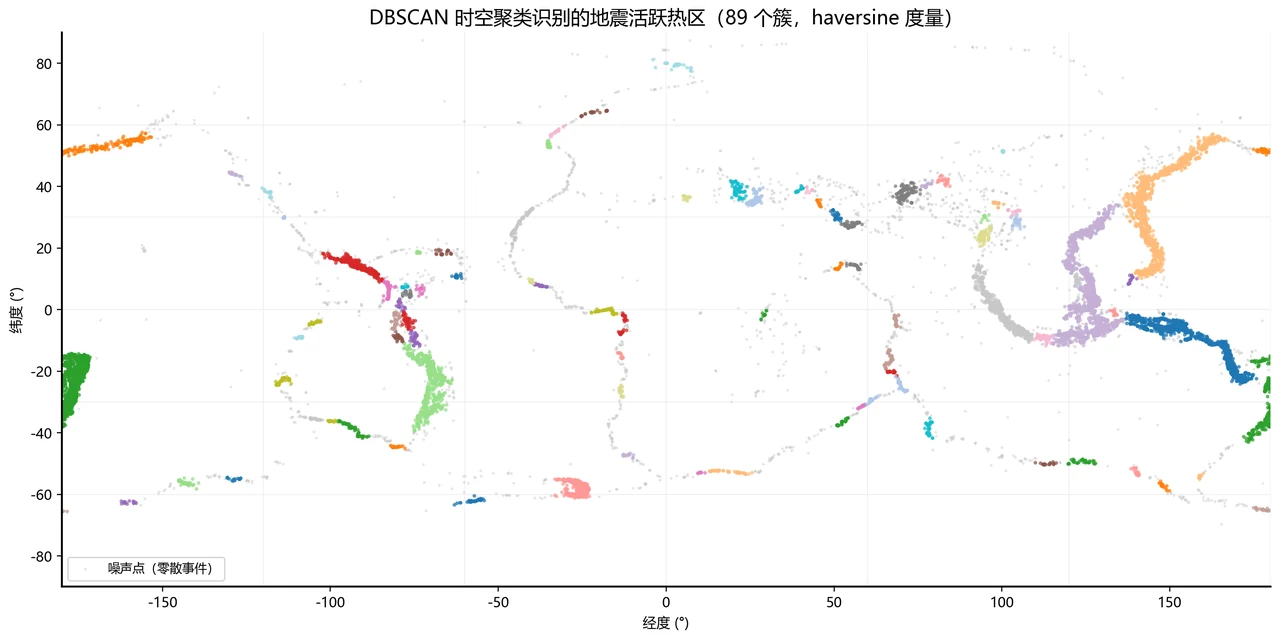
这个项目最漂亮的一张图——全球地震热区地图。 用 Natural Earth 的国界、加上 PB2002 板块边界,把 DBSCAN 圈出的 89 个活跃热区叠在世界地图上,环太平洋"火环"一目了然。这张图信息量最大、最出彩,是整个项目的门面,也是答辩 PPT 上最能镇场的一页。
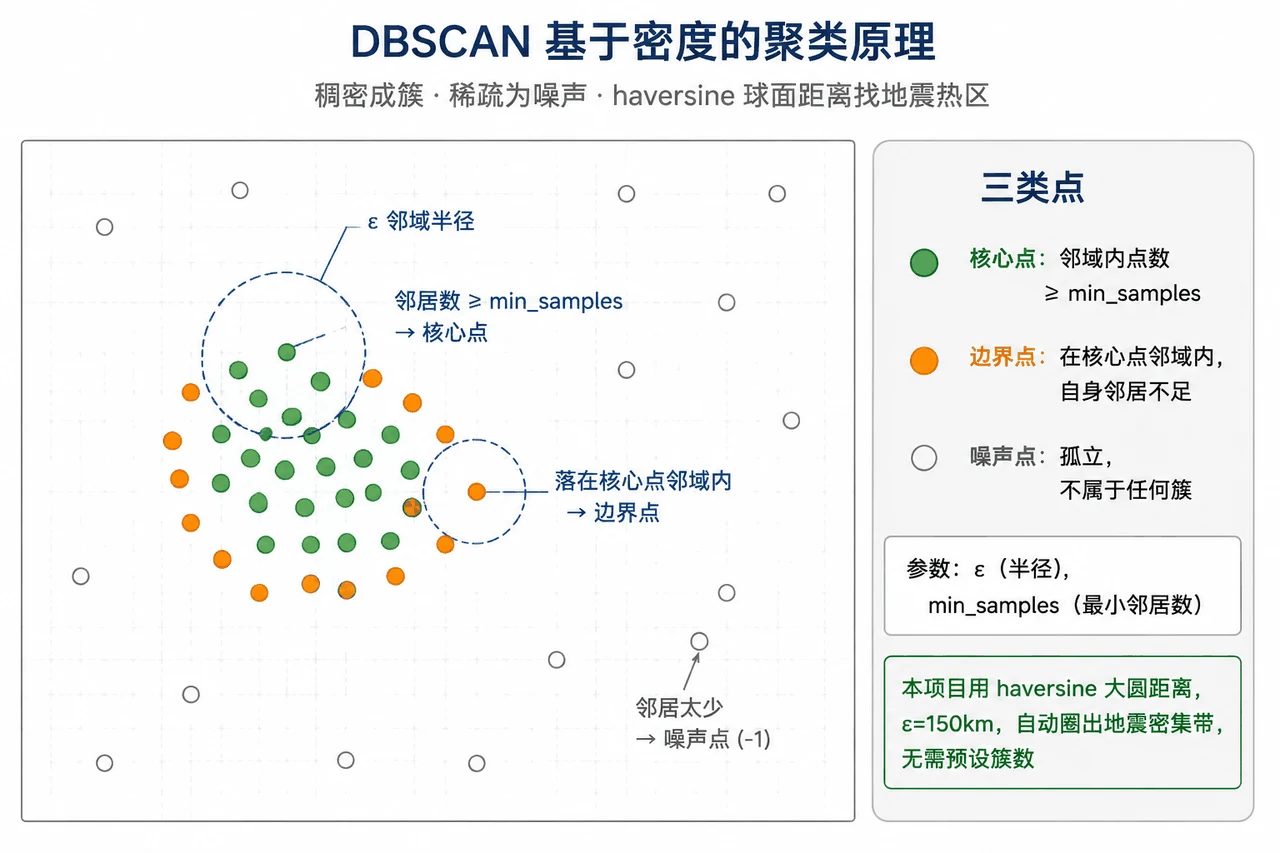
为什么用 DBSCAN,不用更常见的 KMeans。 