基于机器学习的生物碱抗菌活性预测
用 ChEMBL 抗菌活性数据做药物虚拟筛选:RDKit 分子描述符 + ECFP4 指纹拼成 1049 维特征,五模型对比 + 熵权-TOPSIS 客观选模 + SHAP 找关键子结构,一条完整的 QSAR 建模流水线——代码、技术文档、配图全配齐。
数据与任务
| 样本量 | ChEMBL · 1.04 万化合物 |
|---|---|
| 核心方法 | RDKit 特征 + 5 模型 |
| 技术栈 | RDKit · scikit-learn · SHAP |
如果你想找一个把"AI + 药物发现"做扎实、又能在面试里讲出门道的项目,这个「生物碱抗菌活性预测」很合适。
它的方向挺有分量——拿真实的药物分子数据,预测一个化合物有没有抗菌活性,本质就是计算机辅助药物设计里的虚拟筛选。配套也给你备齐了,帮你真正搞懂它、在面试和答辩里讲明白:带中文注释、能读懂的代码,一份从背景一路讲到 SHAP 可解释性的技术文档,里面连考研复试 / 面试会被追问的问题都连参考答案写好了,还有一整套能直接做 PPT 的配图。
先说清楚,它到底在做什么
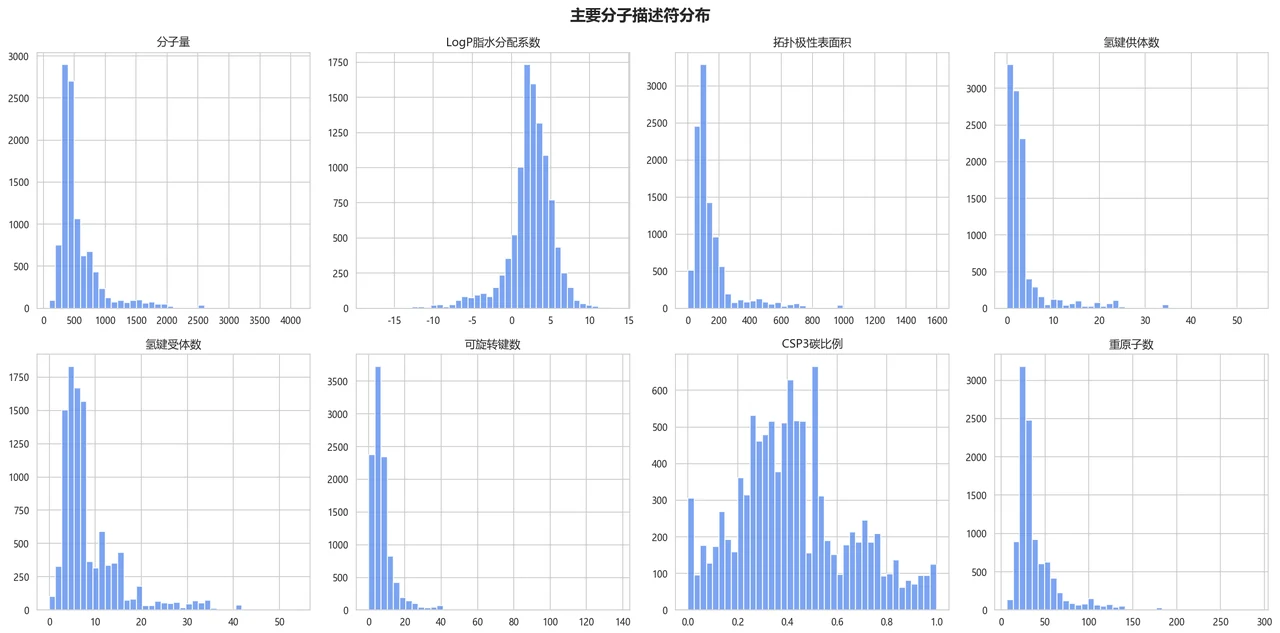
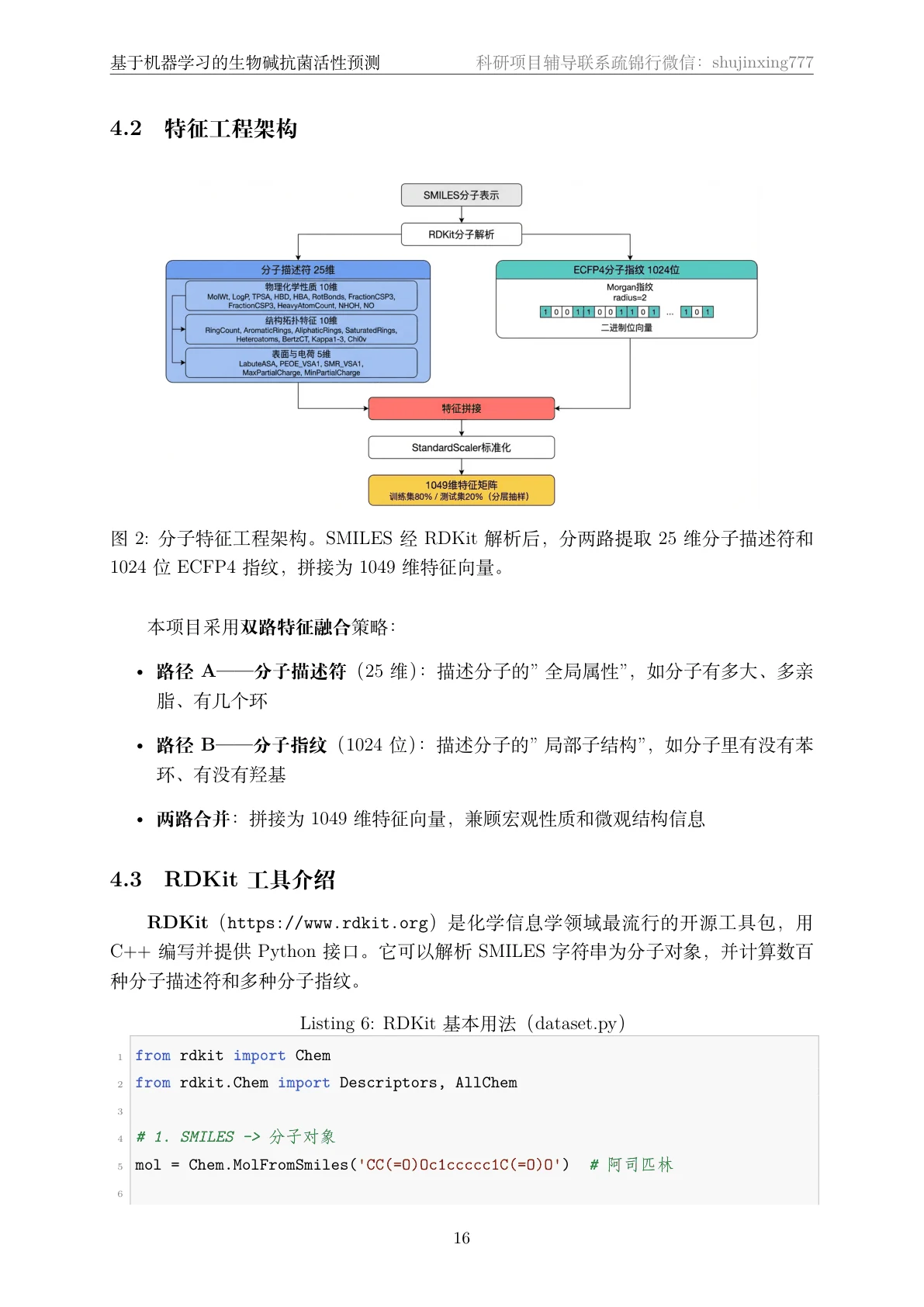
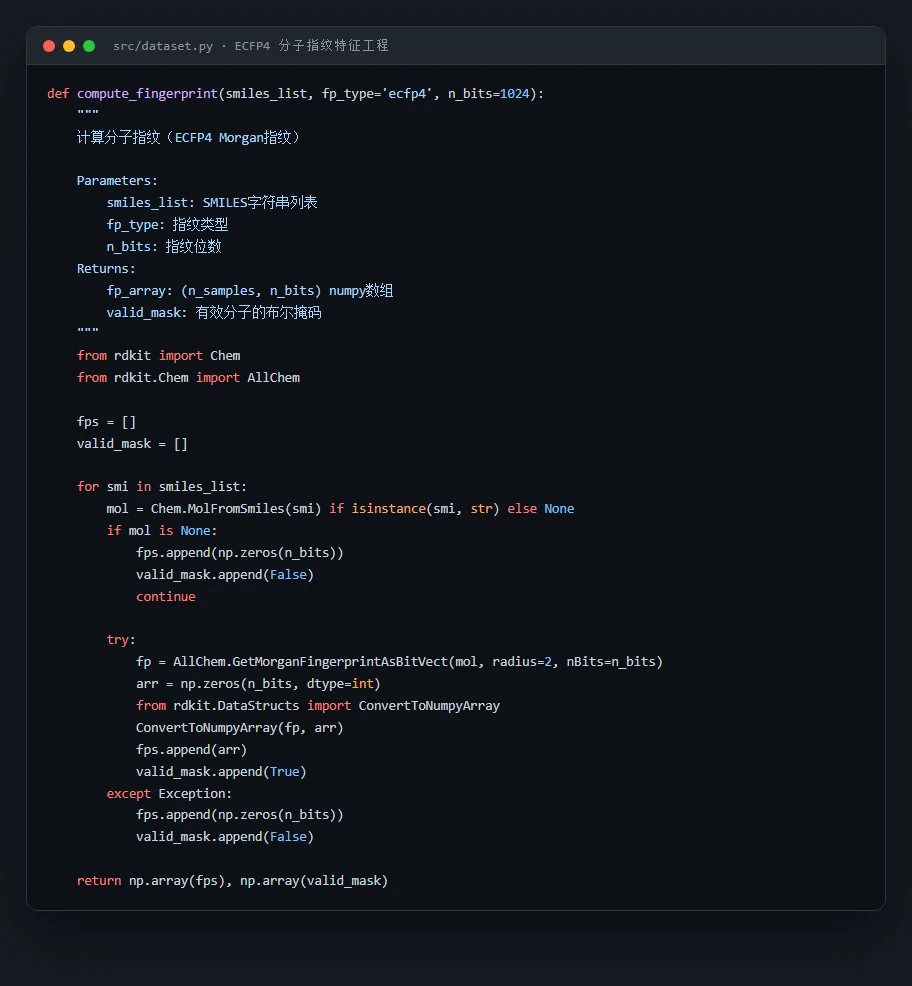
新药研发里,判断一个化合物有没有抗菌活性,传统做法是体外测最小抑菌浓度(MIC),成本高、周期长、通量低——几万个候选分子一个个做实验根本做不过来。