基于机器学习的阿尔茨海默症风险预测
从常规体检与认知量表数据预测阿尔茨海默症风险:6 类共 34 个特征 + 四模型对比 + GridSearchCV 调参 + 阈值优化 + 熵权-TOPSIS 选模 + SHAP 找关键风险因子,一条可解释的医疗风险预测流水线,代码、文档、讲解资料全配齐。
项目亮点
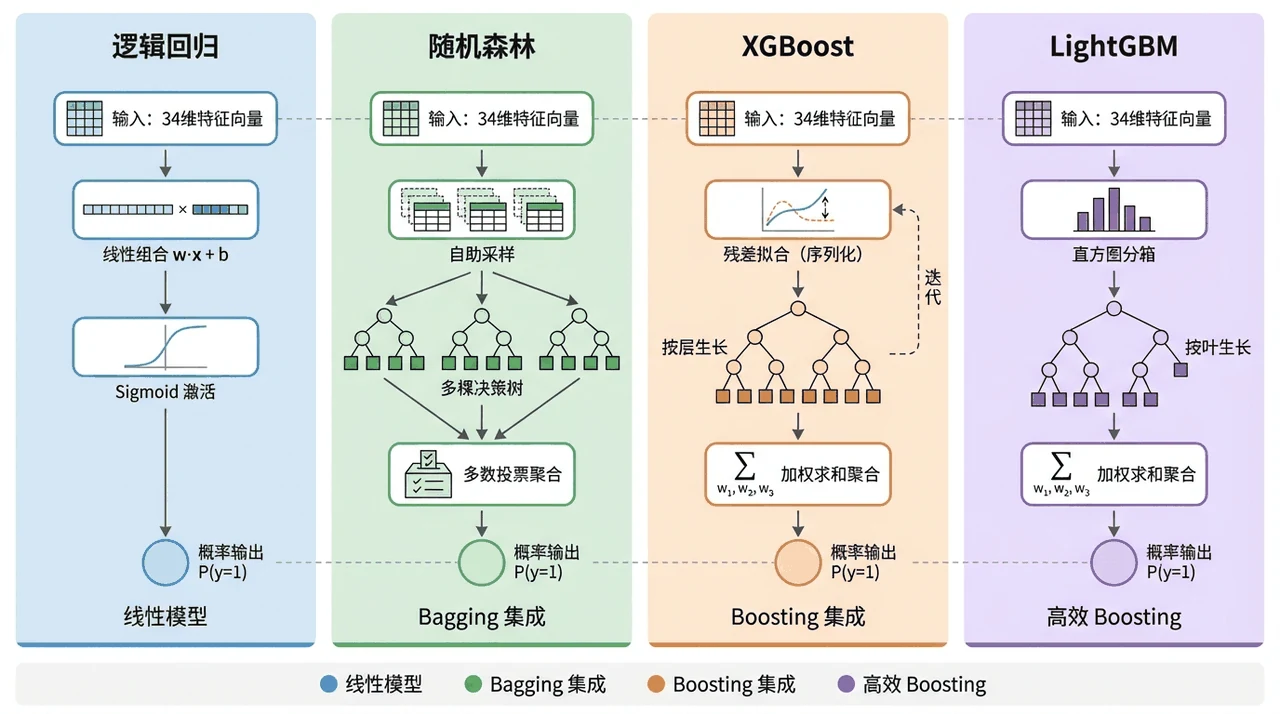
- 4种模型对比:逻辑回归 / 随机森林 / XGBoost / LightGBM
- GridSearchCV调参:网格搜索 + 3折交叉验证
- 阈值优化:在验证集上搜索最优分类阈值,LightGBM阈值=0.32
- TOPSIS+熵权法:多指标综合评价模型优劣
数据与任务
| 样本量 | 公开数据集 · 2149 患者 · 34 特征 |
|---|---|
| 核心方法 | 四模型对比 + TOPSIS 选模 |
| 技术栈 | LightGBM · scikit-learn · SHAP |
如果你想找一个把"医疗 AI + 可解释机器学习"做扎实、又好上手的项目,这个「阿尔茨海默症风险预测」很合适。
它做的是一件有临床价值的事:传统 AD 诊断要靠脑脊液检测和 MRI 影像,成本高、难普及;这个项目换个思路,只用血压、胆固醇、BMI 这类常规体检指标,加上 MMSE、ADL 等简单认知量表,就能给出一个可解释的患病风险判断,为社区早期筛查提供低成本的数据支撑。配套也给你备齐了,帮你真正搞懂它、在面试和答辩里讲明白:带中文注释、能读懂的代码,一份从背景讲到每步实现的技术文档,一套把面试问题连参考答案都写好的项目讲解资料,还有一整套能直接做 PPT 的配图。
先说清楚,它到底在做什么
阿尔茨海默病是全球最常见的神经退行性疾病。临床上的难点在于:早期识别高风险人群才能及时干预、延缓病程,但确诊手段都偏贵偏复杂,没法在社区层面铺开。能不能从已有的常规数据里,把风险算出来?
