基于中心优先扫描状态空间模型(CenterScan-Mamba)的高光谱图像分类
用状态空间模型(Mamba)做高光谱图像分类的完整项目。核心是一个能讲清楚的小创新——让待分类的中心像素在扫描序列里最后被读、吃透整块上下文。跑了三个公开真实数据集、配套带注释代码 + 技术文档 + 面试问答 + 整套配图,还整理成了 EI 会议论文,特别适合毕设、简历和面试。
项目亮点
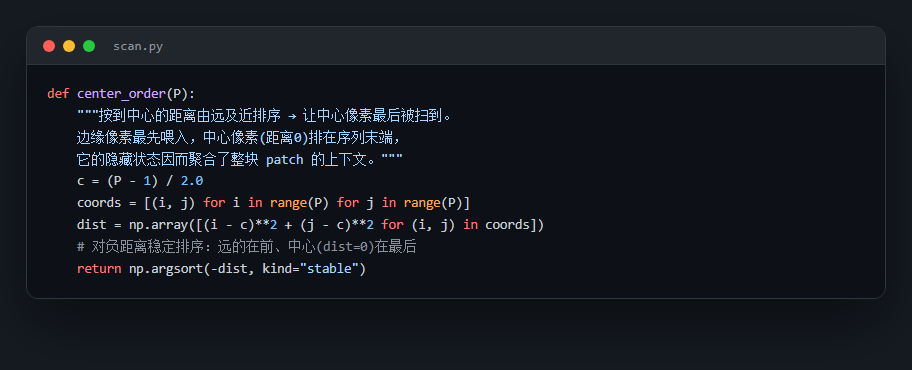
- 中心优先扫描(Center-Prioritized Scanning):把 P×P 空间 token 按到中心的距离由远及近重排,使中心像素最后被扫到、隐藏状态吸收整块 patch。参数无关、推理零额外开销。
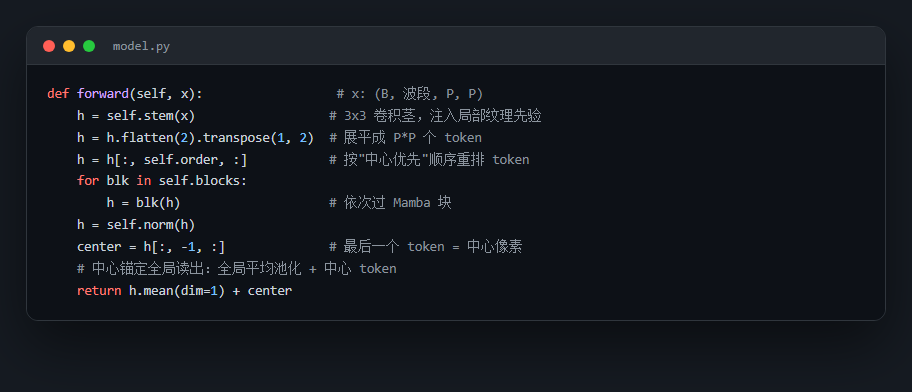
- 中心锚定全局读出:中心 token + 序列全局平均池化(CNN 在小场景制胜的关键),把朴素 Mamba 的 79.26% 拉到 95% 量级。