难点在于:分子是一张张化学结构图,机器看不懂,得先想办法把"结构"变成模型能算的数字特征,而且既要表达分子整体的物理化学性质,又要捕捉到决定药效的局部子结构片段。
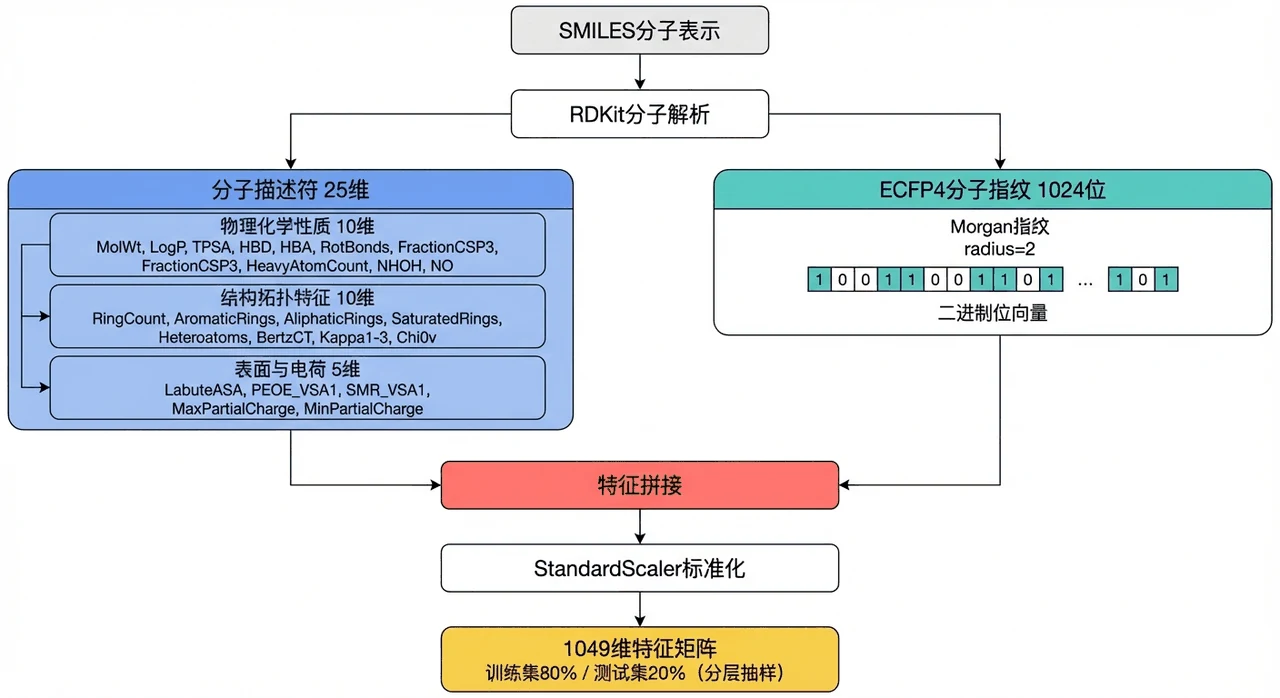
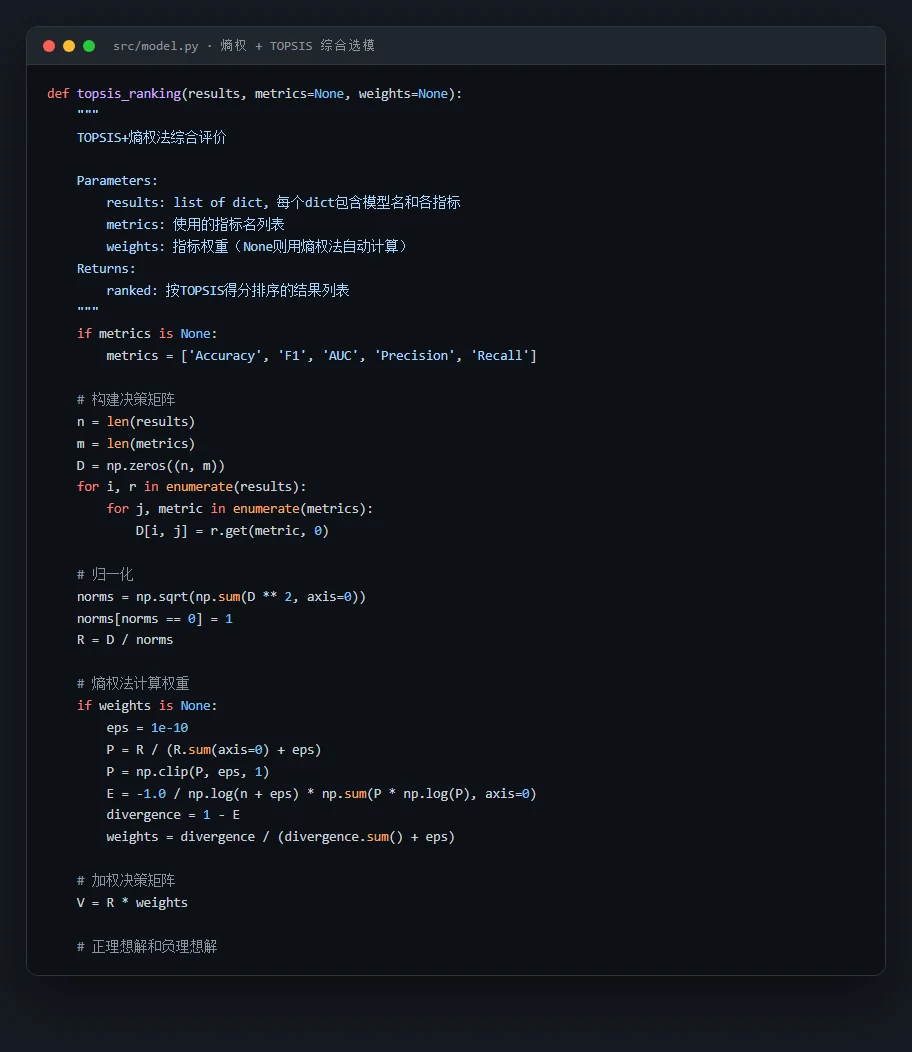
这个项目从 ChEMBL 数据库里金黄色葡萄球菌的 1 万多条真实 MIC 活性数据出发,搭了一条完整的 QSAR(定量构效关系)建模流水线:先把每个分子的 SMILES 用 RDKit 解析,分两路提特征——一路算 25 维分子描述符(分子量、LogP 亲脂性、拓扑结构等),一路生成 1024 位 ECFP4 指纹(把分子里每个原子邻域的子结构编码成二进制位),拼成 1049 