基于机器学习的半导体产量预测
半导体制造良率预测:从 590 维传感器特征出发,做缺失/方差/相关过滤 + ANOVA 选维 + SMOTE,五模型对比 + 熵权-TOPSIS 客观选模 + SHAP 溯源——一条完整的高维工业数据建模流水线。
项目亮点
- 来源: [UCI SECOM Dataset](https://archive.ics.uci.edu/ml/datasets/SECOM)
- 样本数: 1,567 条记录
- 特征数: 590 个传感器特征
- 目标变量: 产品质量(-1=通过, 1=失败)
数据与任务
| 样本量 | UCI SECOM · 1567×590 维 |
|---|---|
| 核心方法 | 特征工程 + 5 模型 + TOPSIS |
| 技术栈 | scikit-learn · imblearn · SHAP |
如果你想找一个能写进简历、面试又能讲清楚,方向还挺有分量的 AI 项目,这个「用机器学习预测半导体良率」会很合适。
它落在工业 4.0 / 智能制造的真实场景上:一条芯片产线上几百个传感器实时采集数据,要在产品下线前就判断它会通过还是失败。配套都给你备齐了,帮你真正搞懂它、在面试和答辩里讲明白:带中文注释、能读懂的代码,一份从背景一直讲到 SHAP 溯源的技术文档,里面连面试问题带参考答案、现成的简历描述都写好了,还有一整套能直接做 PPT 的配图。
先说清楚,它到底在做什么