- 光谱-空间双分支 + 门控融合:中心像素光谱曲线经 Mamba 得光谱描述子,可学习门控 σ(g) 自适应融合,防止弱光谱分支拖累。
数据与任务
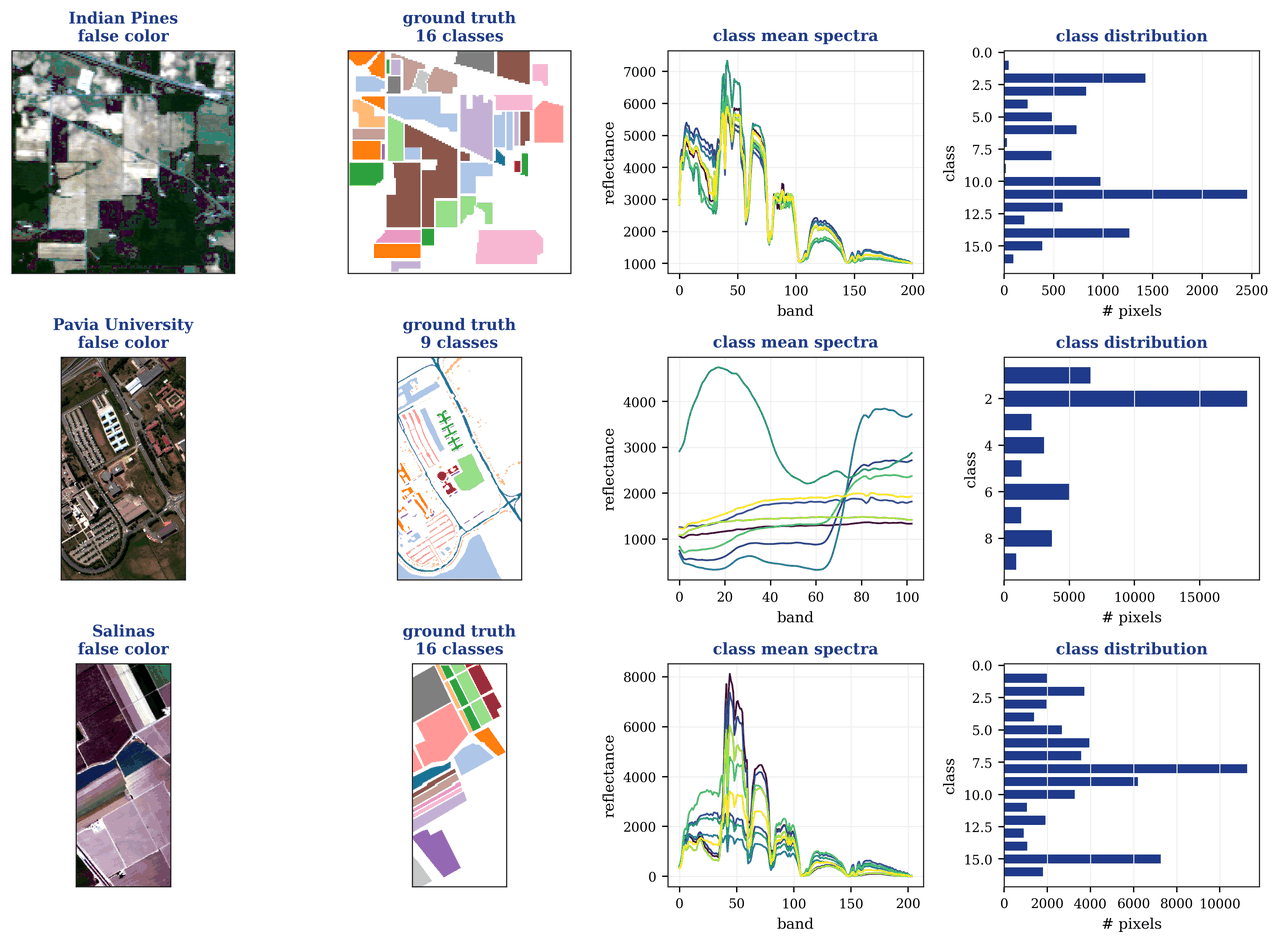
| 样本量 | 3 个公开真实数据集(Indian Pines / Pavia U / Salinas) |
|---|---|
| 核心方法 | 中心优先扫描状态空间模型(CenterScan-Mamba) |
| 技术栈 | PyTorch · Mamba/SSM · 纯 torch 选择性扫描 |
如果你想找一个能写进简历、面试时又能讲出技术含量的 AI 项目,这个「用状态空间模型给高光谱图像分类」会很合适。
它踩中了三个当下很有话题度的点——遥感图像、Mamba(状态空间模型),以及一个真正能讲清楚的小创新;而且配套都给你备齐了,帮你真正搞懂它、在面试和答辩里讲明白:带中文注释、能读懂的代码,一份完整的技术说明文档,一份把面试追问连参考答案都写好的问答专题,还有一整套可以直接拿去做 PPT 的配图。它跑的是公开真实数据,成果还整理成了一篇 EI 会议论文。
