基于机器学习的变压器故障预测
用传感器监测数据预测变压器故障:把无监督聚类(KMeans+DBSCAN)当成特征增强 + 五模型 + 两阶段调参 + 熵权-TOPSIS 选模 + SHAP 锁定关键传感器——带注释代码、技术文档、面试问答全配齐。
项目亮点
- 来源: Kaggle [Distributed Transformer Monitoring](https://www.kaggle.com/datasets/sreshta140/ai-transformer-monitoring)
- 文件: Overview.csv (20316条) + CurrentVoltage.csv (19352条),合并后约5000+条有效记录
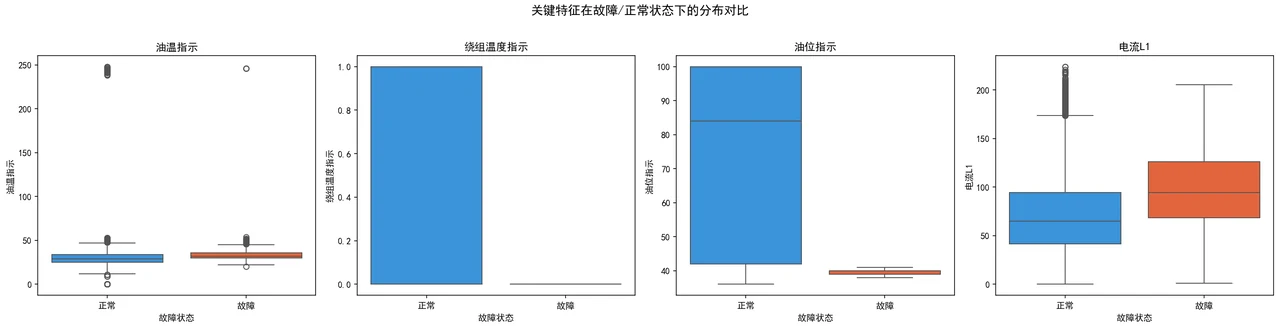
- 原始特征: 13个传感器特征(OTI/WTI/ATI温度 + VL1-3/IL1-3电压电流 + OLI油位等)
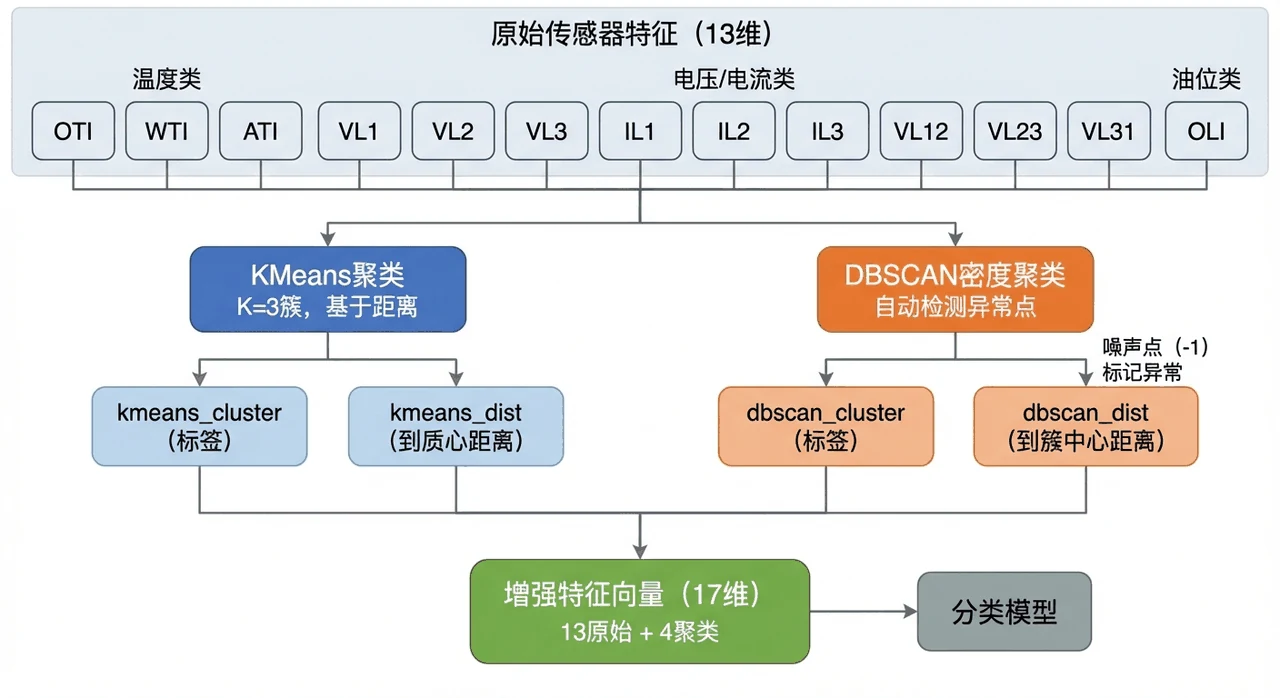
- 工程特征: 4个聚类特征(KMeans聚类标签+质心距离, DBSCAN聚类标签+质心距离)