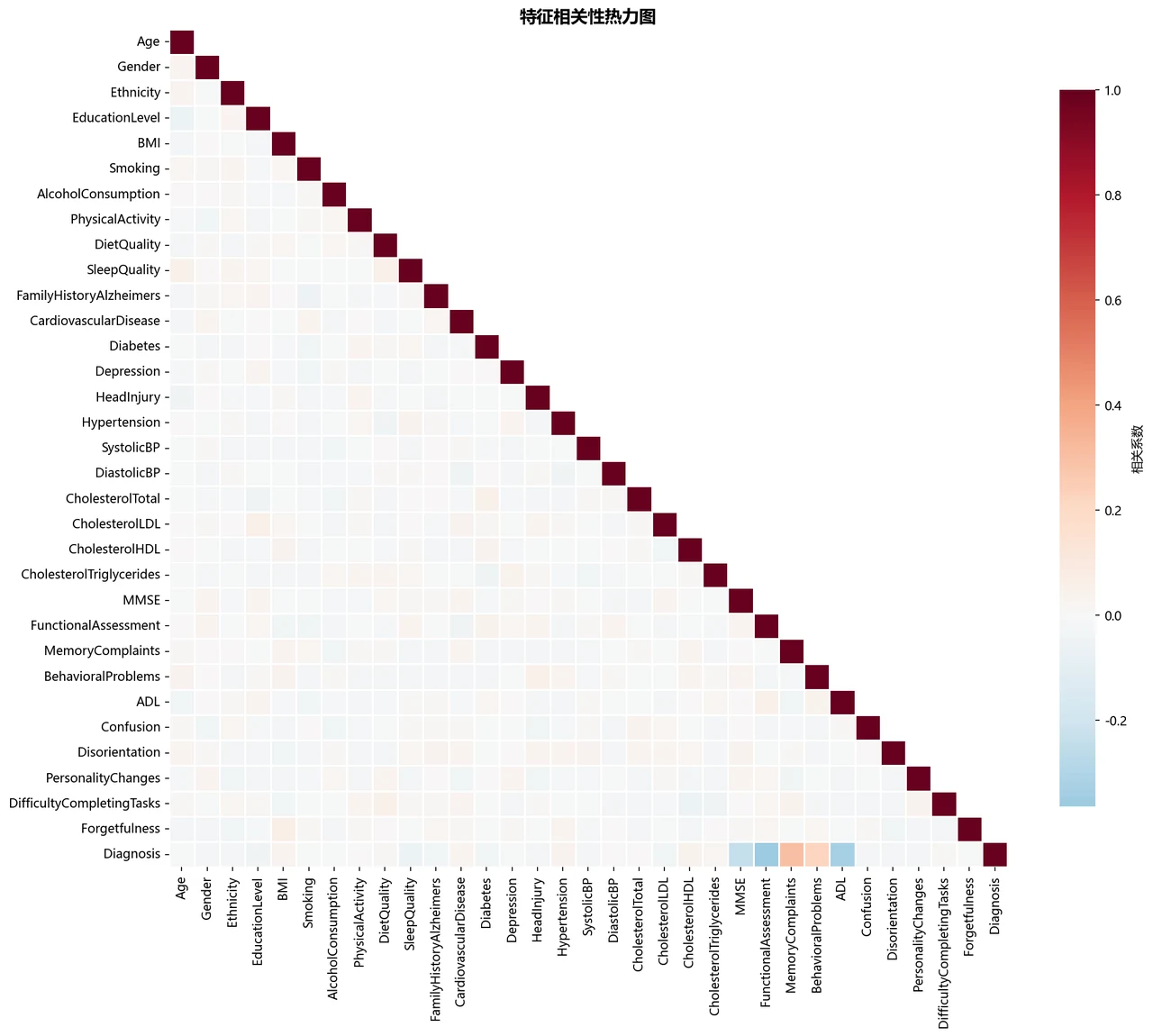
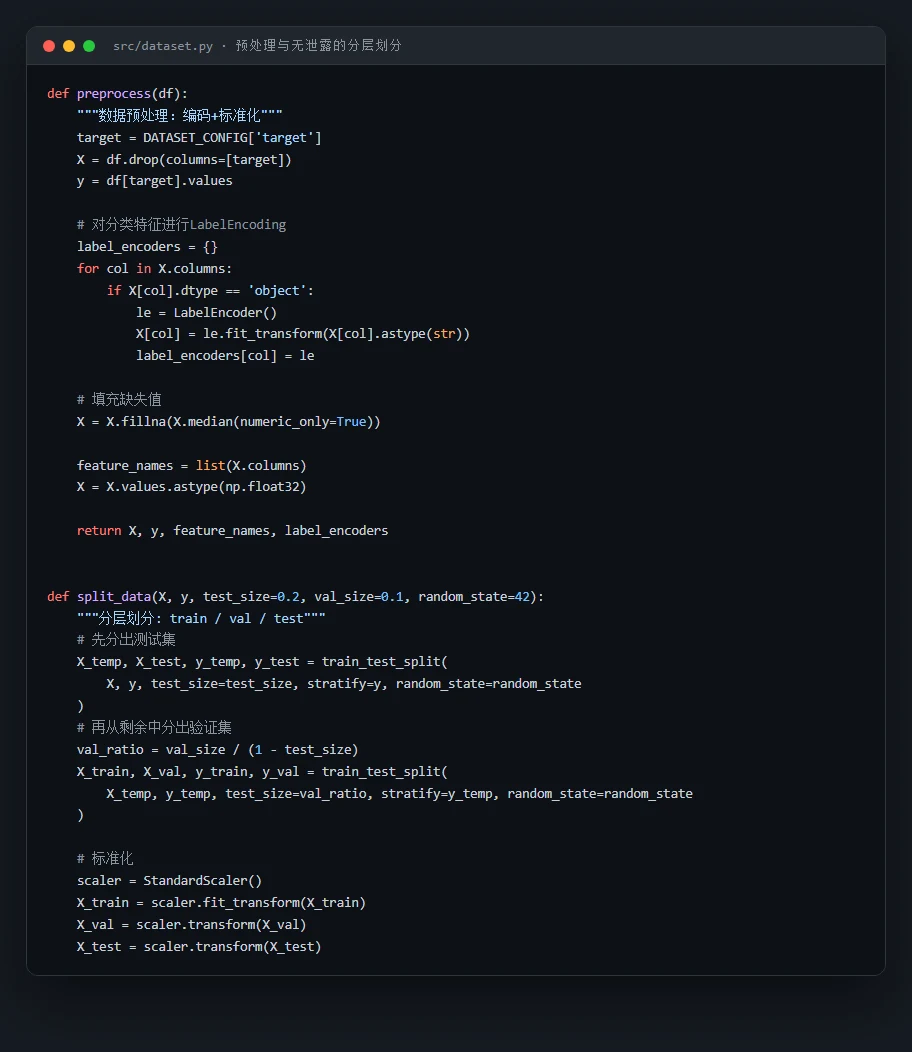
这个项目从一份公开的患病数据集出发,覆盖人口统计、生活方式、病史、临床指标、认知评估、症状六大类、共 34 个特征。它搭了一条完整的表格数据建模流水线:先做编码与标准化、再做严格防泄露的分层划分,对比逻辑回归、随机森林、XGBoost、LightGBM 四种模型并用 GridSearchCV 调参,接着用阈值优化提升召回,用熵权-TOPSIS 客观选出综合最优模型,最后用 SHAP 把"哪些因素最推高风险"讲清楚。