这是面试最爱深挖的点,你能讲出三条硬道理:① 全球到底有多少条活跃带,事先没人知道,DBSCAN 不用预设簇数;② 活跃带是狭长曲线状的,DBSCAN 能找任意形状,KMeans 只会画一个个圆球;③ 需要把零散的背景地震和密集带分开,DBSCAN 有"噪声"这个概念,敢说某些点谁都不属于,而 KMeans 会把每个点都硬塞进某一类。配套的 DBSCAN 原理图把核心点 / 边界点 / 噪声点讲得明明白白。
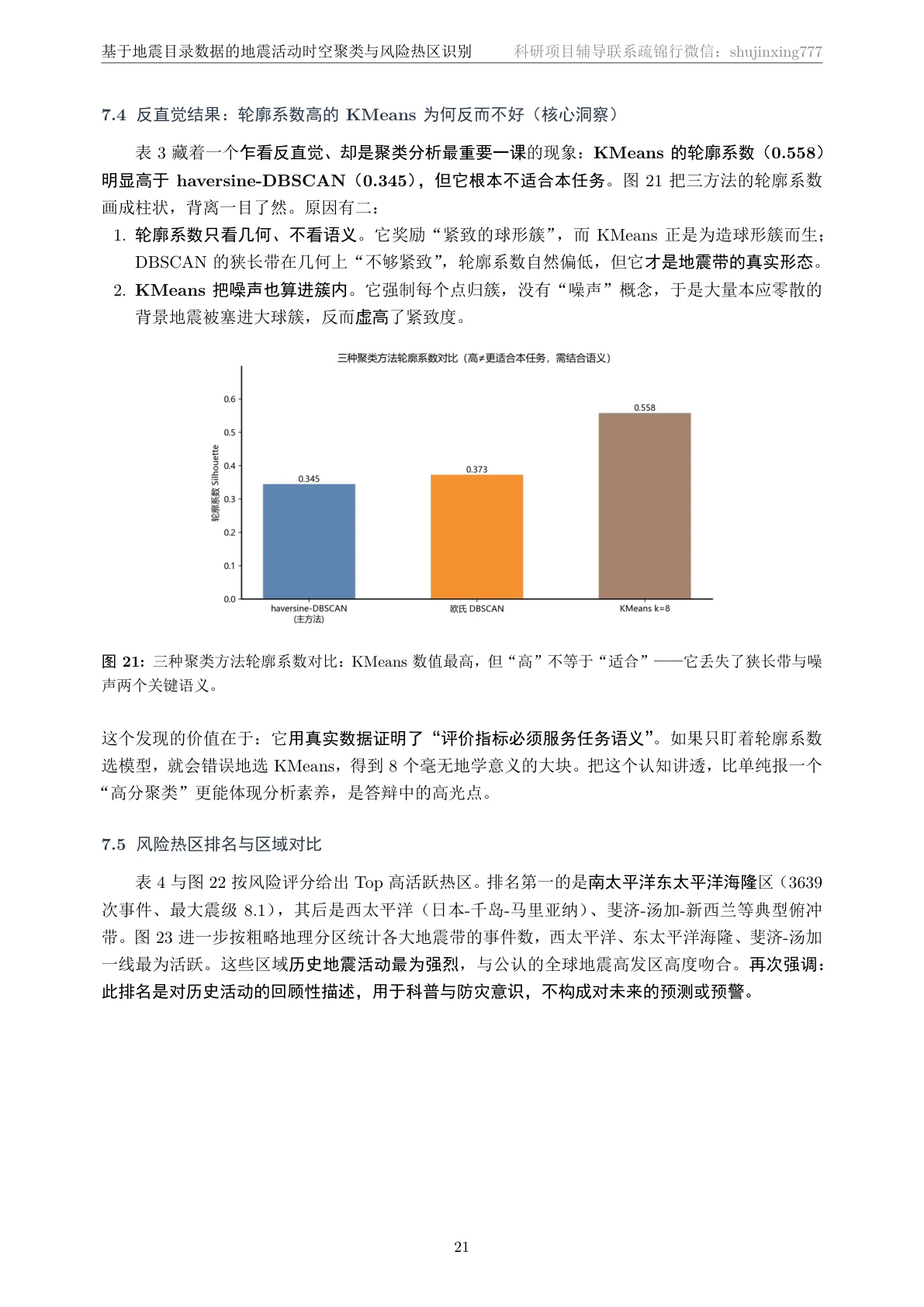
一个能体现深度的认知点:指标高 ≠ 方法好。 