数据与任务
| 样本量 | 2 万条 · 13 传感器 |
|---|---|
| 核心方法 | 聚类特征 + TOPSIS |
| 技术栈 | scikit-learn · SHAP |
如果你想找一个电力工程 + 机器学习、方法论又有亮点的项目,这个「变压器故障预测」很合适。
它面向预测性维护这个真实需求,配套也给你备齐了,帮你真正搞懂它、在面试和答辩里讲明白:带中文注释、能读懂的代码,一份从背景讲到每步实现的技术文档,一份把面试问题连答案都写好的问答文档,还有一整套能直接做 PPT 的配图。
先说清楚,它到底在做什么
电力变压器是输配电的核心设备,一旦故障可能造成大面积停电。传统定期巡检反应滞后,没法实时发现潜在故障。难点在于:故障样本极少(设备绝大多数时间正常),是典型的类别不平衡问题。
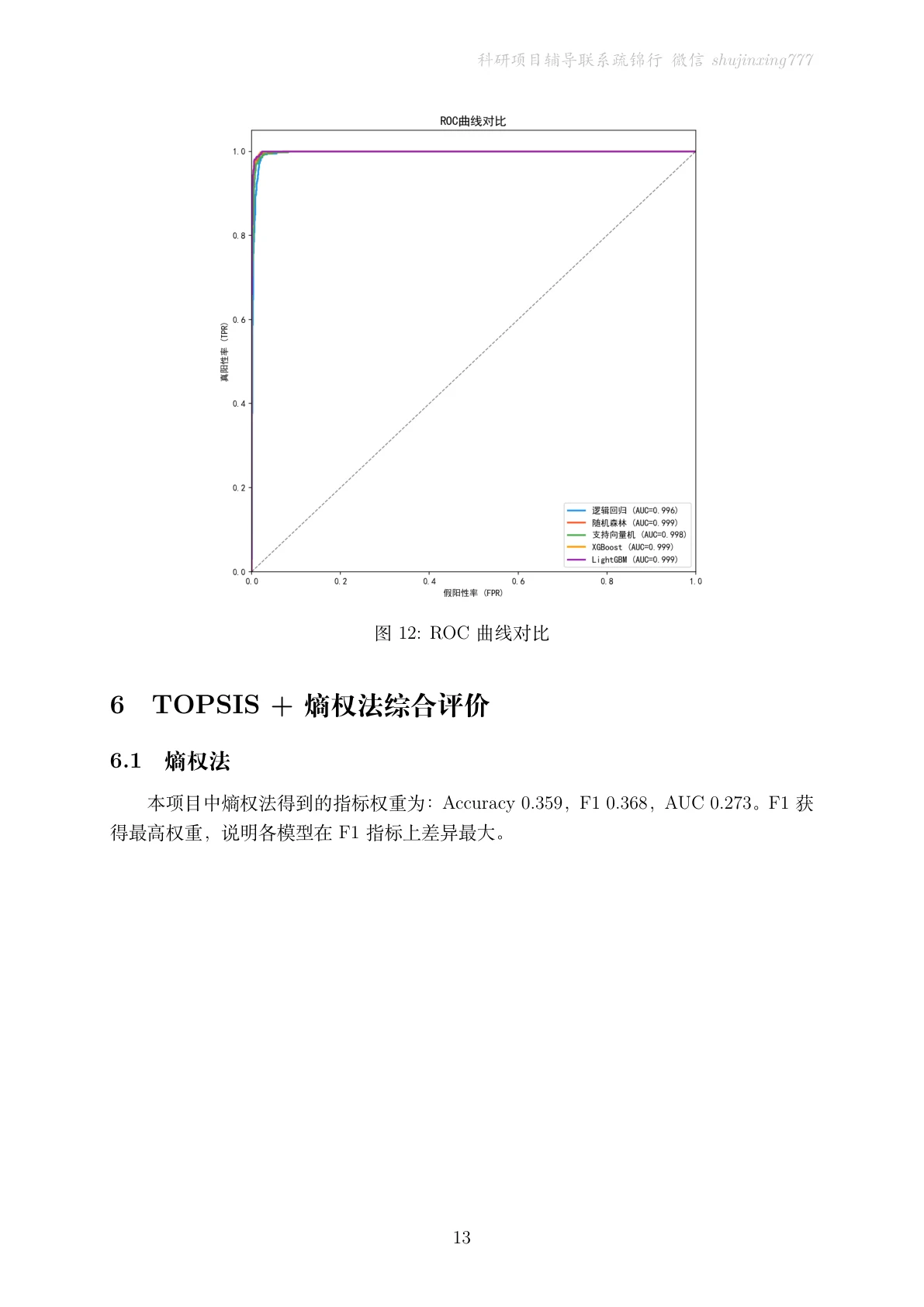
这个项目从温度、电压、电流、油位等传感器数据出发,把无监督聚类当成特征增强——用 KMeans 划分典型运行状态、DBSCAN 发现密度异常点,到簇心的距离反映"偏离正常的程度";再用 SMOTE 平衡样本、五模型对比 + 两阶段调参、熵权-TOPSIS 客观选模,最后用 SHAP 锁定哪个传感器最能预示故障。
搞懂它,你能在面试里讲清楚什么
把下面几件事吃透,面试官顺着问下来你都能接得住。
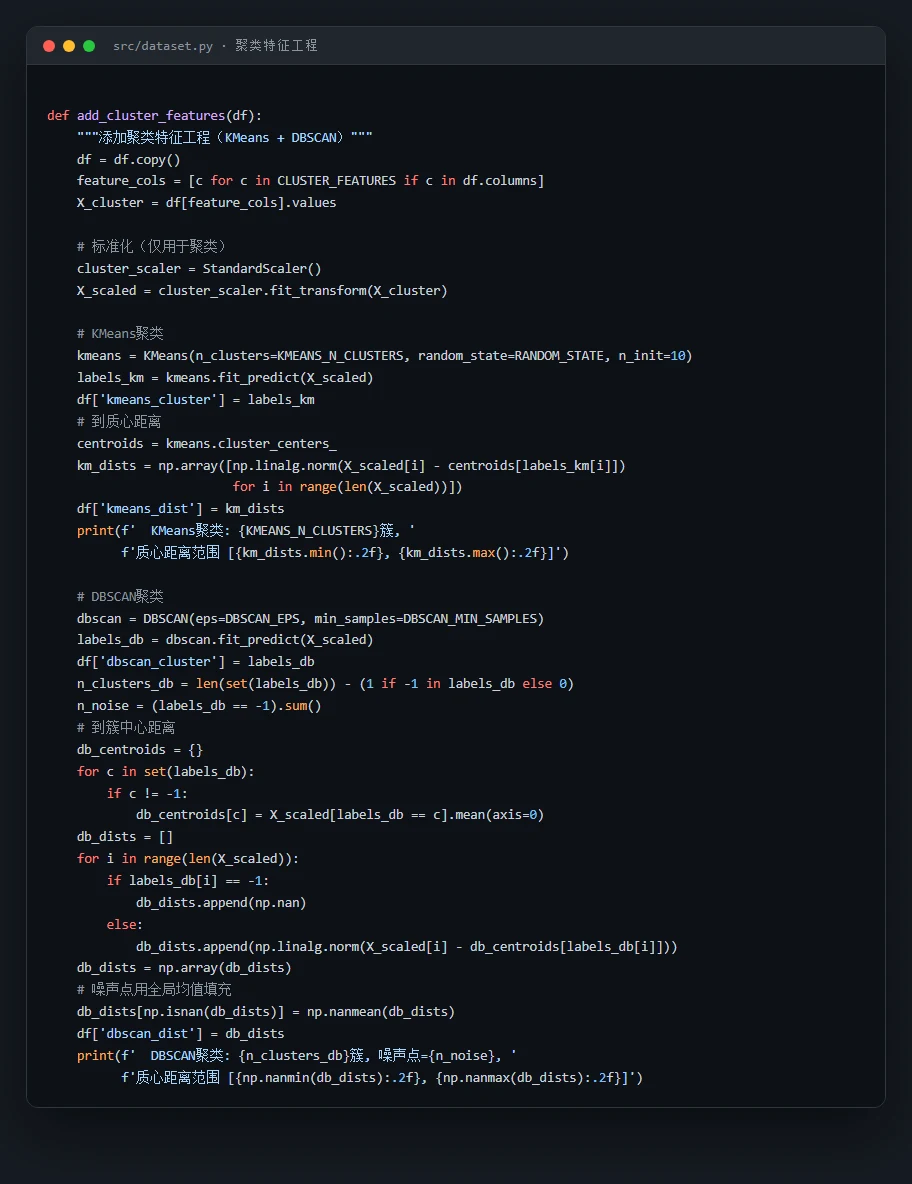
为什么用聚类做特征增强,而且 KMeans 和 DBSCAN 一起用。 这是项目最有特色的一手。KMeans 抓全局典型状态、DBSCAN 抓密度异常点,两者从不同角度刻画"异常程度",互补地喂给分类器。你能借此讲清楚"无监督 + 有监督"的组合思路。