搞懂它,你能在面试里讲清楚什么
把下面几件事吃透,面试官顺着问下来你都能接得住。
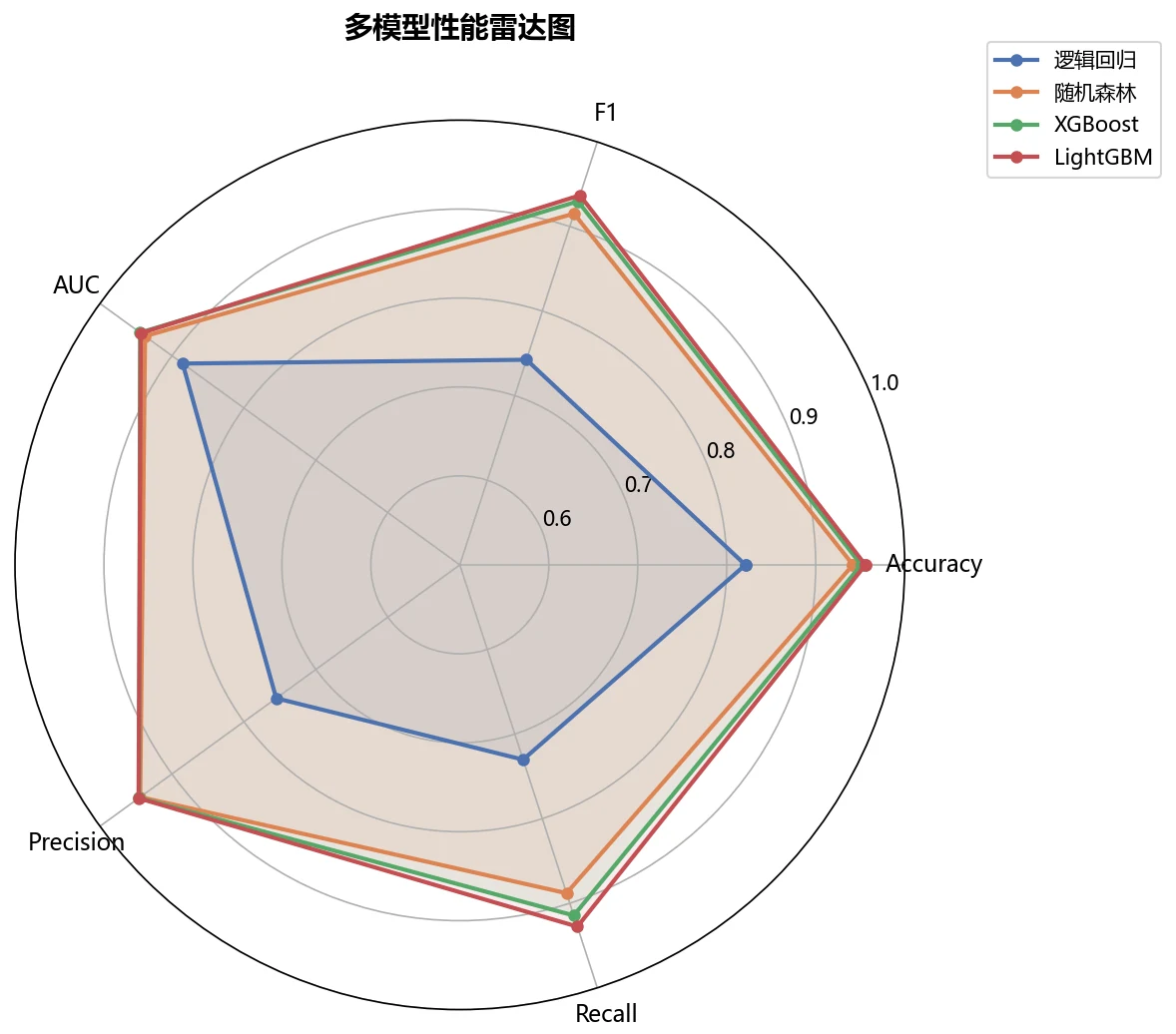
为什么对比四种模型,又怎么客观选出最优的那个。 这是主线。四种模型代表线性、Bagging 集成、Boosting 集成三个建模范式,你要能讲清楚它们的取舍,以及为什么在这类含复杂非线性交互的风险因素上,集成树往往明显优于线性模型。更进一步——用熵权法自动定权、再用 TOPSIS 对五个指标做综合排名,你能借此讲清楚"为什么不靠单一指标拍脑袋选模型"。