项目里 KMeans 的轮廓系数(0.56)其实比 DBSCAN(0.345)还高,但它反而最不适合这个任务——它把背景噪声也塞进大圆簇里,指标虚高,却丢掉了"狭长活跃带"和"噪声"这两个最关键的语义。你能讲清楚"聚类评价指标必须服务于任务目标,不能唯指标论",这一下就把你和只会背一个数字的人区分开了。
下面这组分析图也都给你做好了,可以直接放进你的答辩或面试 PPT:
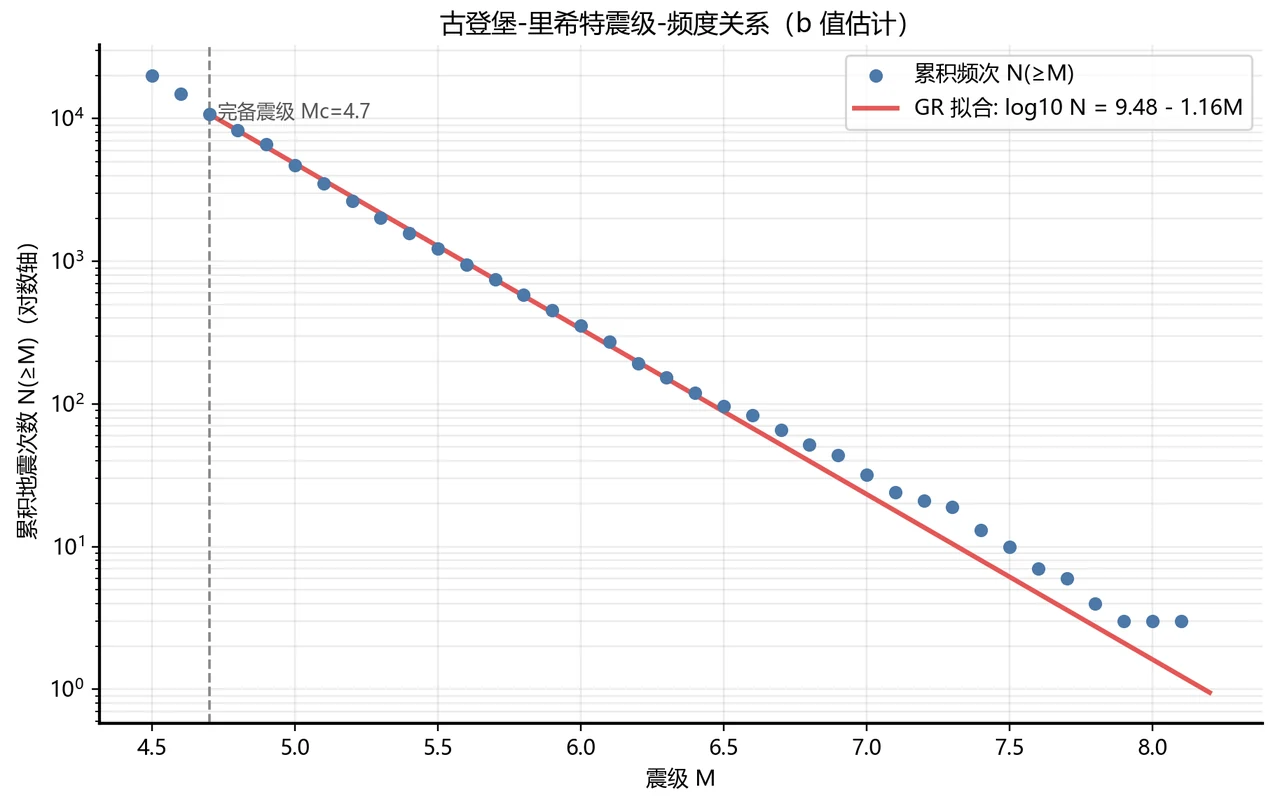
更关键的是,每一张图是怎么跑出来的、该怎么解读,技术文档里都讲清楚了——所以你不是只会往 PPT 上贴图,而是能说明白每张图到底说明了什么。比如那张古登堡-里希特图,你能讲出 b 值 1.16 的含义:震级每升一级、地震数量约减为十分之一,这个斜率和全球典型值吻合,说明数据和方法都靠谱。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
- 为什么必须用 haversine 球面距离,直接拿经纬度算欧氏距离不行吗?
- DBSCAN 的两个参数 ε 和 min_samples 是怎么定的?噪声占比 11% 说明了什么?
- KMeans 的轮廓系数明明更高,你为什么还说它不如 DBSCAN?