类别不平衡 + 两阶段调参 + 客观选模。 故障是少数,用 SMOTE 平衡;先贝叶斯粗调再网格细调;多指标用熵权-TOPSIS 综合排名客观选模。这套方法论很能体现你的严谨。
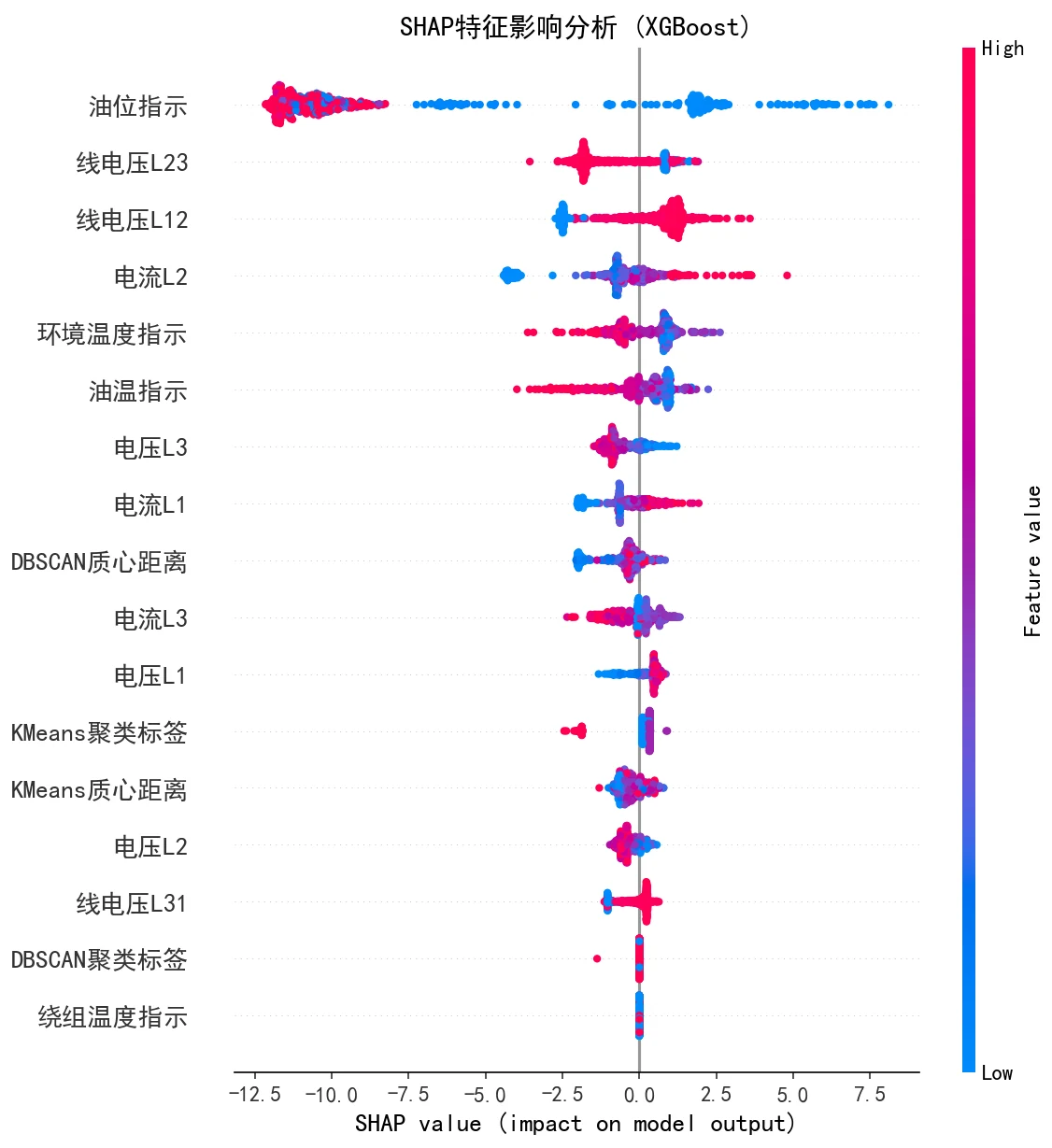
SHAP 怎么把预测对接到现场。 SHAP 能锁定油温等关键传感器,维护人员就知道该重点盯哪个量——把预测变成可执行的监测重点。
下面这组分析图也都给你做好了,可以直接放进答辩或面试 PPT:
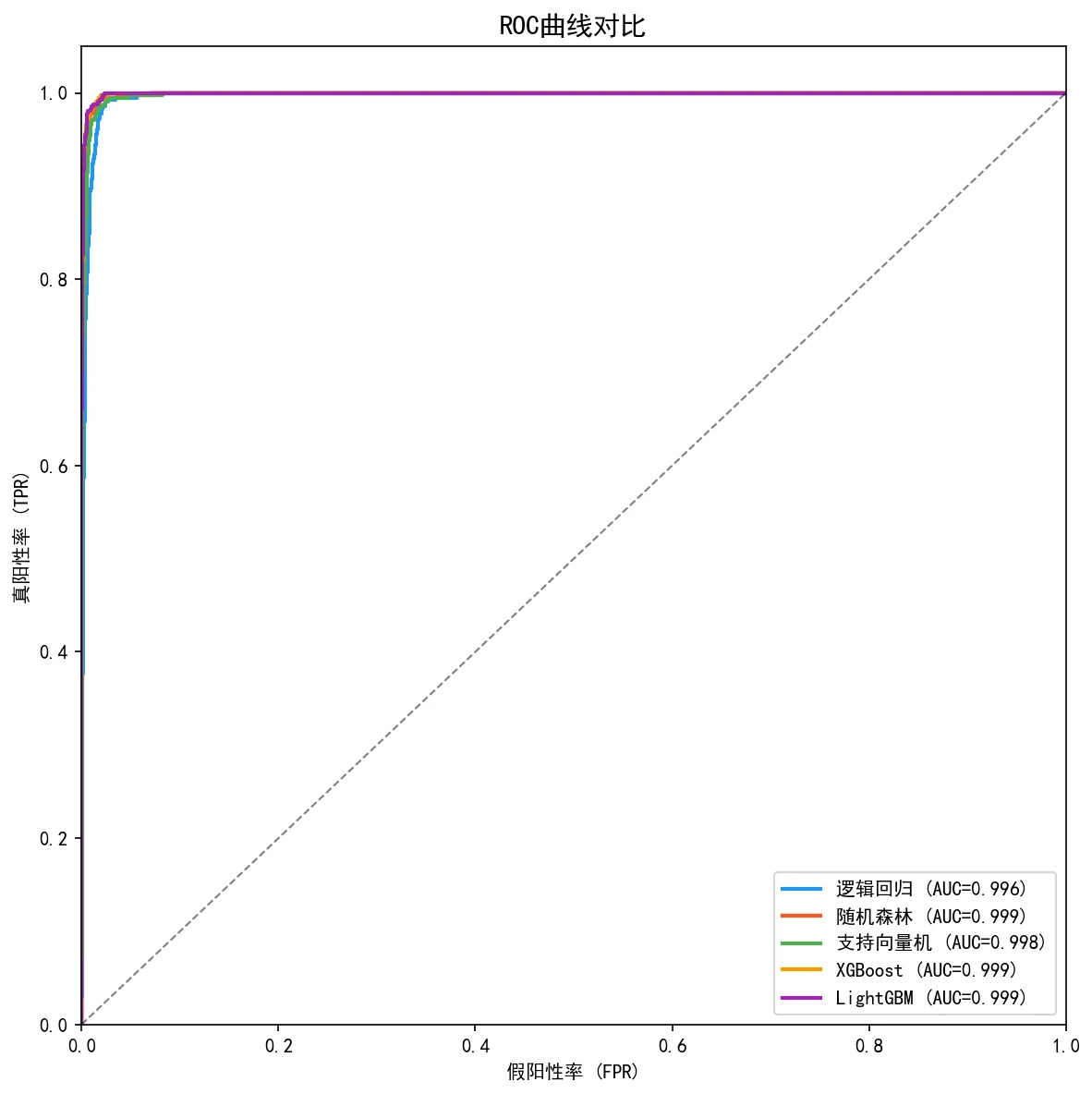