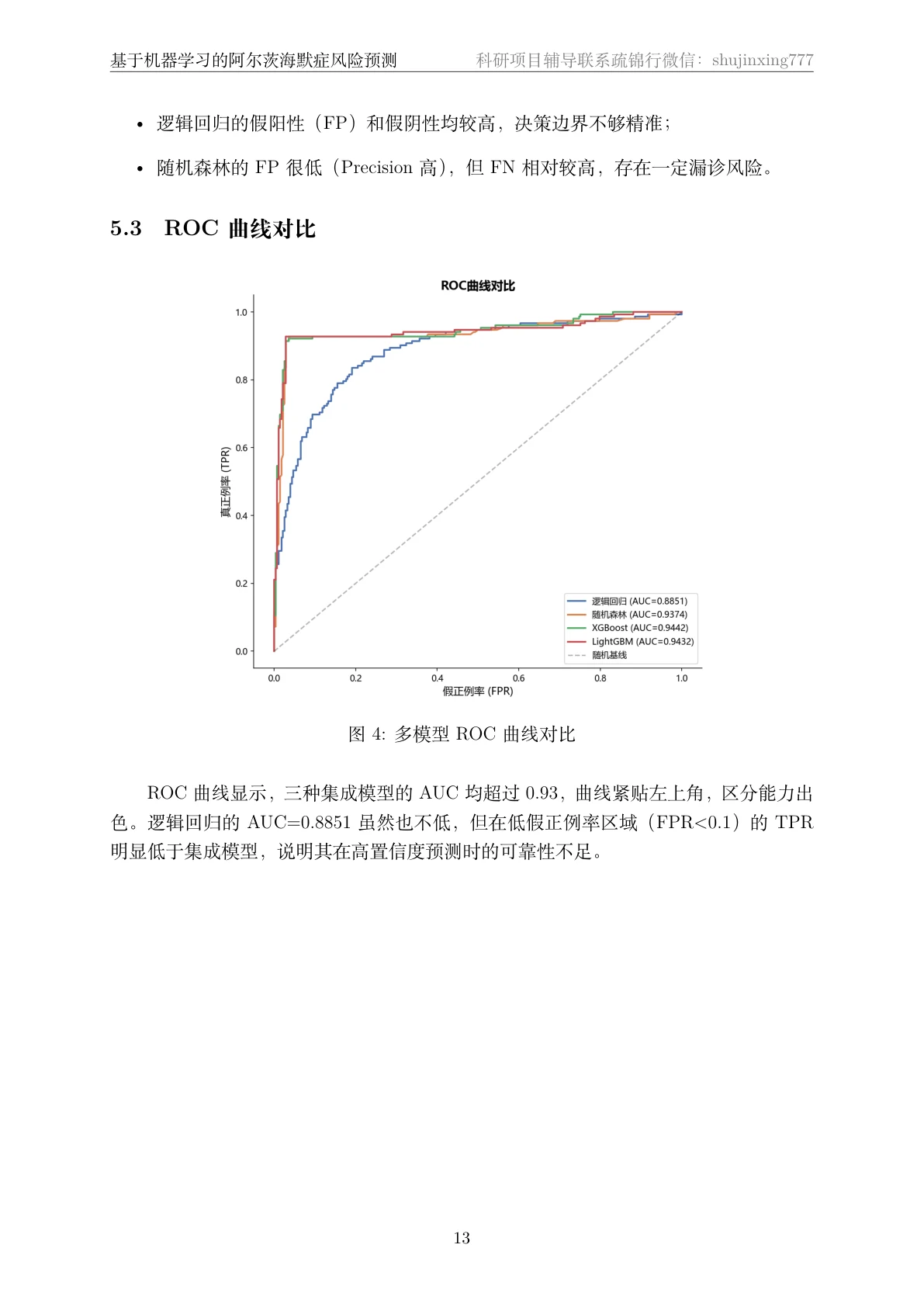
阈值优化在医疗场景里的意义。 默认 0.5 的分类阈值不一定最优。项目在验证集上搜索最优阈值,结果落在 0.5 以下——意味着模型更倾向判为阳性、提高召回。你要能讲清楚这背后的临床逻辑:筛查里漏诊一位患者的代价,远比误诊一次要大。
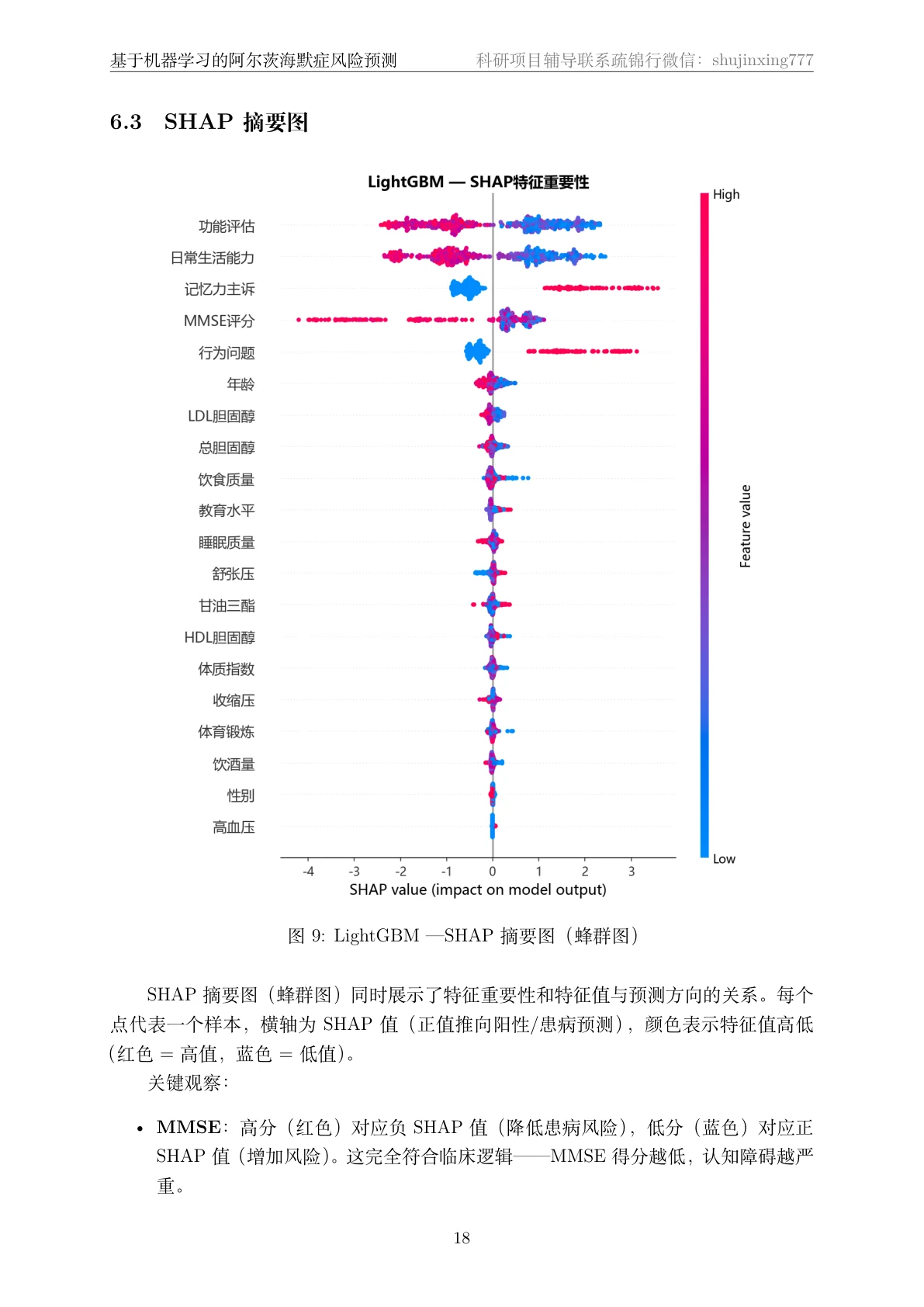