半导体制造里,一片晶圆要经过几百道工序,产线上布满传感器。等到测出"这片是次品"往往已经浪费了大量工时和材料,所以业界很想提前预测良率、把质量问题拦在前面。
难点是这份数据特别"硬":UCI SECOM 数据集有 1567 条记录、590 维传感器特征,但只有约 6.6% 是失败样本(通过∶失败 ≈ 14∶1),还夹着大量缺失值。高维、稀疏、极端不平衡——直接喂给模型基本学不到东西。
这个项目就是冲着这三个难点去的:先用一套特征工程流水线把 590 维压到 53 维(高缺失列删除 → 中位数填充 → 低方差过滤 → 高相关去除 → ANOVA F 检验选 Top50 → 再加传感器均值/标准差/极差三个衍生特征),再用 SMOTE 在训练集上把少数类补齐,然后对比五种模型、用熵权-TOPSIS 客观选出最优解,最后用 SHAP 反查到底是哪些传感器在左右良率。
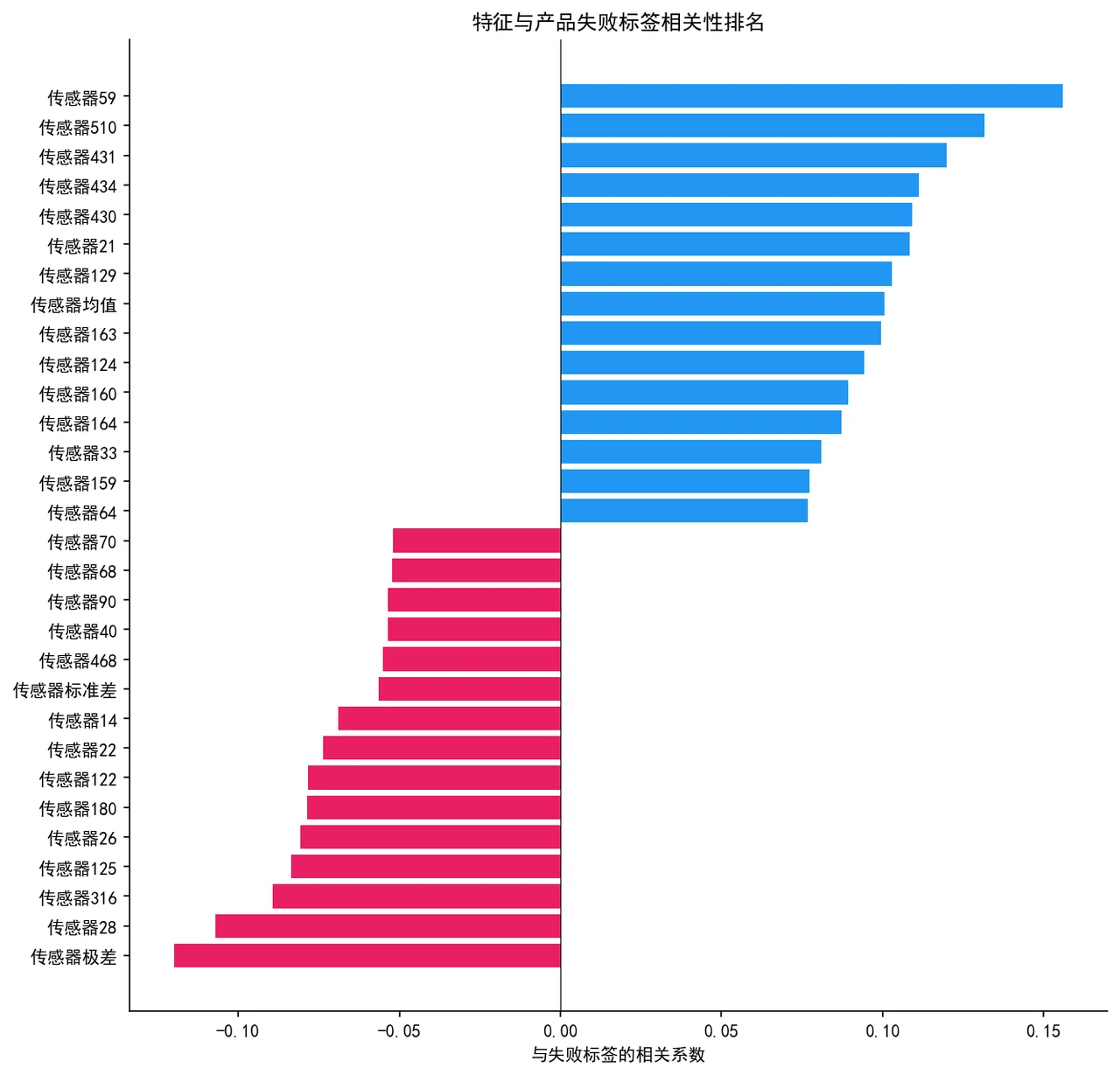
搞懂它,你能在面试里讲清楚什么
把下面几件事吃透,面试官顺着问下来你都能接得住。
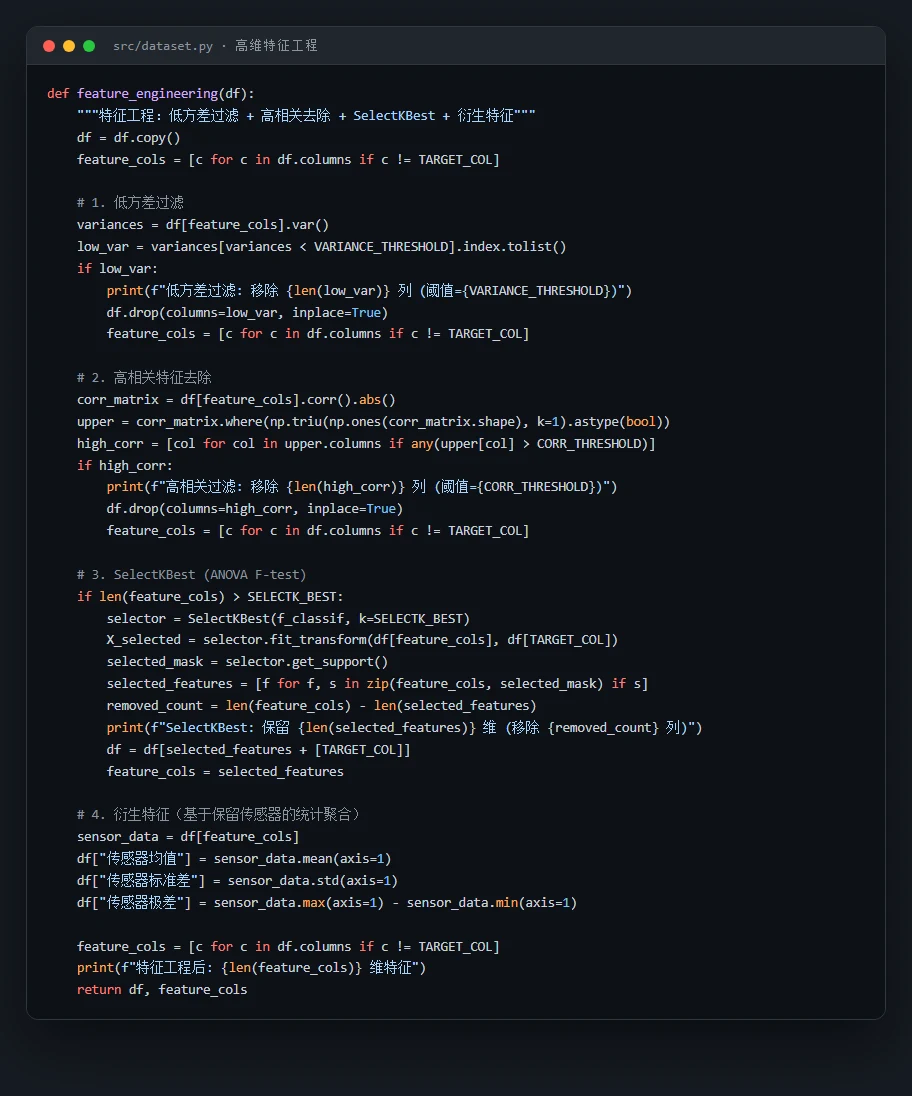
590 维怎么压到 53 维,这套高维特征处理是地基。 这是全项目最有讲头的部分。你要能讲清楚这条流水线每一步在干什么、为什么这个顺序:先删高缺失列、再删低方差和高相关的冗余列,最后用 ANOVA F 检验做有监督筛选留下最相关的 50 维,外加三个统计衍生特征。讲明白它,就等于讲明白了"高维工业数据该怎么收拾"。