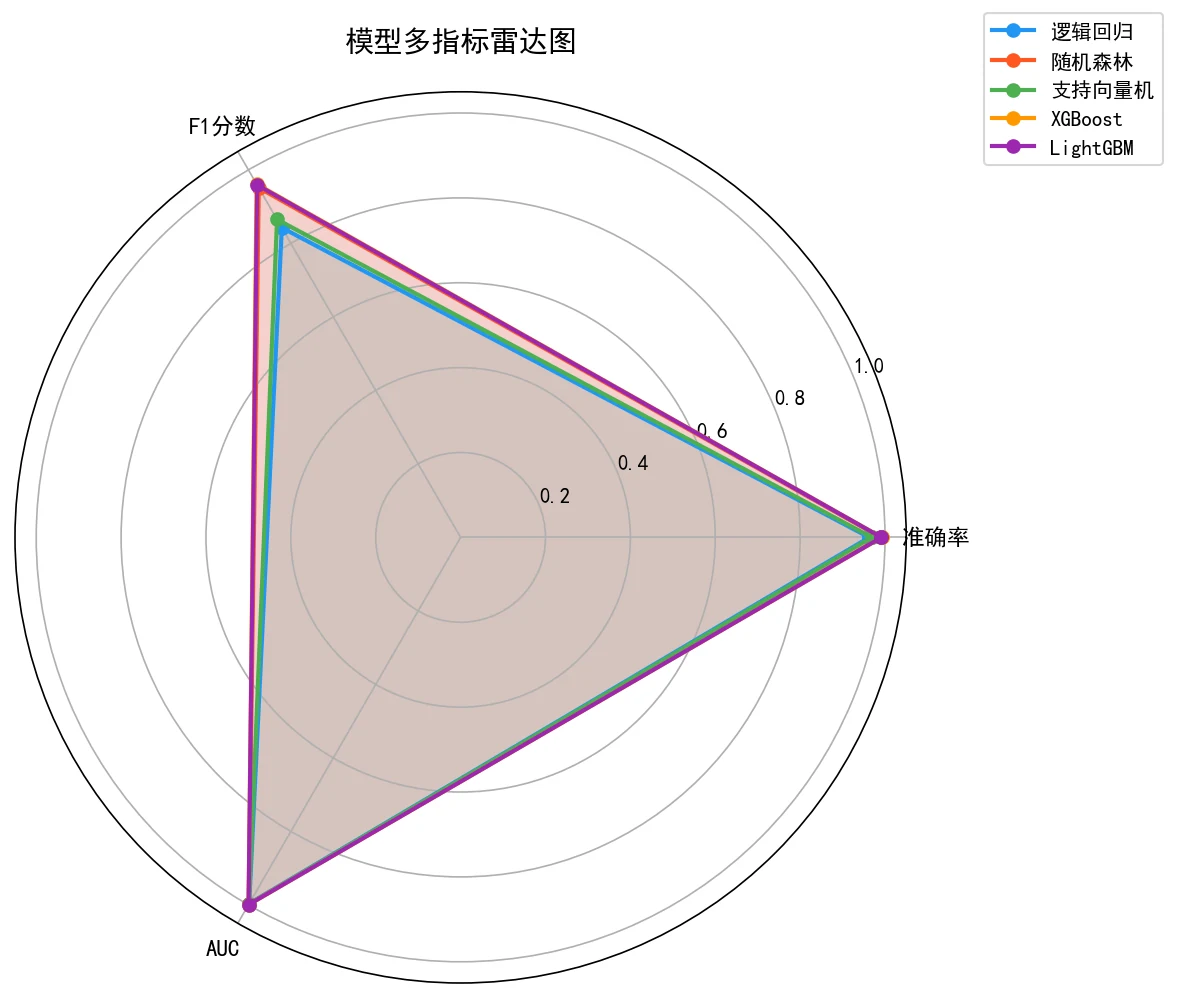
更关键的是,每张图怎么跑出来的、该怎么解读,技术文档里都讲清楚了——你能说明白每张图到底说明了什么。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
- 聚类特征为什么同时用 KMeans 和 DBSCAN,而不是选一个?
- 故障样本只占很小比例,你怎么避免模型偏向多数类?
- 综合评价为什么用熵权-TOPSIS,而不是只看准确率?