看到这几个是不是会愣一下?正常。配套的面试问答文档把这个项目——从整体思路到每个流程细节、各种面试可能追问的点——连参考答案都给你写好了,包括"为什么不能预测地震""b 值是什么""完备震级 Mc 为什么重要"这些容易被问倒的硬核点。
另外还有现成的简历描述,照着改就能写进简历;那一整套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。你要做的不是背,而是理解,再用自己的话讲一遍。
配套资料:搞懂一个项目需要的,这里全都有
先看那份技术文档——从研究背景、数据来源一直讲到每一步实现,图文并茂,帮你把原理从头吃透:

代码也给你了——关键部分都带着中文注释,帮你读懂"它到底是怎么实现的",面试被追问细节时也答得上来:
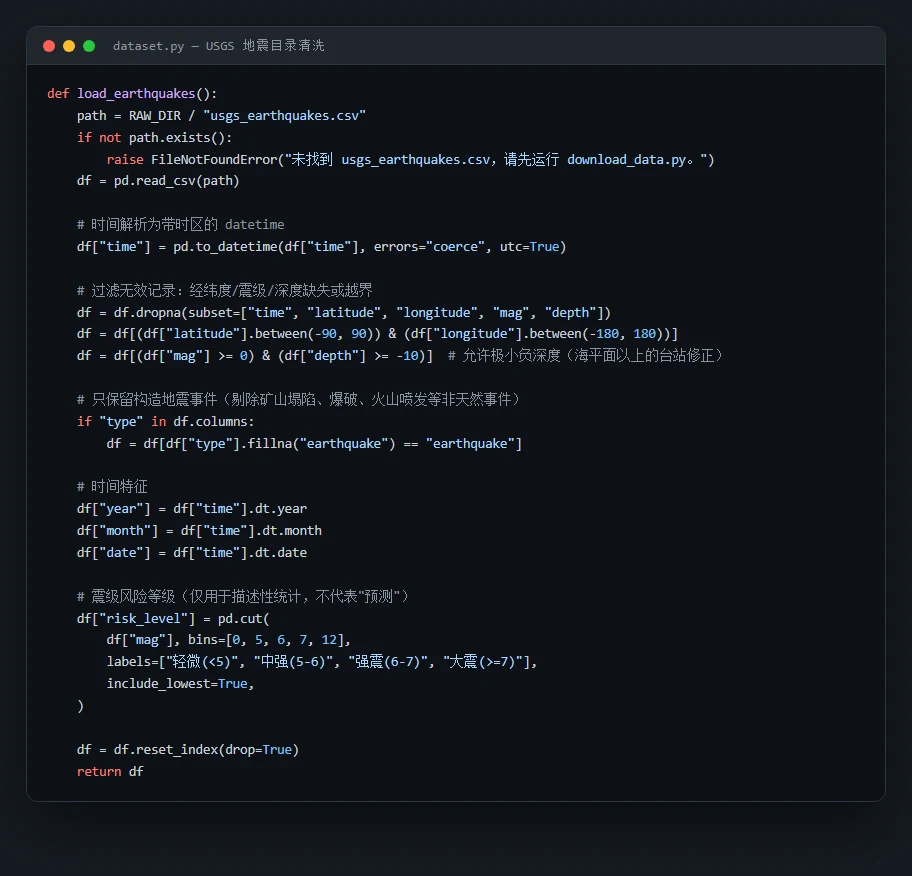
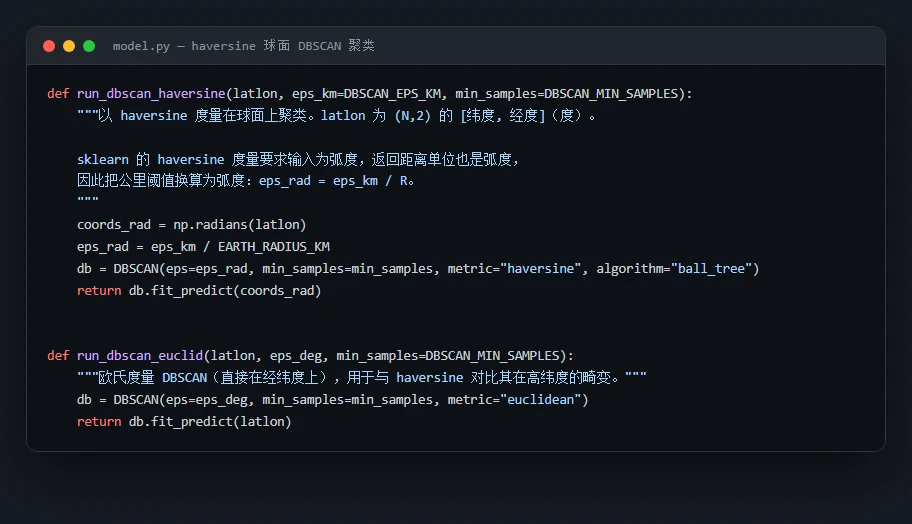
技术文档、面试问答、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添个有分量的项目,还是在准备面试,这个题目都接得住。专业上,地理信息系统(GIS)、防灾减灾、土木工程、地球物理、数据科学和人工智能方向都很合适。它把无监督聚类、空间数据处理、统计建模和一张漂亮的世界地图串成了完整一条线,资料、讲解和面试答案也都给你铺好了——把它真正搞懂、能讲出来,就是一个能写进简历、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「基于地震目录数据的地震活动时空聚类与风险热区识别」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。