SHAP 怎么把模型讲成"看得懂的风险因子"。 SHAP 基于 Shapley 值,能精确算出每个特征对每次预测的贡献,既给全局重要性、也给单个患者的个性化归因。你能借此讲清楚医疗 AI 为什么必须可解释——模型不光要给结论,还要说清"为什么是这个人风险高"。
下面这组分析图也都给你做好了,可以直接放进答辩或面试 PPT:
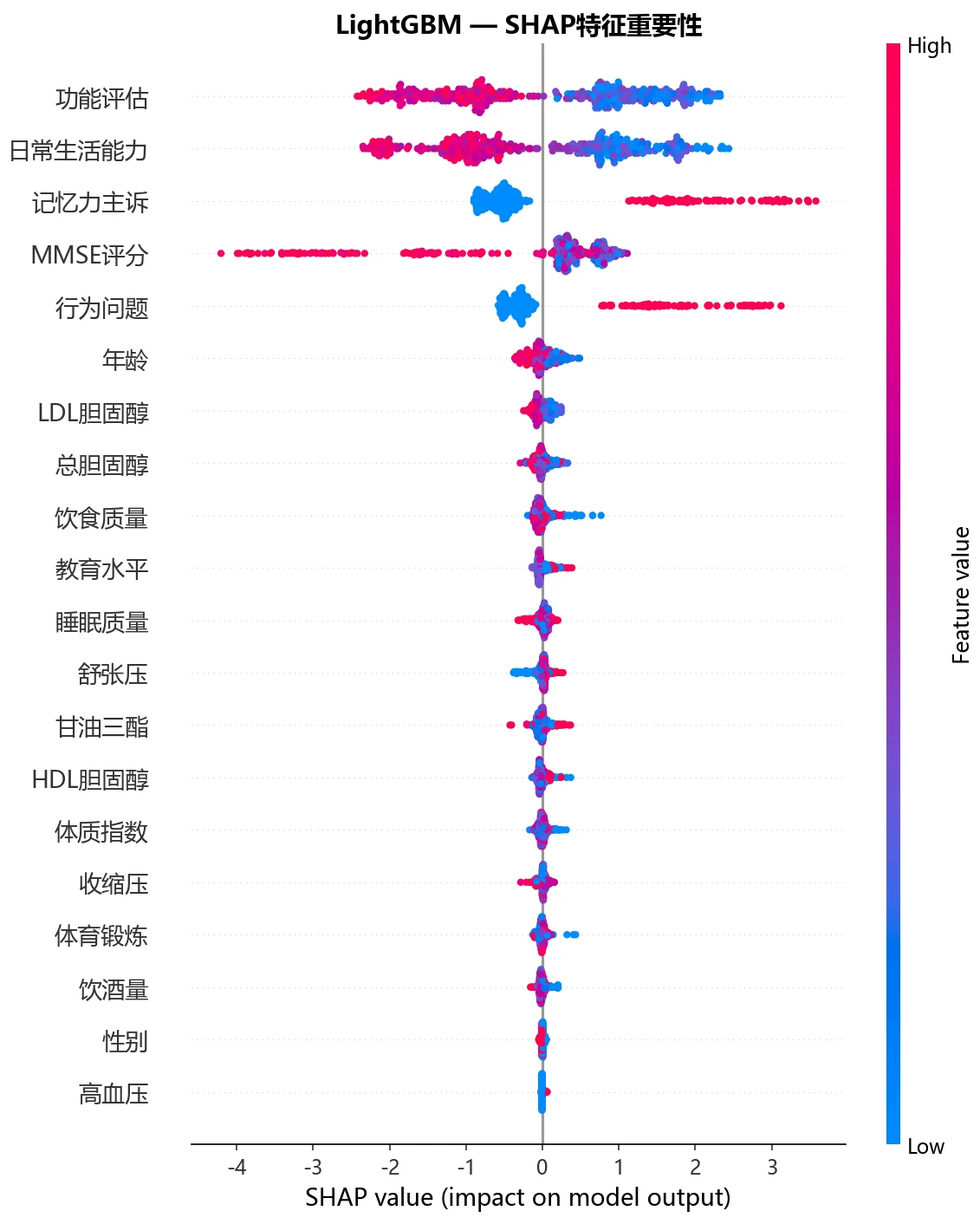
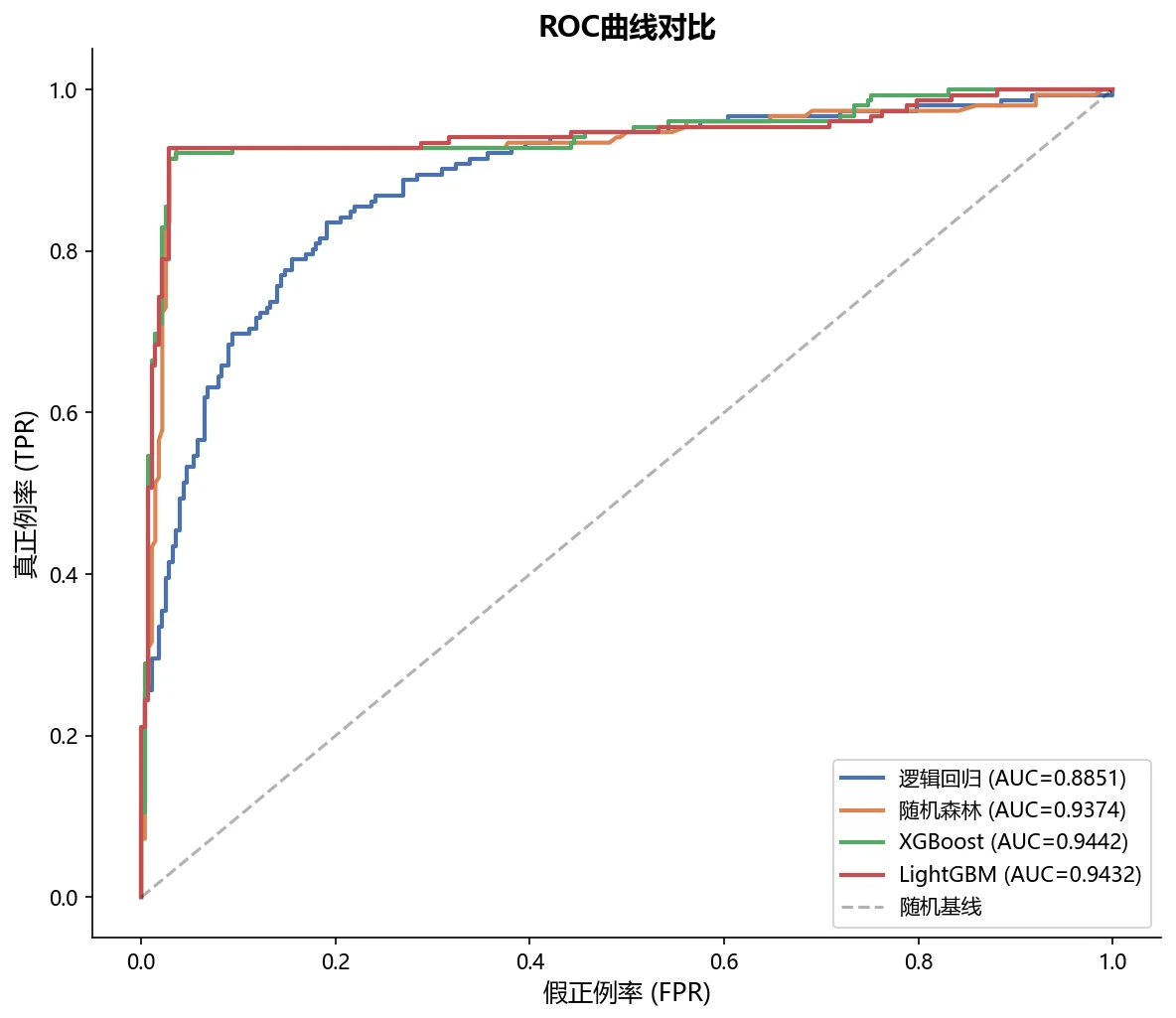
更关键的是,每张图怎么跑出来的、该怎么解读,技术文档里都讲清楚了——比如 SHAP 