看到会愣一下?正常。配套的面试问答文档把这个项目——从整体思路到每个流程细节、各种可能被追问的点——连参考答案都给你写好了。另外还有现成的简历描述,照着改就能写进简历;那套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。
配套资料:搞懂一个项目需要的,这里全都有
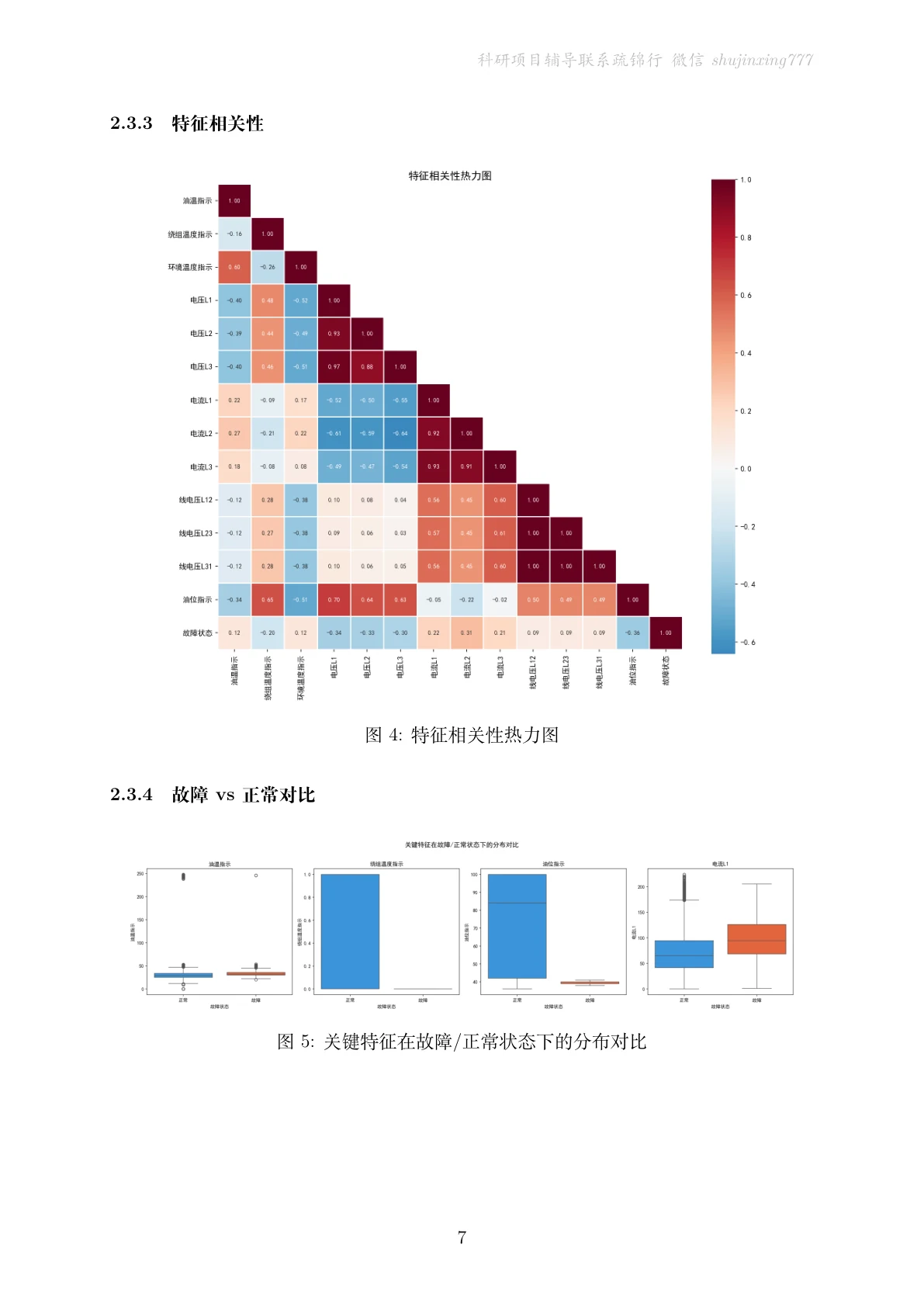
先看那份技术文档——从背景、聚类特征工程、不平衡处理一直讲到 TOPSIS 与 SHAP,图文并茂:

代码也给你了——关键部分都带着中文注释,帮你读懂"它到底是怎么实现的":
技术文档、面试问答、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添个有分量的项目,还是在准备面试,这个题目都接得住。专业上,电气工程、自动化、计算机、数据科学方向都很合适。预测性维护是电力工业的实际需求,把它真正搞懂、能讲出来,就是一个能写进简历、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「基于机器学习的变压器故障预测」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。