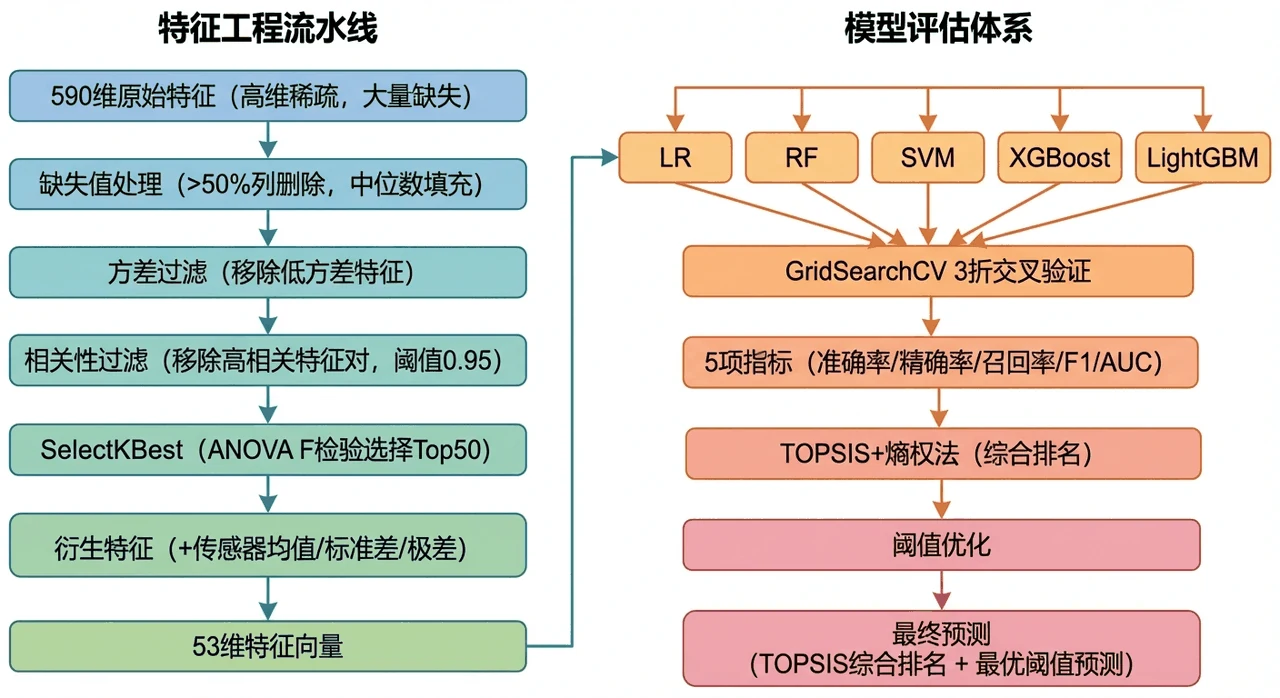
极端不平衡下,为什么不能只看准确率。 14∶1 的不平衡意味着"全猜通过"也有 93% 准确率,但那对找次品毫无用处。你要能讲清楚为什么要看召回、F1、AUC,为什么要在训练集上做 SMOTE,以及阈值优化(把判定阈值从 0.5 调到 0.62)是怎么进一步把 F1 提上去的。
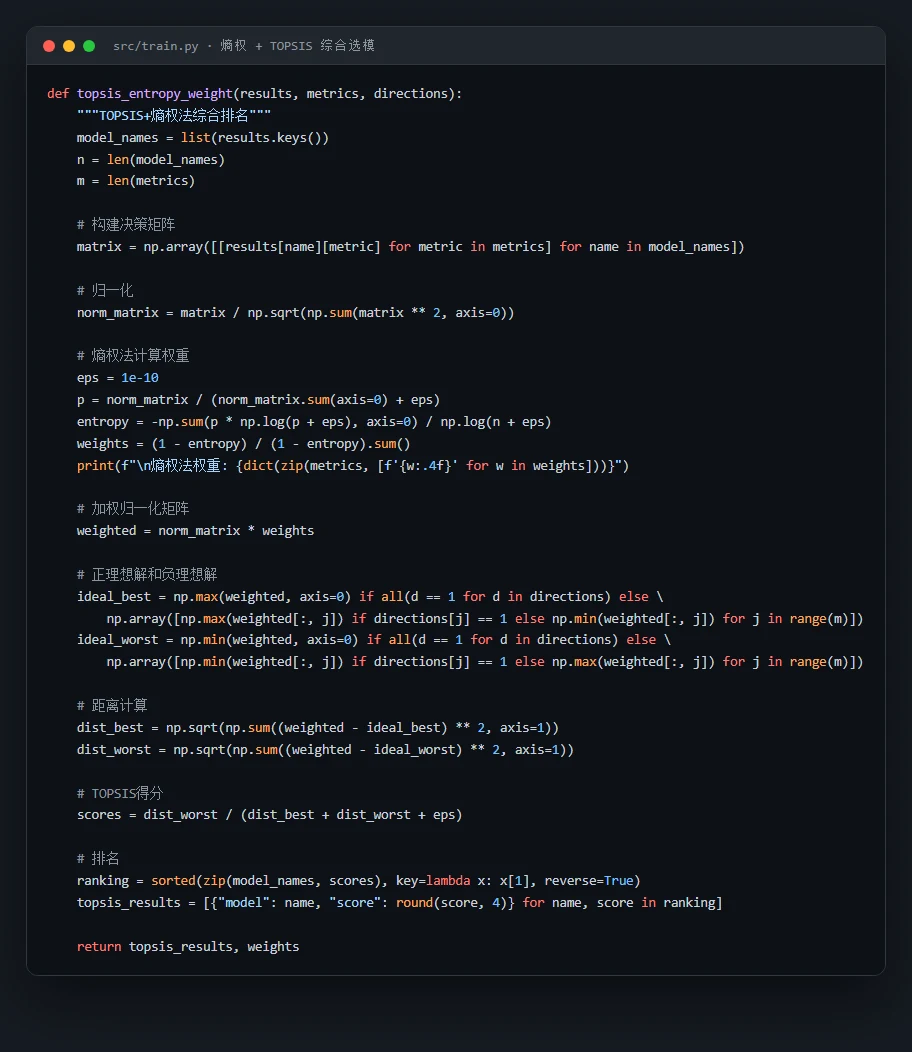
熵权-TOPSIS 怎么把"选哪个模型"变成客观决策。 五个模型在五个指标上各有高低,谁也不全赢。项目用熵权法自动给指标定权重(让区分度大的指标权重更高),再用 TOPSIS 算出每个模型到"理想解"的距离做综合排名——把"凭感觉挑模型"换成一个可解释、可复述的决策过程。