维特征向量;再对比五种经典模型并调参,用熵权-TOPSIS 客观选出最优模型,最后用 SHAP 找出到底哪些分子特征在驱动"有没有活性"的判断。
搞懂它,你能在面试里讲清楚什么
把下面几件事吃透,面试官顺着问下来你都能接得住。
分子怎么变成特征——描述符和指纹各管什么,为什么要融合。 这是整个项目的地基,也是和普通"调包分类"项目拉开差距的地方。你要能讲清楚:分子描述符告诉模型"这个分子有多大、多亲脂",是全局的理化性质;ECFP4 指纹则把每个原子周围的局部子结构编码成位,告诉模型"这个分子包含哪些药效团片段",类似 NLP 里的 n-gram。两者互补,所以拼成 1049 维一起喂给模型。
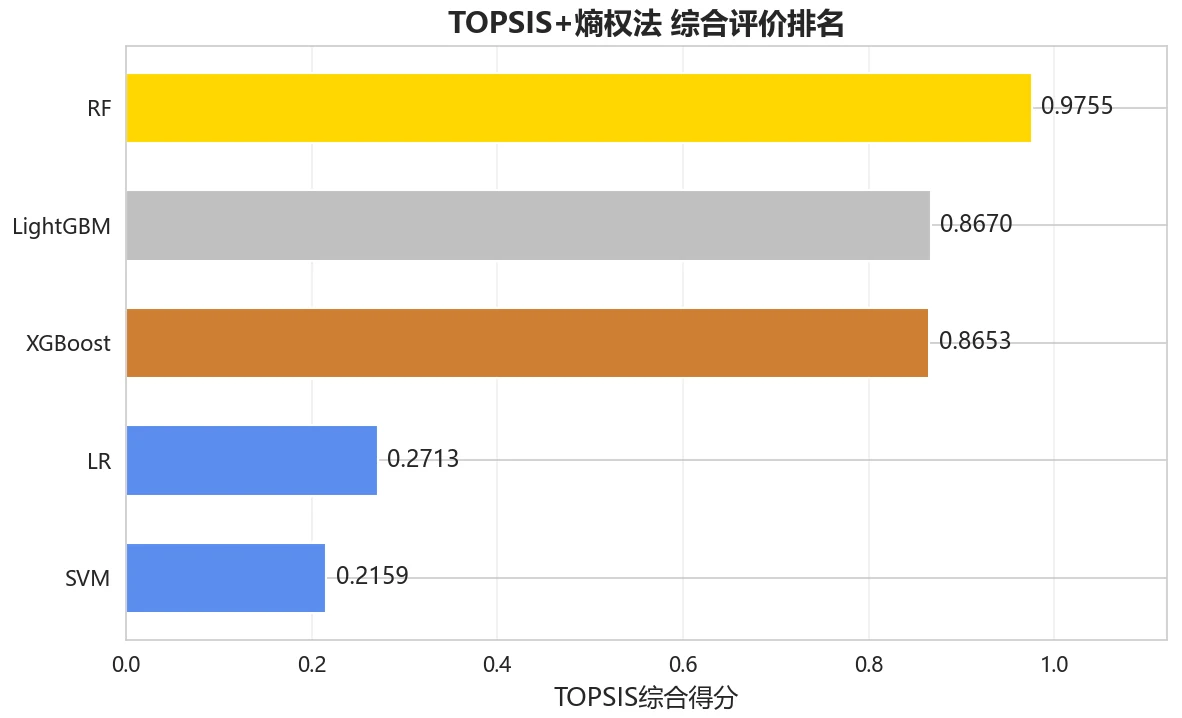
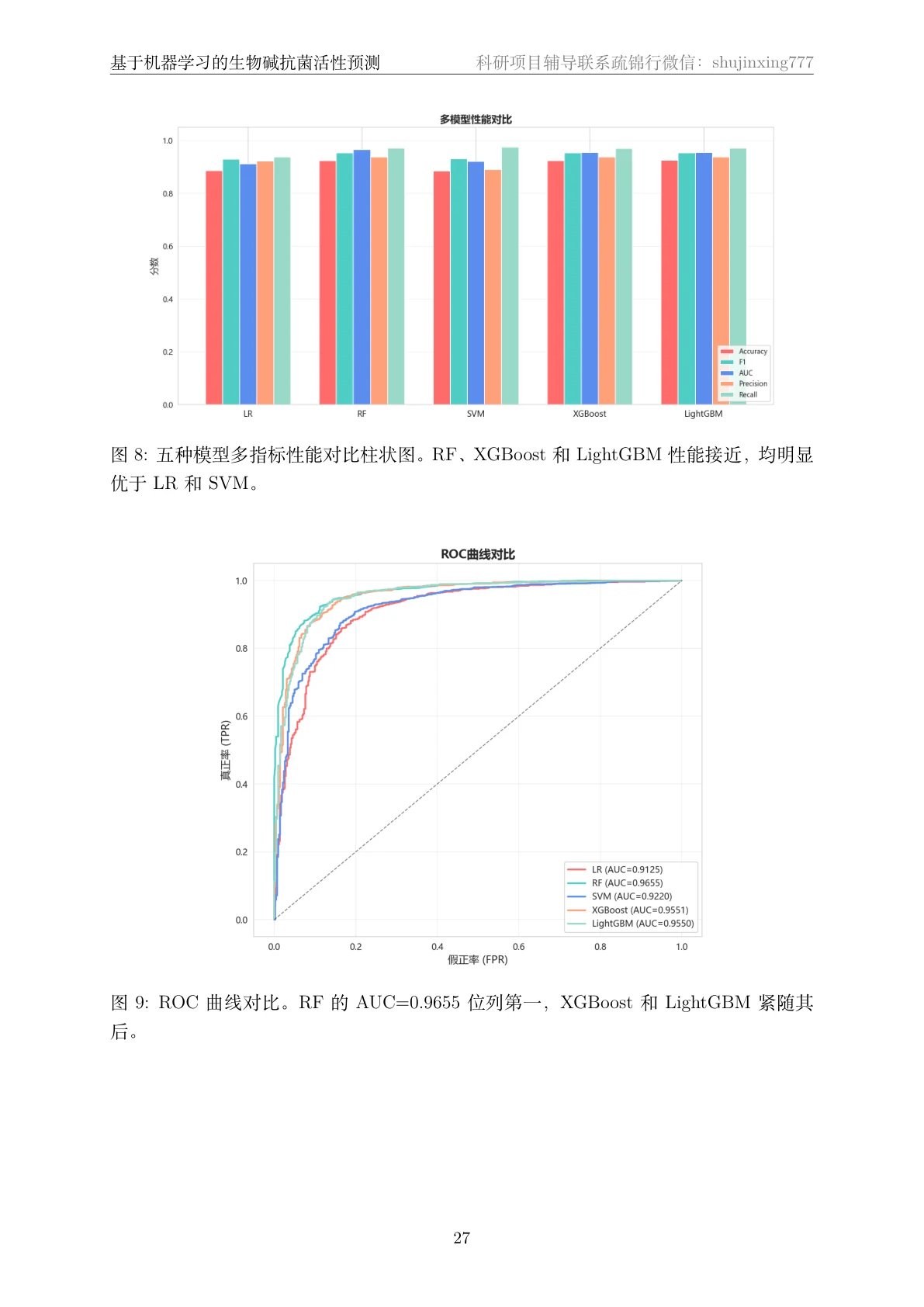