摘要图里"认知量表低分→风险升高"的单调关系,和临床认知完全吻合,你能把这层意思说明白。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
- 阈值优化是在调什么?为什么医疗筛查里最优阈值常常低于 0.5?
- 熵权-TOPSIS 是怎么把五个指标综合成一个排名的?为什么不直接看准确率?
- 标准化为什么只能在训练集上 fit?不这么做会出什么问题?
看到会愣一下?正常。配套的项目讲解资料把这个项目——从整体思路到每个流程细节、各种可能被追问的点——连参考答案都给你写好了。另外还有现成的简历描述,照着改就能写进简历;那套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。
配套资料:搞懂一个项目需要的,这里全都有
先看那份技术文档——从背景、数据预处理、四模型对比一直讲到 TOPSIS 与 SHAP,图文并茂:

代码也给你了——关键部分都带着中文注释,帮你读懂"它到底是怎么实现的":
技术文档、项目讲解资料、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添个有分量的项目,还是在准备面试,这个题目都接得住。专业上,计算机、人工智能、软件工程、数据科学、生物医学工程、公共卫生方向都很合适。表格数据的风险预测是机器学习落地最广的一类任务,把"多模型对比 + 客观选模 + 可解释性"这条完整流水线真正搞懂、能讲出来,就是一个能写进简历、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「基于机器学习的阿尔茨海默症风险预测」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。