先说清楚,它到底在做什么
高光谱相机在每一个像素上记录几百个连续波段,等于给每个点都拍了一条「光谱指纹」。靠这条指纹,我们能区分肉眼难辨的地物——哪片是某种作物、哪里是建筑或道路。难点在于:标注一张高光谱图很贵,相邻波段又高度相似(信息冗余),而且单看一个像素往往不够,得结合它周围的一小片邻域。
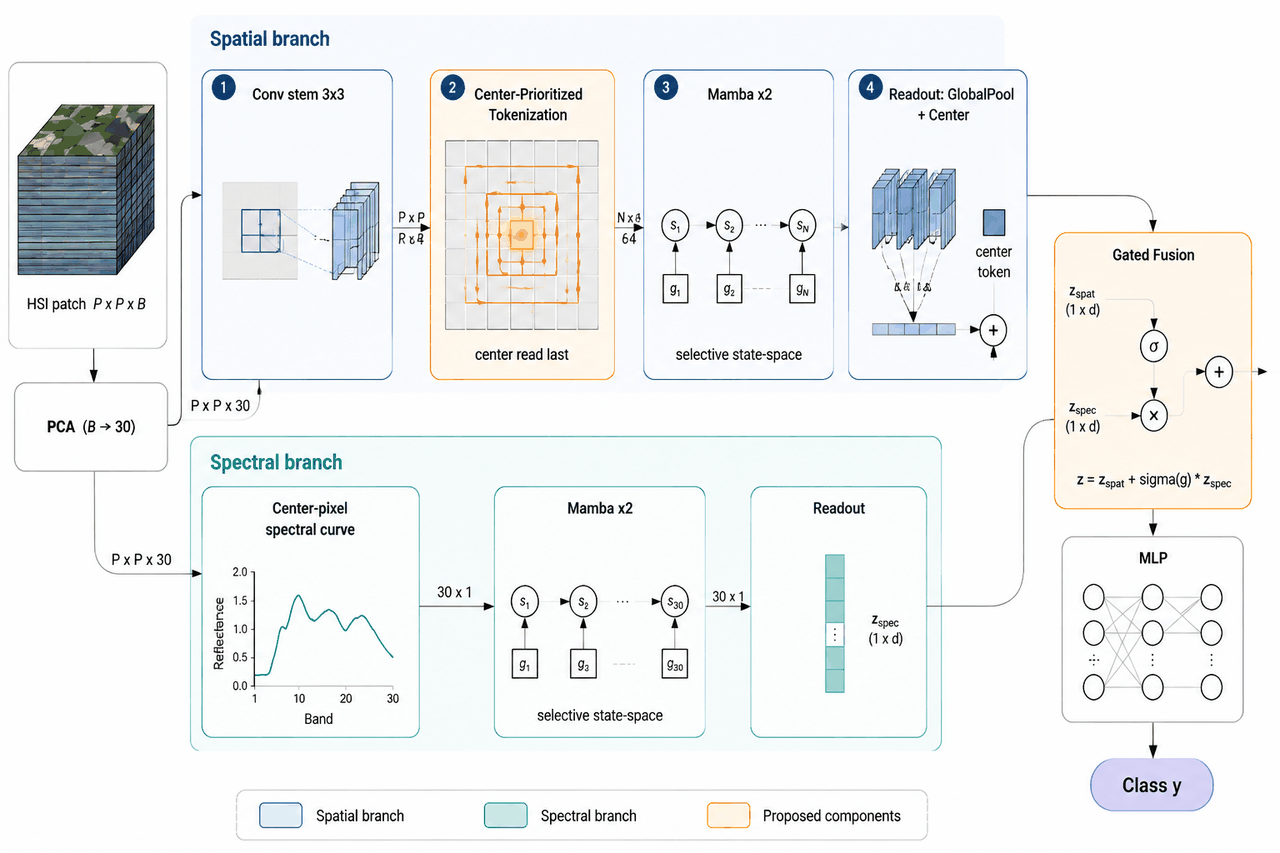
这个项目的思路是:用 Mamba(一种线性时间的序列模型) 去读每个像素周围的小图块。这里有个很妙的切入点——Mamba 是「读到最后才看全整段」的模型,而我们真正要判断的,恰恰是图块正中心那个像素。所以我们把扫描顺序重排,让中心像素在序列里最后被读,它就自然吃透了整块图的上下文。这一改动不增加任何参数,却是整个项目最稳的提分点。
搞懂它,你能在面试里讲清楚什么
这才是这个项目对你最大的价值。把下面几件事吃透,面试官问到相关问题,你都能从容讲清楚。