为什么对比五种模型,又怎么客观选出最优。 项目对比了逻辑回归、随机森林、SVM、XGBoost、LightGBM 五种模型,并用熵权-TOPSIS 把准确率、F1、AUC 等多个指标综合成一个客观得分来排名——而不是凭感觉挑。你能借此讲清楚:在这种高维稀疏的指纹特征上,树模型(随机森林、梯度提升)为什么往往明显优于线性模型,以及多指标该怎么客观权衡。
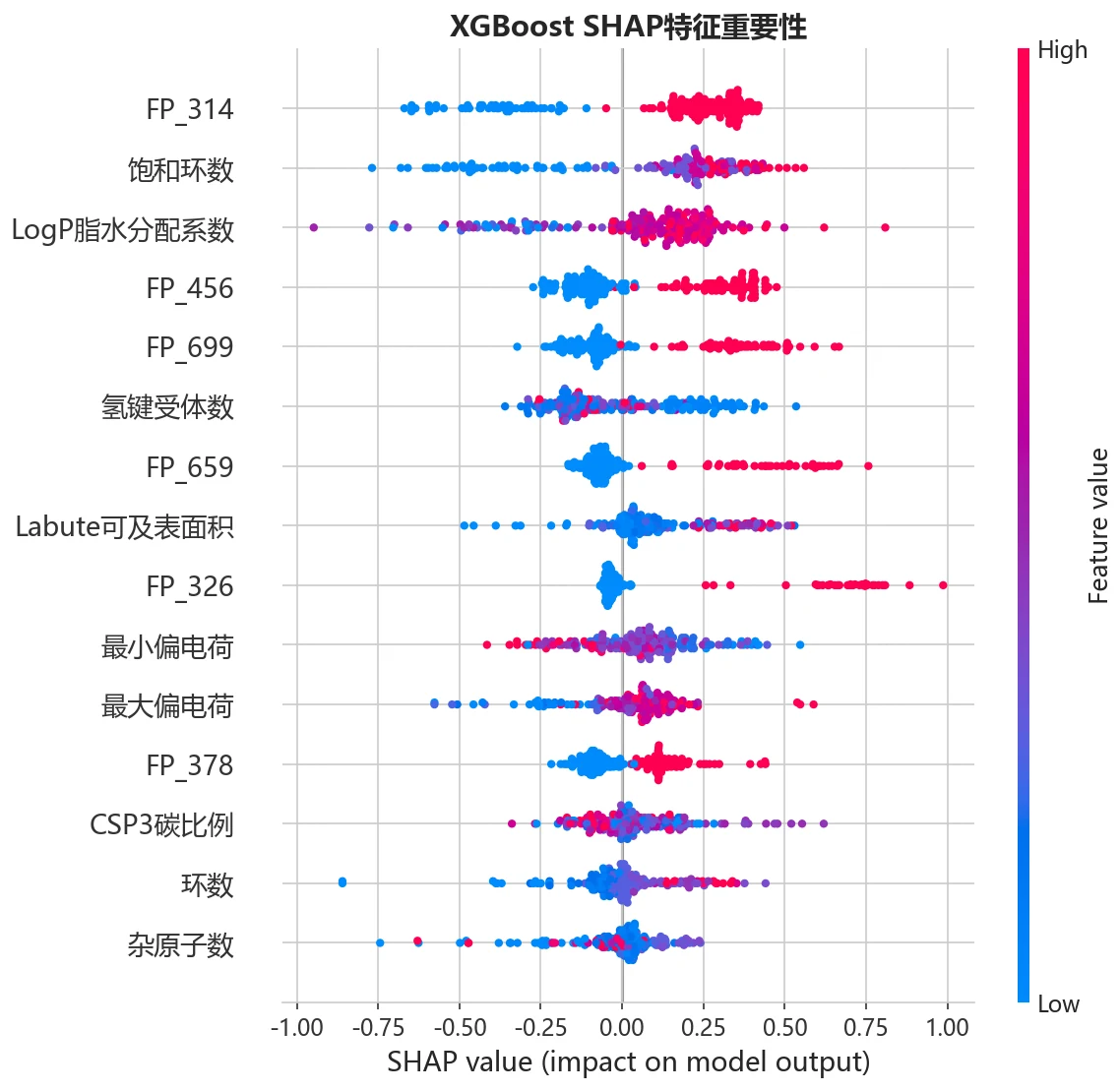
SHAP 怎么把模型讲成"看得懂的关键子结构"。 SHAP 能排出哪些分子特征最推动"有活性"的判断——比如某个指纹位对应的子结构片段、饱和环数、亲脂性 LogP,让黑盒模型变透明,也和药物化学的先验知识对得上。这一步在药物发现场景里特别加分,因为它能反过来给"什么结构更可能抗菌"提供线索。
