基于机器学习的语音性别预测
从 20 维声学特征预测说话人性别:五模型对比(LR/RF/SVM/XGBoost/LightGBM)+ GridSearchCV 调参 + 熵权-TOPSIS 客观选模 + 阈值优化 + SHAP 找关键声学特征,一条完整的表格 ML 流水线,代码、文档、讲解资料全配齐。
数据与任务
| 样本量 | Kaggle · 3168 语音样本 |
|---|---|
| 核心方法 | 5 模型 + TOPSIS 选模 |
| 技术栈 | scikit-learn · XGBoost · SHAP |
如果你想找一个把机器学习分类全流程做扎实、又好上手的项目,这个「用声音判断性别」的题目很合适。
它是一个完整的表格机器学习案例,配套也给你备齐了,帮你真正搞懂它、在面试和答辩里讲明白:带中文注释、能读懂的代码,一份从背景讲到每步实现的技术文档,一份把可能被追问的问题连答案都写好的项目讲解资料,还有一整套能直接做 PPT 的配图。
先说清楚,它到底在做什么
听一段声音就能判断说话人是男是女,人耳很容易,但要让机器自动做到,得先回答一个问题:声音里到底是哪些可量化的特征在区分性别?难点在于,原始语音是一段连续波形,没法直接喂给分类器,必须先把它变成一组结构化的数字特征。
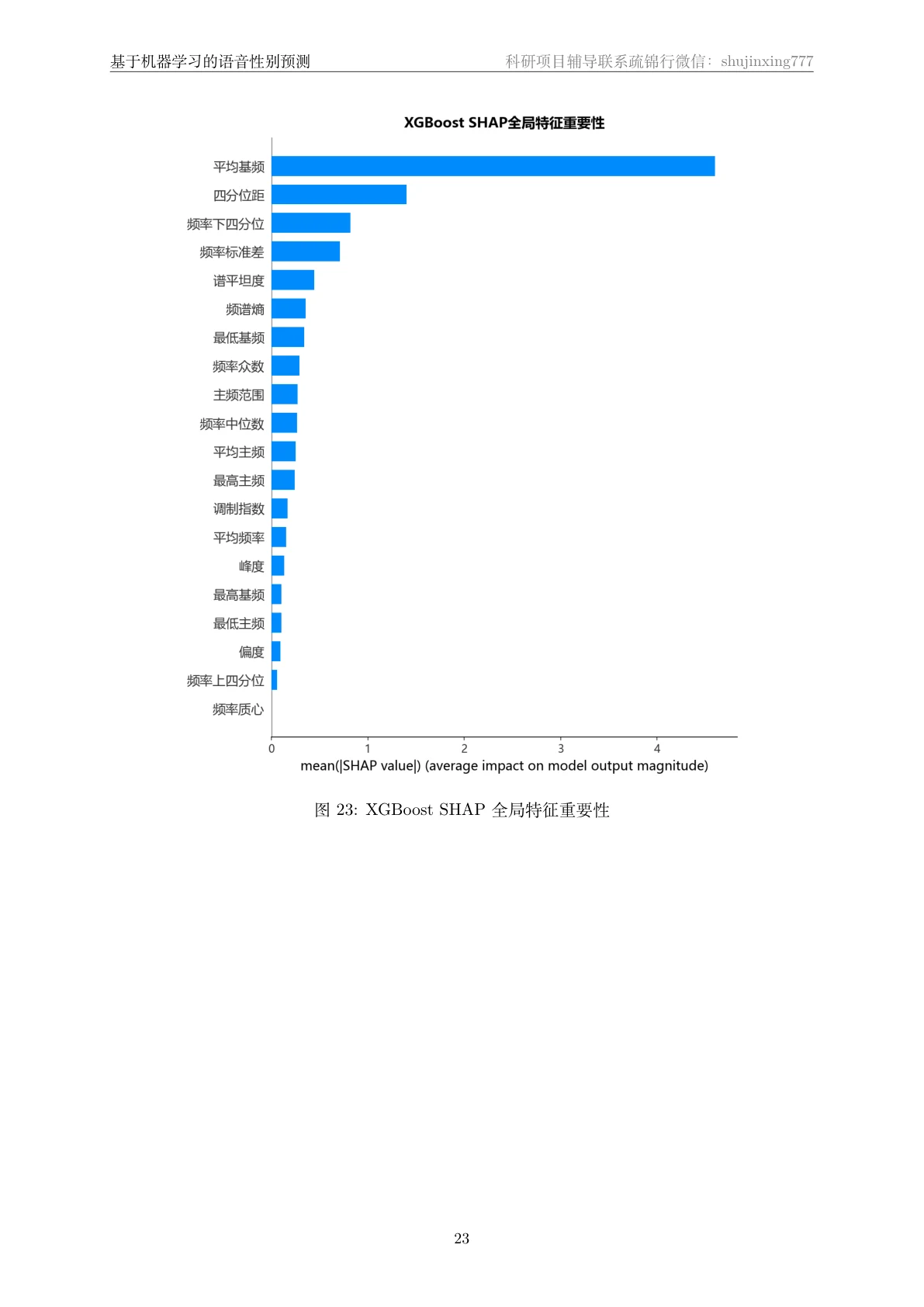