为什么「中心优先扫描」是个聪明的设计。 这是全项目的灵魂,也是面试最爱问的点。你能用一句话讲清因果模型的特性,再说明为什么「把目标像素安排在最后读」恰好补上了常规扫描的短板——既体现你懂原理,又显出设计巧思。
怎么把消融实验讲漂亮。 项目做了完整的对比与消融——这正是面试官爱深挖、最能体现科研思维的地方。你能有理有据地说明:单是把扫描顺序换成中心优先,精度就稳定抬升了一截;再叠加「全局读出」的设计,更是把一个朴素的序列模型从勉强能用拉到了高水准。每一步改了什么、带来多少提升,都讲得出因果。
怎么用一张图就让面试官记住你。 把不同模型预测出的分类图并排一放,差距肉眼可见——弱模型满屏椒盐麻点,本方法干净又连续。一句"数字会压缩信息、地图不会",比只会背一个准确率的人高级太多。
下面这些分析图都给你做好了,可以直接放进答辩或面试 PPT:
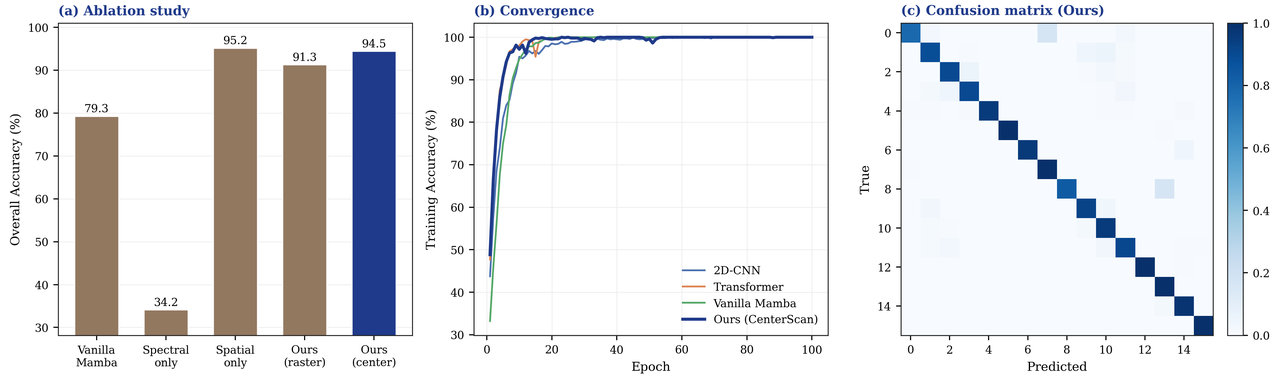
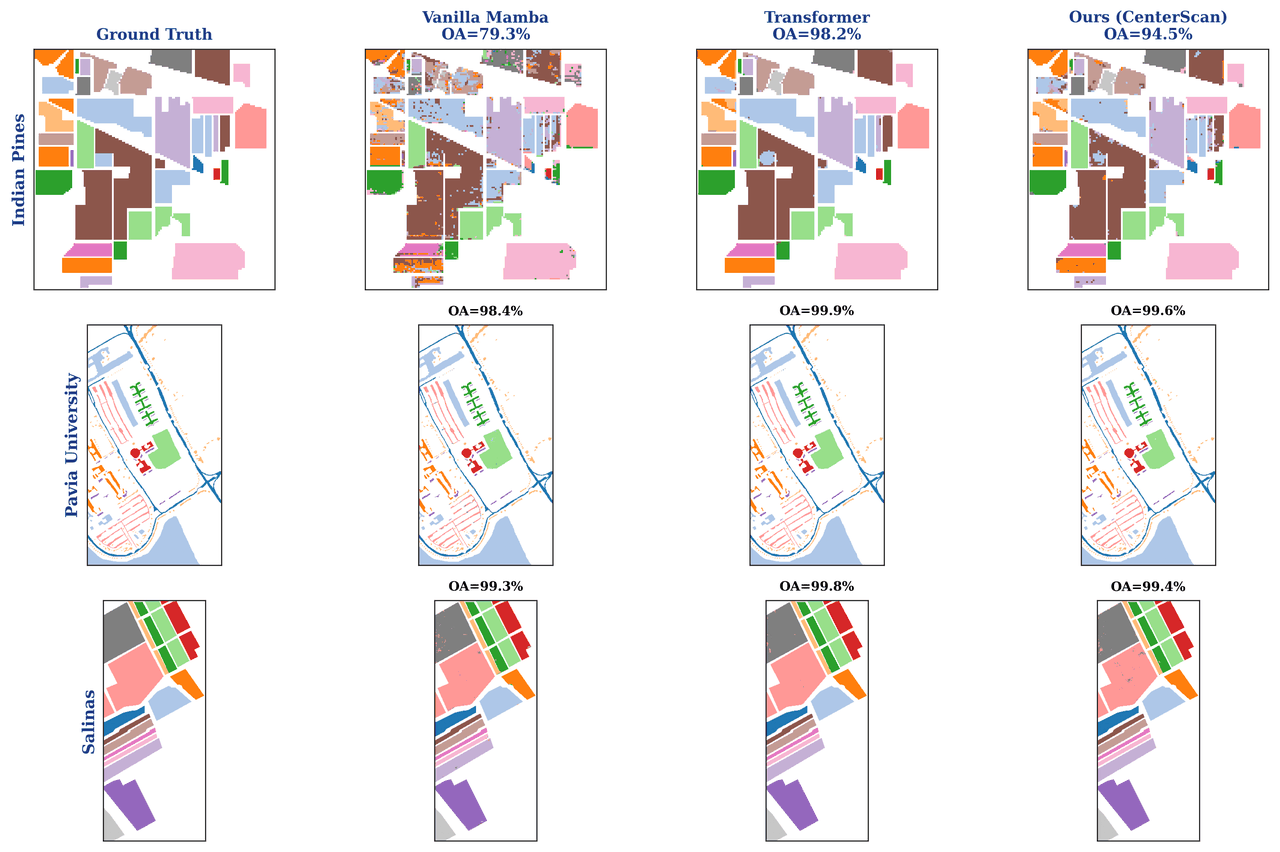