下面这组分析图也都给你做好了,可以直接放进答辩或面试 PPT:
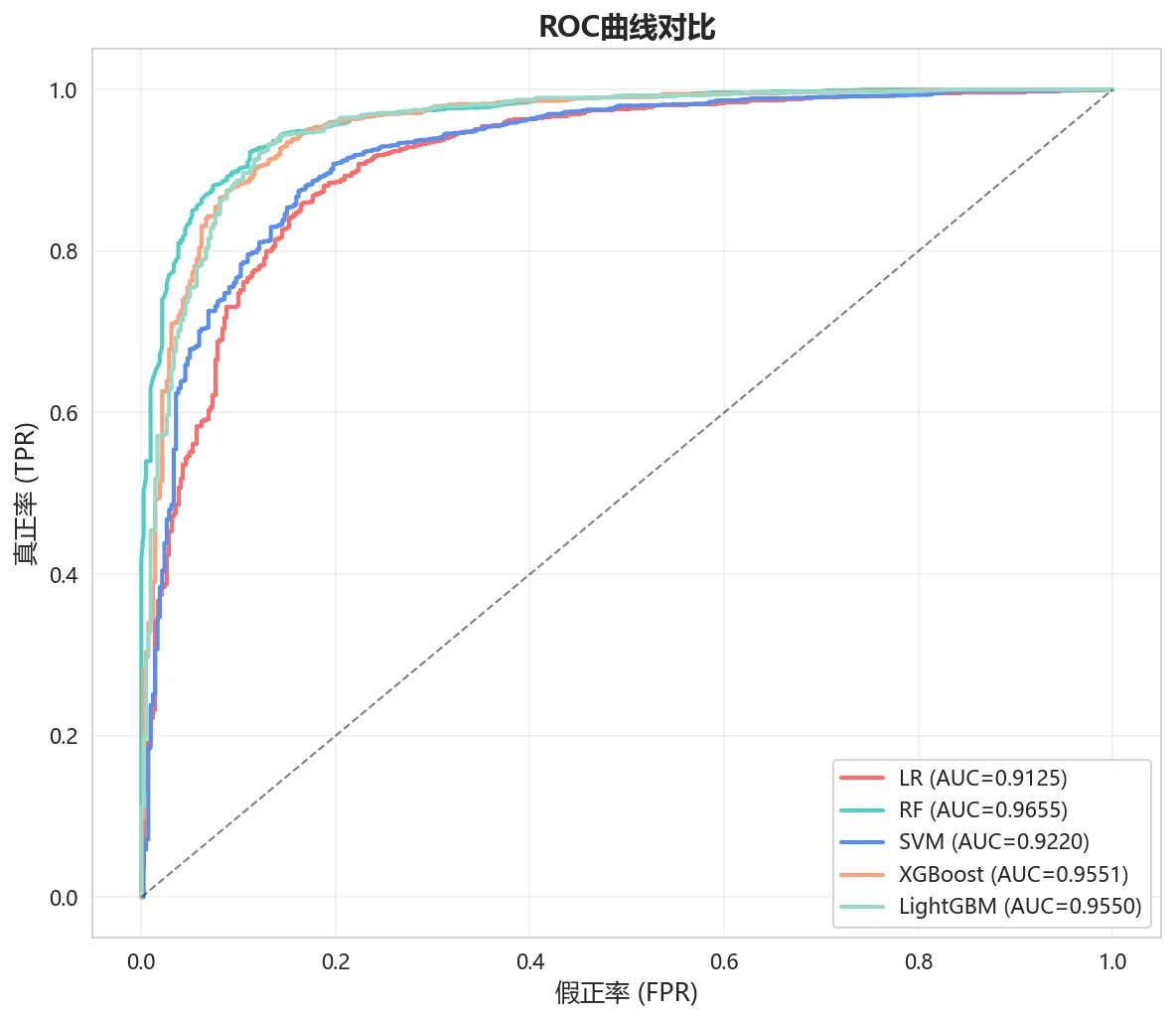
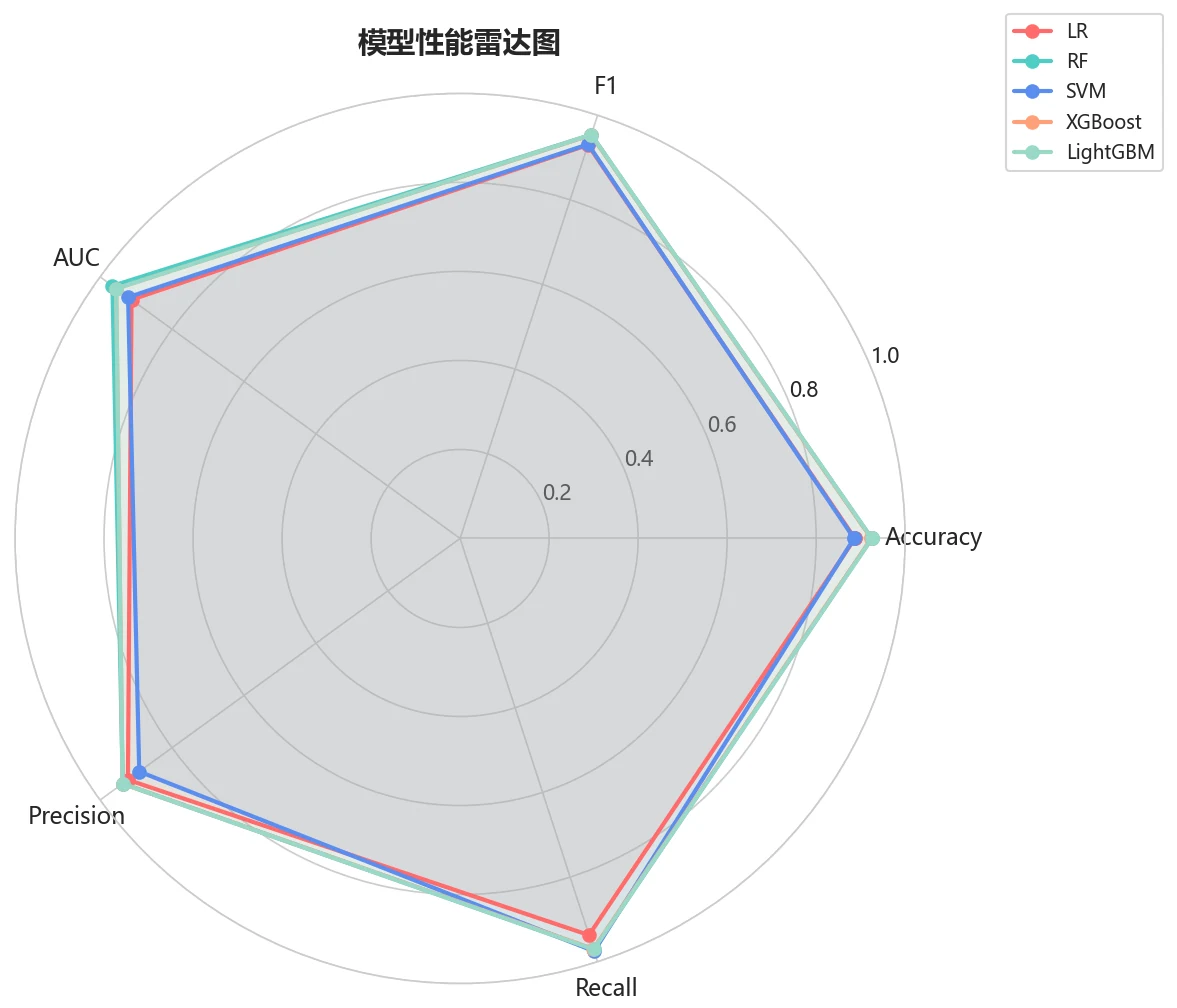
更关键的是,每张图怎么跑出来的、该怎么解读,技术文档里都讲清楚了——你能说明白每张图到底在说什么,而不是只会贴图。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
- 分子描述符和 ECFP4 指纹分别表达什么?为什么要把两者融合,而不是只用其一?
- ECFP4 指纹的"半径 2、1024 位"是什么意思?这个组合怎么来的?