这个项目用的是 Kaggle Voice Gender 数据集——3168 条语音样本,每条已经抽好了 20 维声学特征,覆盖频率统计、频谱形状、基频、主频四大类(比如平均基频 meanfun、频谱熵、四分位距等)。项目在此之上搭了一条完整的分类流水线:先做标准化和分层划分,再对比五种机器学习模型并逐个调参,用熵权-TOPSIS 客观选出综合最优的模型,最后用 SHAP 找出哪些声学特征最能区分性别。
搞懂它,你能在面试里讲清楚什么
把下面几件事吃透,面试官顺着问下来你都能接得住。
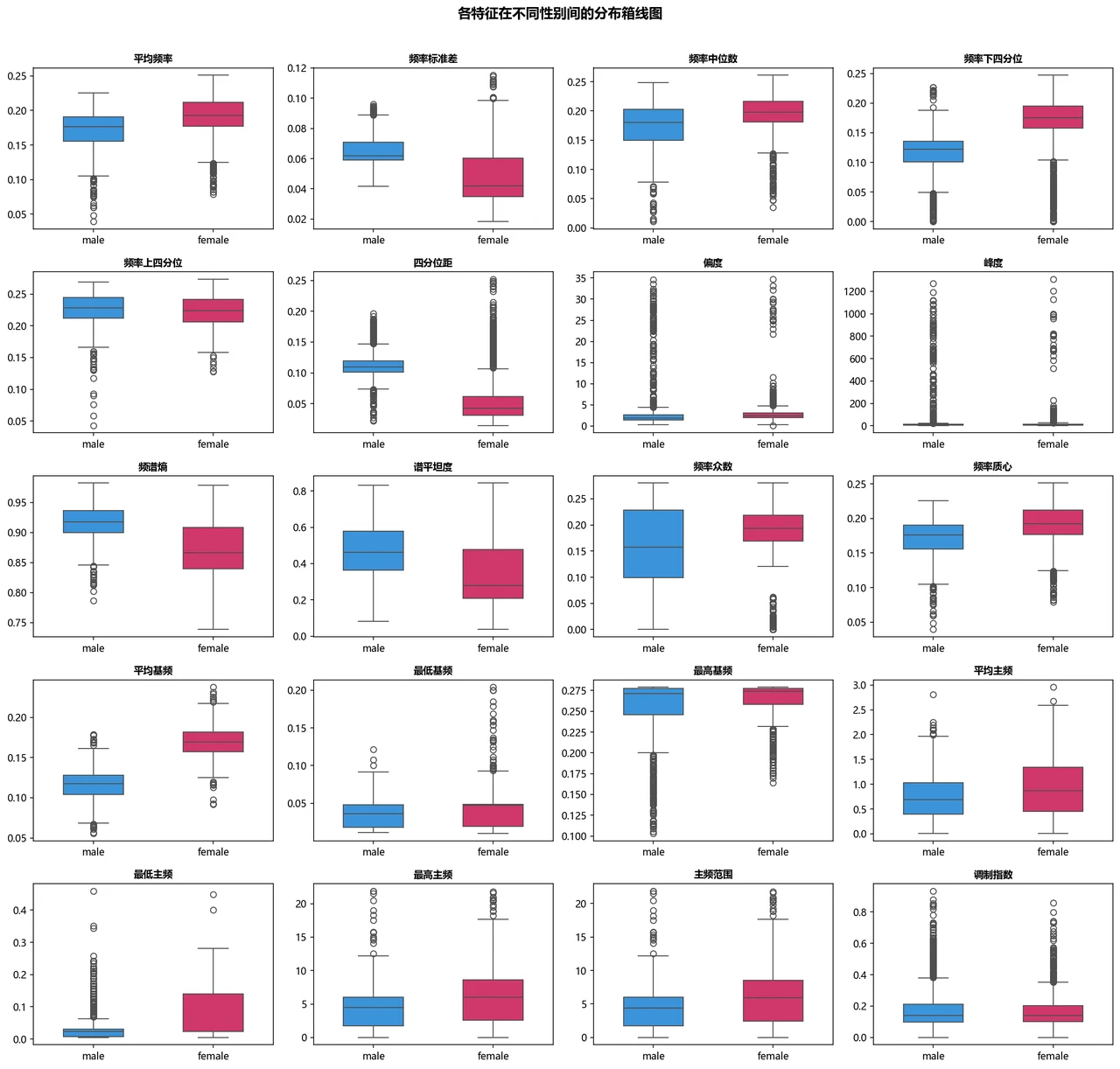