更关键的是,每一张图是怎么跑出来的、该怎么解读,技术文档里都讲清楚了——你不是只会往 PPT 上贴图,而是能说明白每张图到底说明了什么。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
- Mamba 是因果模型,为什么让"中心像素最后被读"就能涨点?
- 你在中心 token 之外又加了全局平均池化读出,它解决了什么问题?
- 光谱分支和空间分支怎么融合,那个可学习门控起了什么作用?
看到是不是会愣一下?正常。配套的面试问答专题把这个项目——从整体思路到每个流程细节、各种可能被追问的点——连参考答案都给你写好了。
另外还有现成的简历描述,照着改就能写进简历;那一整套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。你要做的不是背,而是理解,再用自己的话讲一遍。
配套资料:搞懂一个项目需要的,这里全都有
先看那份技术说明文档——从研究背景一直讲到每一步实现,图文并茂,把原理从头吃透:

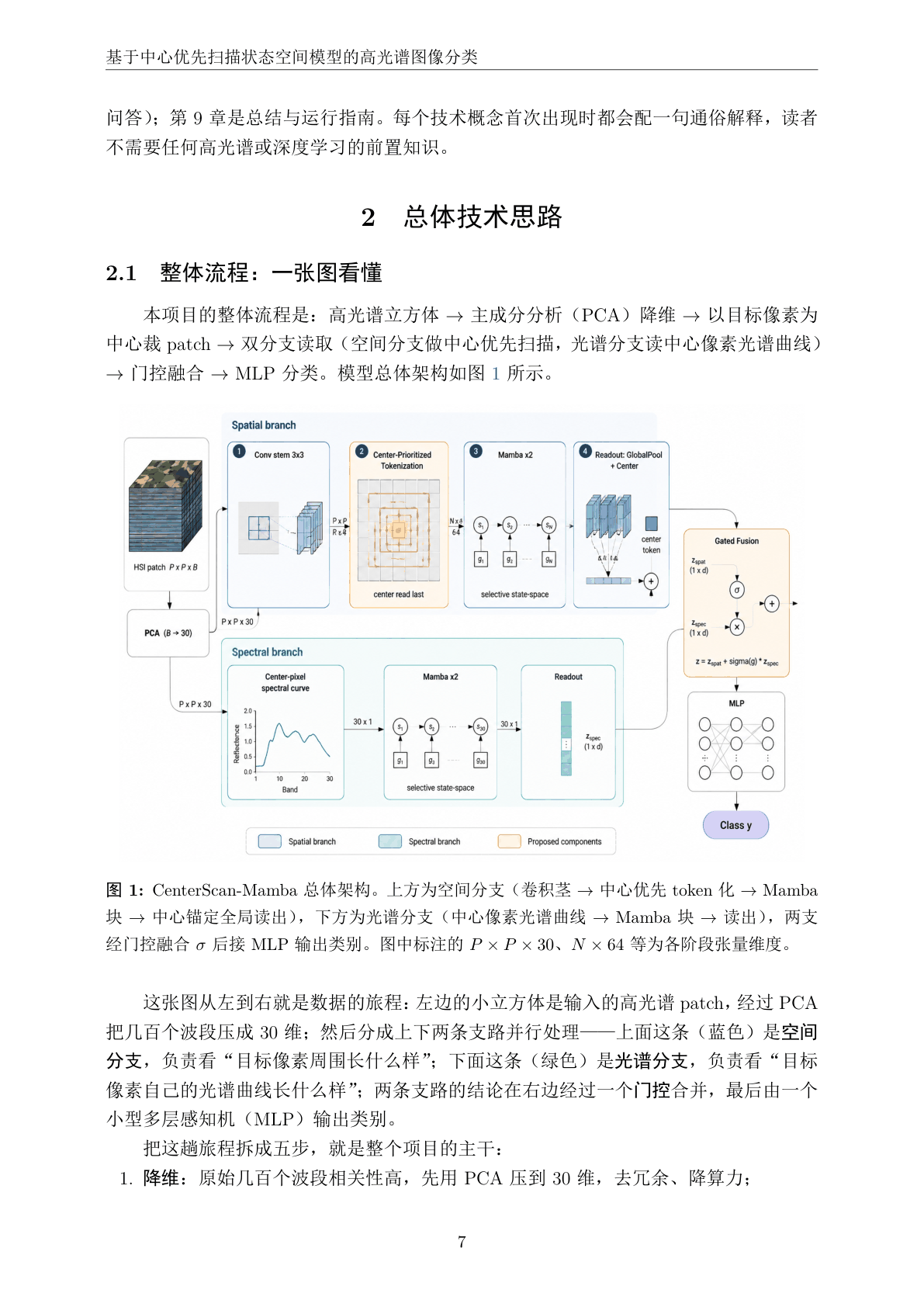

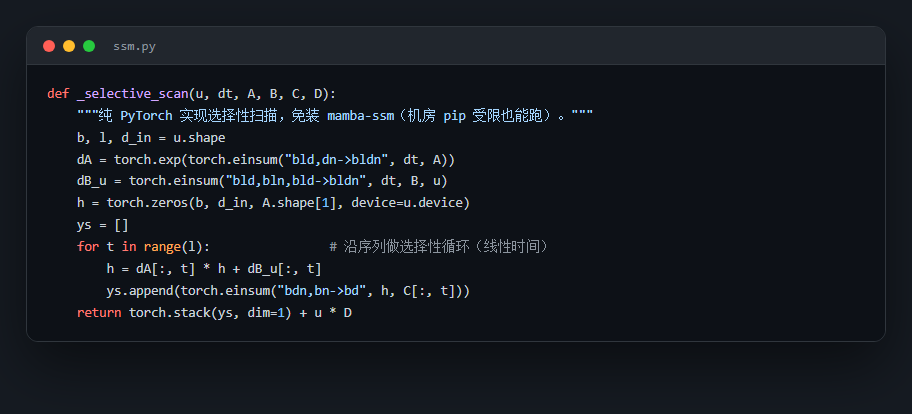
代码也给你了——关键部分都带着中文注释,帮你读懂"它到底是怎么实现的",面试被追问细节时也答得上来:
技术文档、面试问答、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添个有分量的项目,还是在准备面试,这个题目都接得住——它有一个真正能讲清楚的小创新,又跑在真实公开数据上,分量足。专业上,遥感科学、地理信息、计算机、人工智能、数据科学方向都很合适。资料、讲解和面试答案都给你铺好了,把它真正搞懂、能讲出来,就是一个能写进简历、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「基于中心优先扫描状态空间模型(CenterScan-Mamba)的高光谱图像分类」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。