- 为什么随机森林在这个任务上表现最好,而逻辑回归差一截?
- 数据正负样本不平衡,你是怎么处理、又该看哪些指标的?
看到会愣一下?正常。配套的技术文档里专门有一节,把这个项目——从整体思路到每个流程细节、各种可能被追问的点——连参考答案都给你写好了。另外还有现成的简历描述(学术版 / 工程版 / 面试精简版都备了),照着改就能写进简历;那套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。
配套资料:搞懂一个项目需要的,这里全都有
先看那份技术文档——从天然药物背景、ChEMBL 数据清洗、RDKit 特征工程,一直讲到 TOPSIS 选模与 SHAP 可解释性,图文并茂、推导清楚:

代码也给你了——关键部分都带着中文注释,帮你读懂"它到底是怎么实现的":
技术文档、面试问答、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添个有分量的交叉学科项目,还是在准备面试 / 考研复试,这个题目都接得住。专业上,计算机、人工智能、生物信息、药学、化学、数据科学方向都很合适——它把机器学习和真实的药物发现场景结合在一起,既有 RDKit 分子特征工程的硬核细节,又有完整的建模、选模、可解释性闭环。把这条 QSAR 流水线真正搞懂、能讲出来,就是一个有故事、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「基于机器学习的生物碱抗菌活性预测」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。