声音怎么变成 20 维特征,每一类特征在刻画什么。 这是地基。你要能讲清楚原始语音信号是怎么被拆成频率统计、频谱形状、基频、主频四组特征的,以及为什么平均基频这类特征天然带性别区分度——男声基频普遍偏低、女声偏高,这是声带生理差异决定的。把这条"信号 → 20 维特征向量 → 分类"的链路讲顺,整个项目的逻辑就立住了。
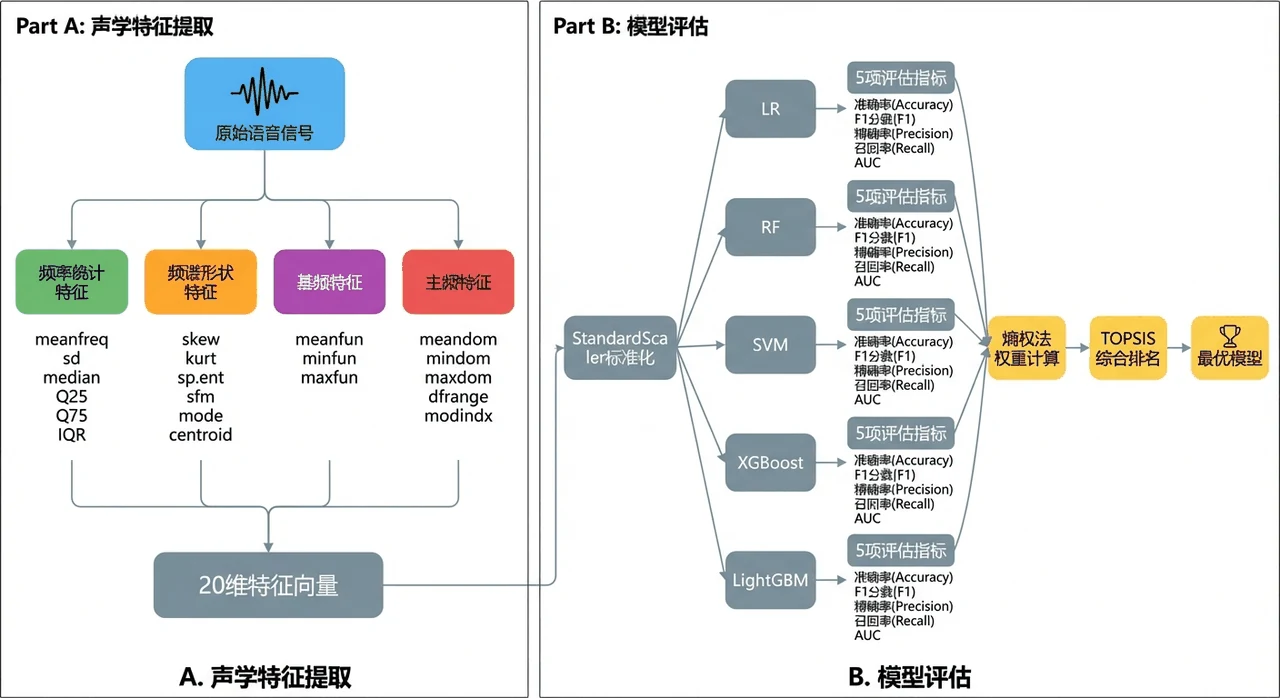
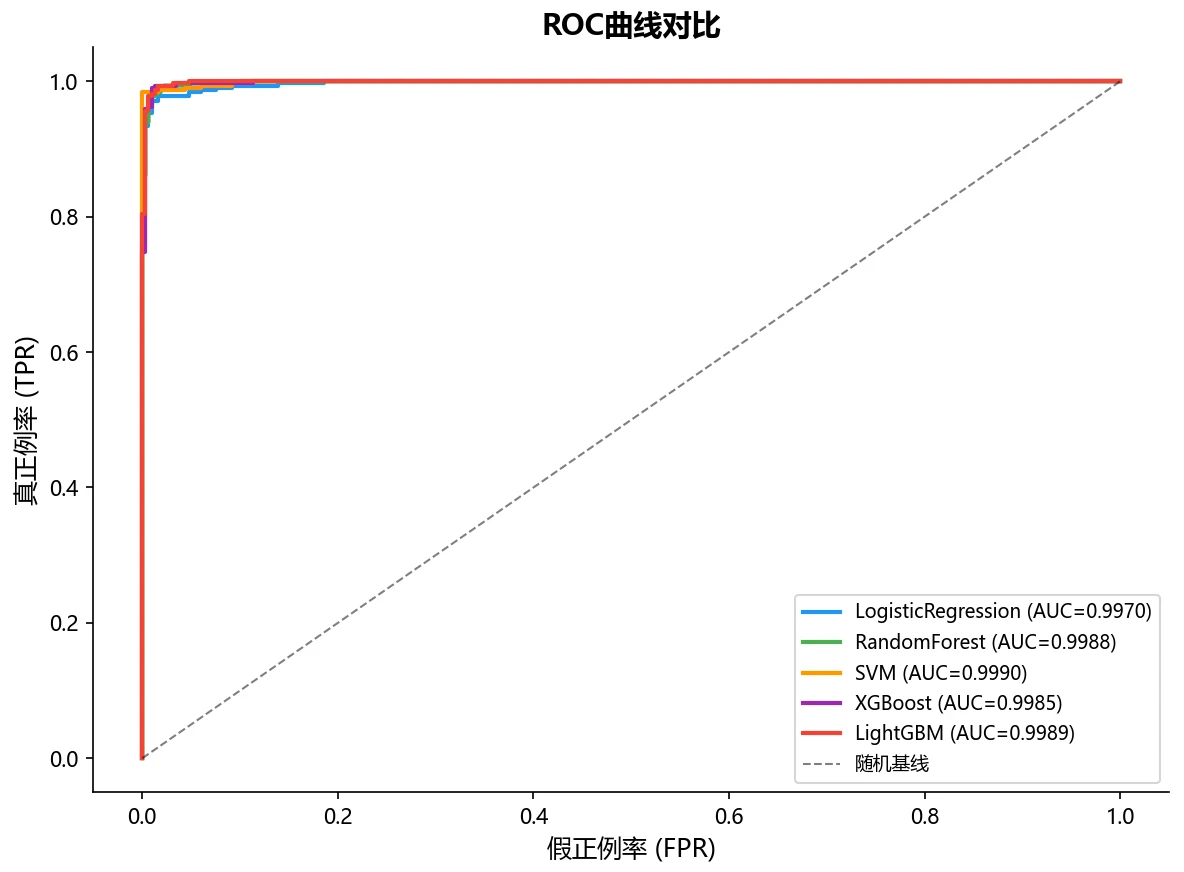
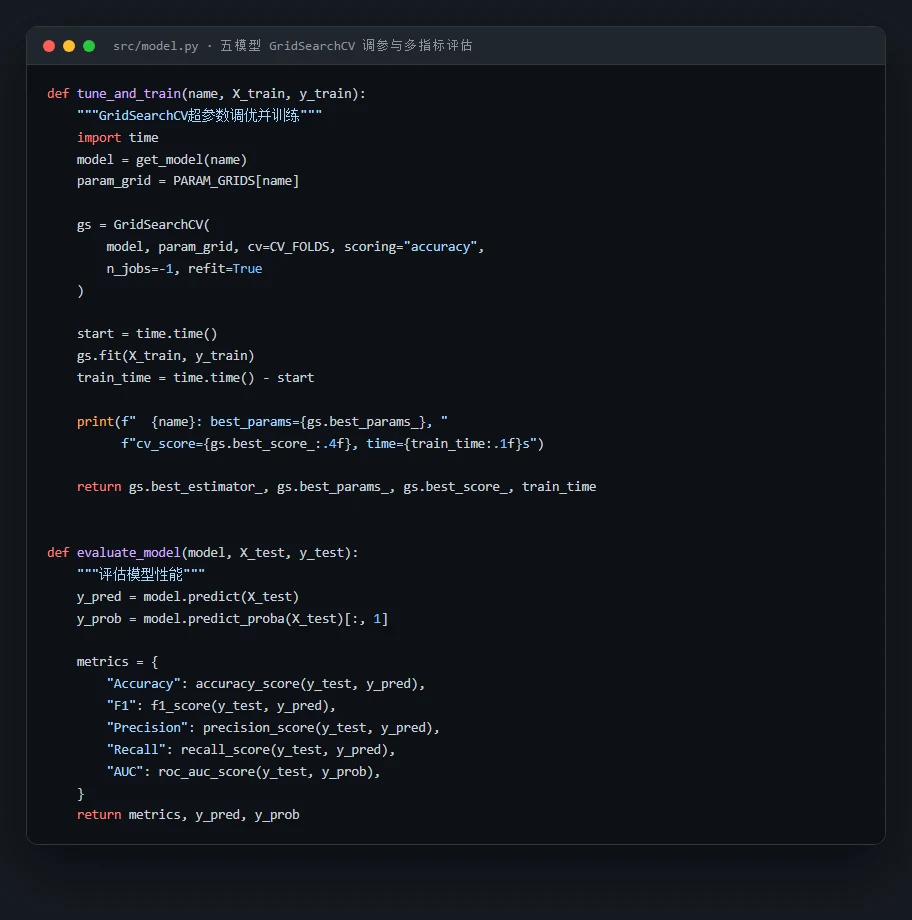
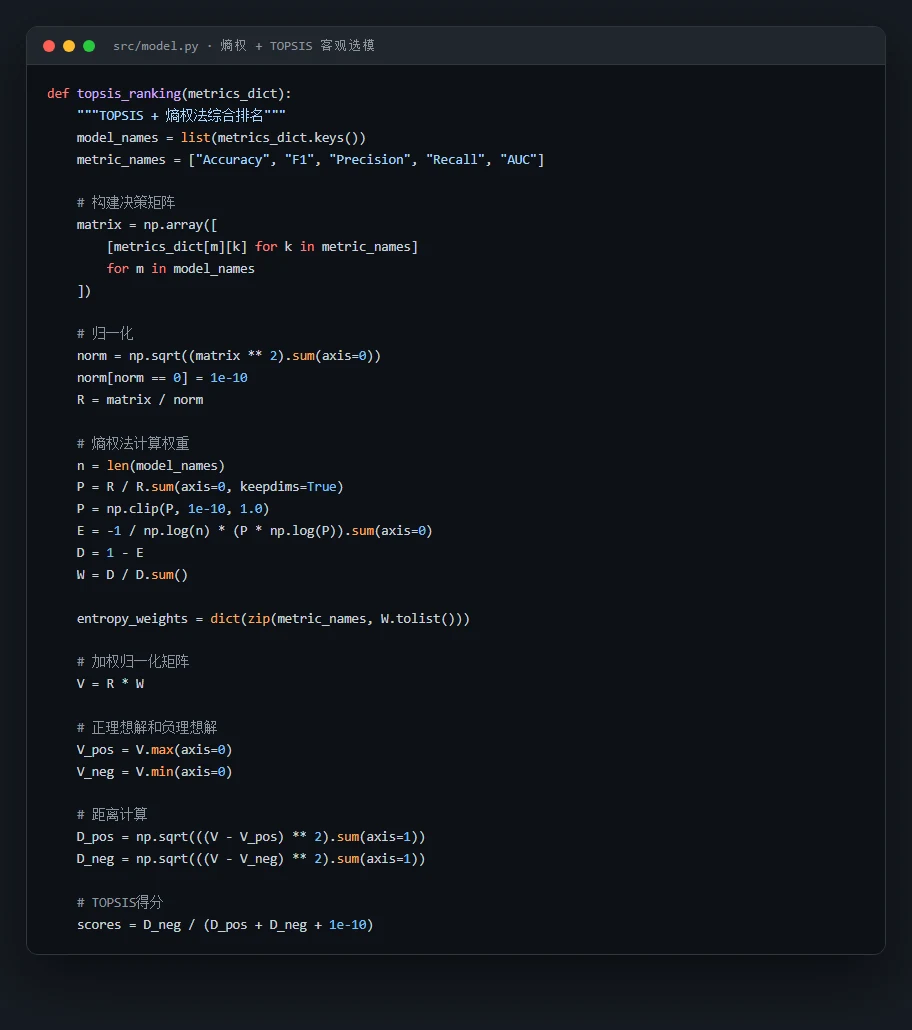
为什么对比五种模型,还要用熵权-TOPSIS 客观选模。 项目选了线性模型、核方法、Bagging 和 Boosting 三大范式共五种模型,各自 GridSearchCV 调参后,再用熵权-TOPSIS 把 Accuracy、F1、Precision、Recall、AUC 五个指标客观加权排名。你能借此讲清楚:当多个模型指标都很接近时,怎么避免"只看准确率"的主观偏好,给出一个站得住脚的选型结论。
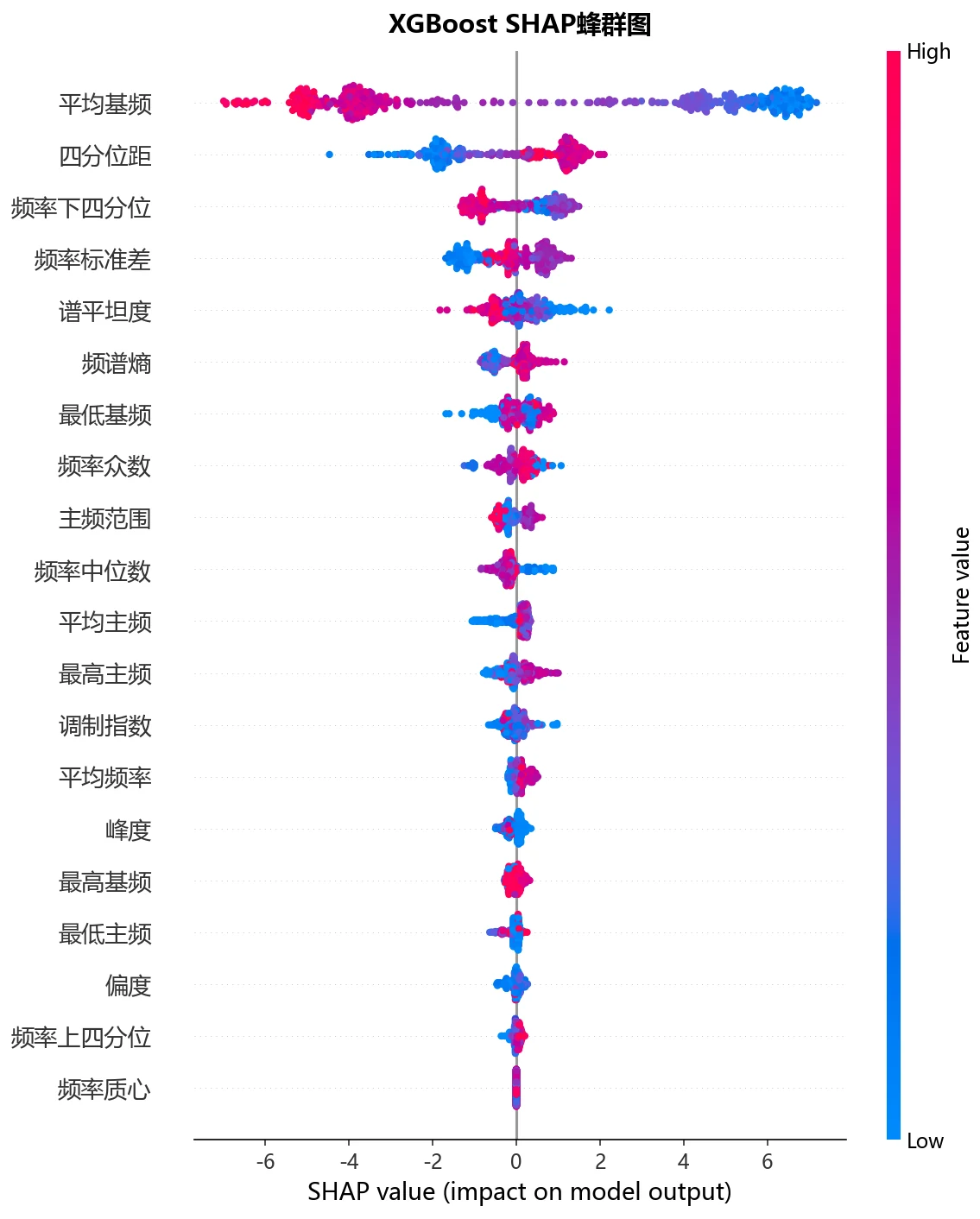
SHAP 怎么把"黑盒模型"讲成"看得懂的声学特征"。 SHAP 能排出哪些特征最推动"男/女"判断,让树模型的决策变透明,还能和前面的箱线图相互印证——模型最看重的特征,恰恰就是男女分布差异最大的那几个。
下面这组分析图也都给你做好了,可以直接放进答辩或面试 PPT:
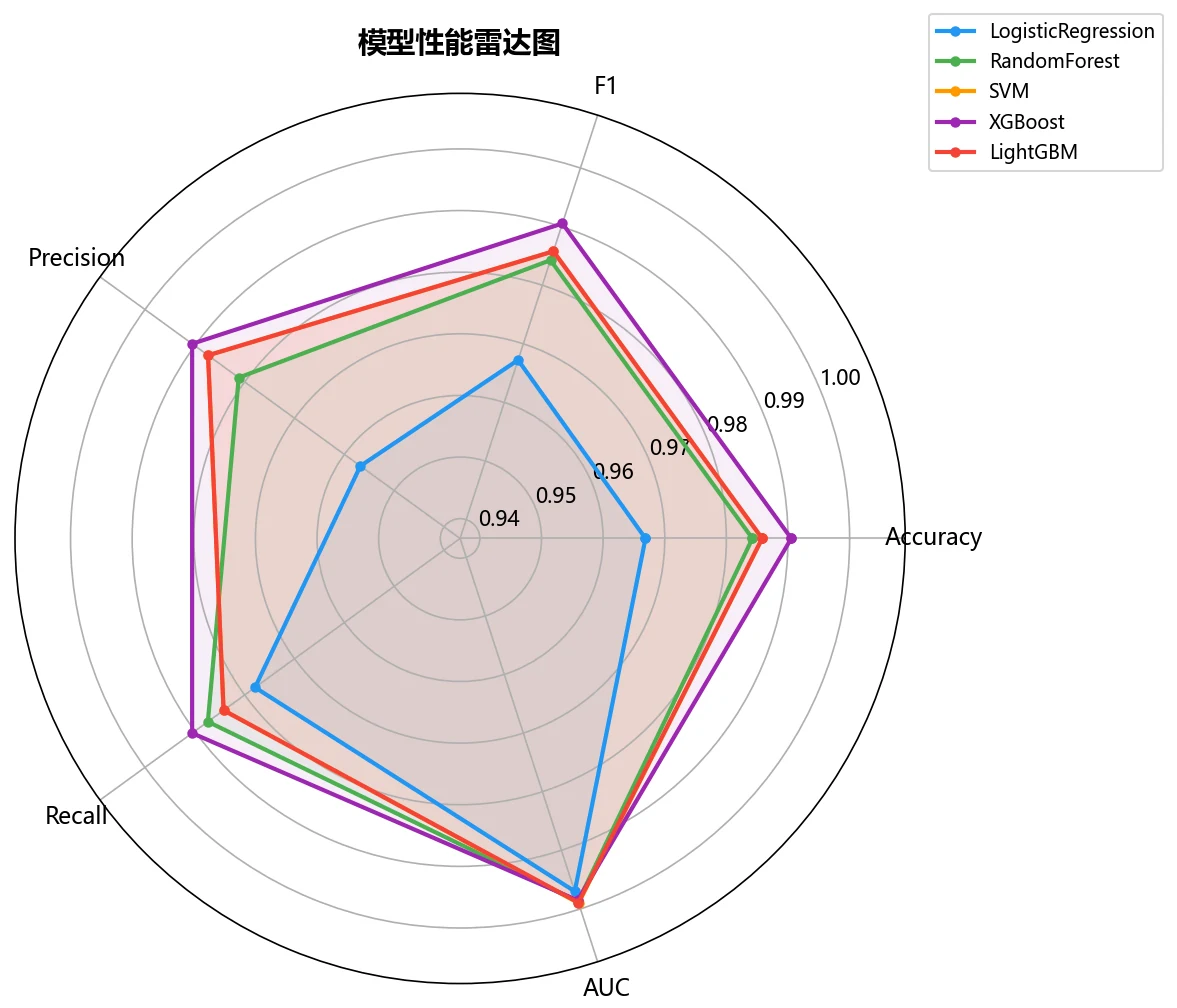
更关键的是,每张图怎么跑出来的、该怎么解读,技术文档里都讲清楚了——你能说明白每张图到底说明了什么。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
- 为什么平均基频(meanfun)会成为最关键的性别区分特征?
- 五个指标的权重用熵权法算,而不是自己拍,好处是什么?
- 阈值优化做了什么?为什么默认 0.5 不一定是最优判定阈值?
看到会愣一下?正常。配套的项目讲解资料把这个项目——从整体思路到每个流程细节、各种可能被追问的点——连参考答案都给你写好了。另外还有现成的简历描述,照着改就能写进简历;那套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。
配套资料:搞懂一个项目需要的,这里全都有
先看那份技术文档——从背景、声学特征、标准化与分层划分,一直讲到五模型对比、TOPSIS 选模与 SHAP 可解释性,图文并茂:


代码也给你了——关键部分都带着中文注释,帮你读懂"它到底是怎么实现的":
技术文档、项目讲解资料、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添个有分量的项目,还是在准备面试,这个题目都接得住。专业上,计算机、人工智能、软件工程、数据科学、信号处理与语音方向都很合适。语音性别预测把"特征工程 + 多模型对比 + 客观选模 + 可解释性"这条经典机器学习流水线串得很完整,真正搞懂、能讲出来,就是一个能写进简历、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「基于机器学习的语音性别预测」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。