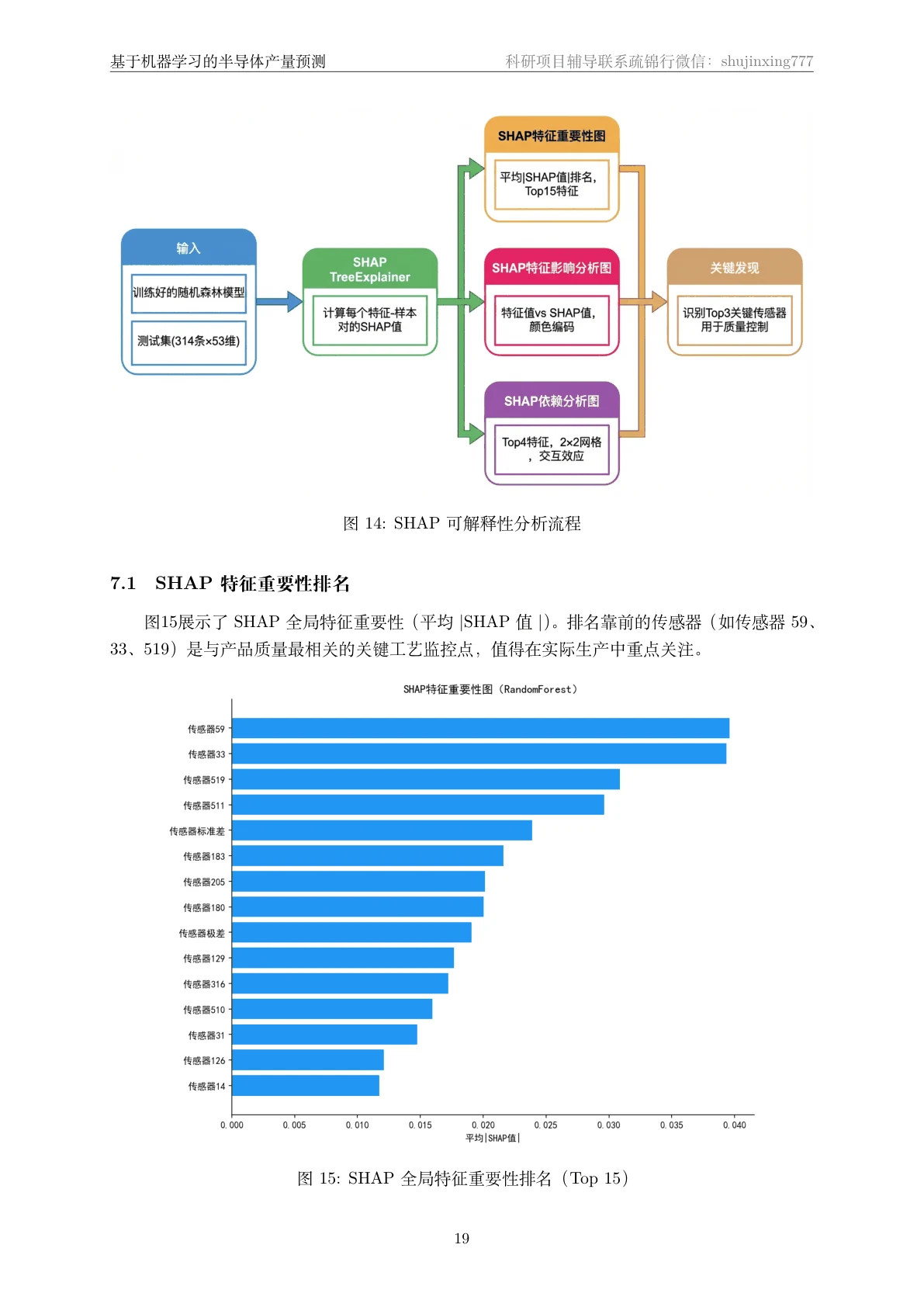
SHAP 怎么把黑盒模型讲成"看得懂的传感器"。 SHAP 能排出哪些传感器最推动"失败"判断、每个样本上各特征往哪个方向使劲,让模型从黑盒变透明,也对应到产线上"该重点盯哪几个工位"。
下面这组分析图也都给你做好了,可以直接放进答辩或面试 PPT:
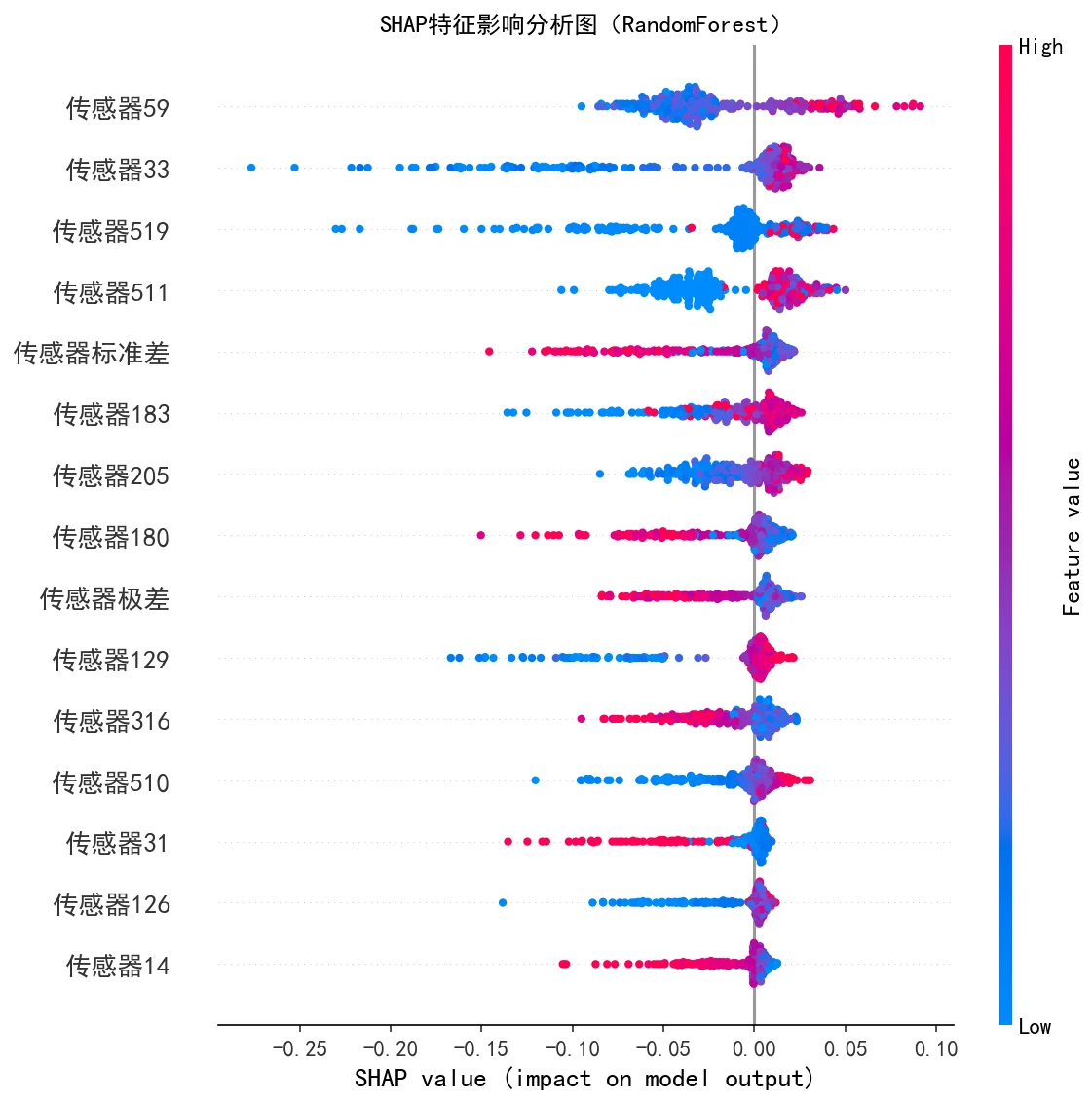
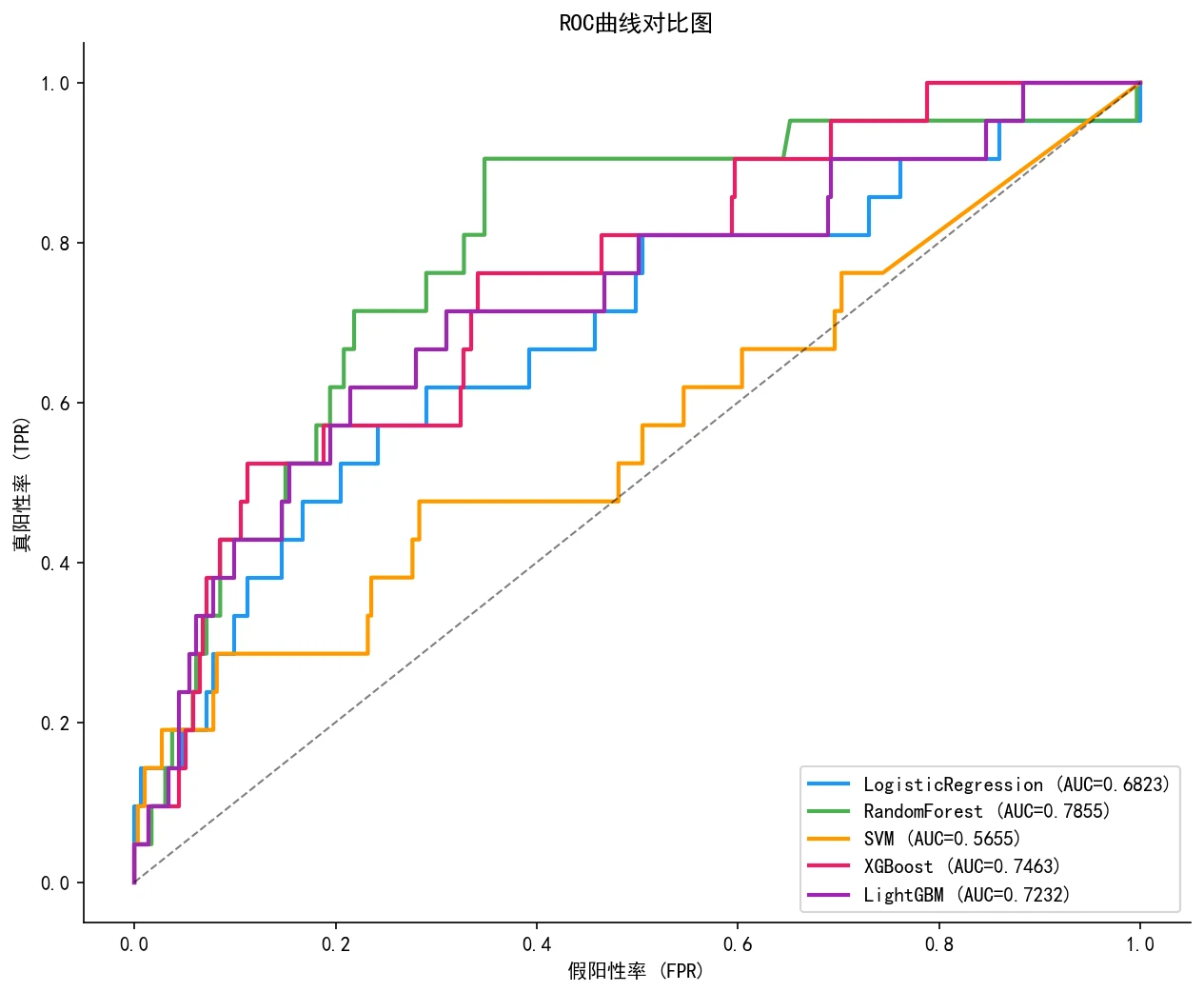
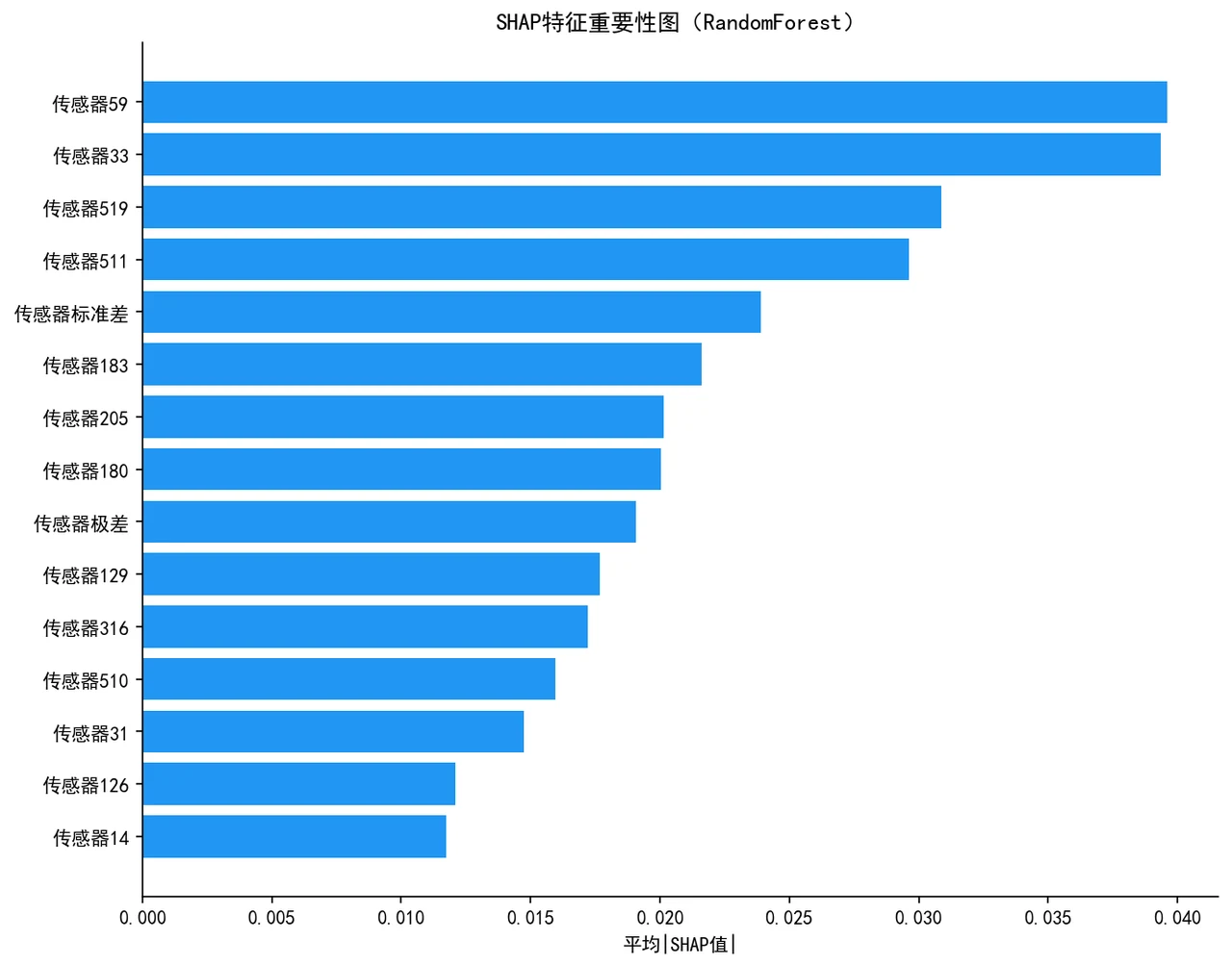
更关键的是,每张图怎么跑出来的、该怎么解读,技术文档里都讲清楚了——你不是只会贴图,而是能说明白每张图到底说明了什么。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
- 590 维降到 53 维,每一步删掉的是什么样的特征?顺序能不能换?
- 失败率只有 6.6%,为什么 SMOTE 只在训练集做、不在测试集做?
- 熵权法的权重是怎么算出来的?为什么召回的权重最高?
看到会愣一下?正常。配套的项目讲解资料把这个项目——从整体思路到每个流程细节、各种可能被追问的点——连参考答案都给你写好了。里面还有现成的简历描述,照着改就能写进简历;那套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。
配套资料:搞懂一个项目需要的,这里全都有
先看那份技术文档——从工业背景、数据探索,到特征工程、五模型方法、TOPSIS 选优,一直讲到 SHAP 可解释性,图文并茂:

代码也给你了——关键部分都带着中文注释,帮你读懂"它到底是怎么实现的":
技术文档、面试问答、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添个有分量的项目,还是在准备面试,这个题目都接得住。它把"高维特征处理 + 不平衡分类 + 客观选模 + 可解释性"这条工业数据建模主线串得很完整,工业味道也足。专业上,计算机、人工智能、数据科学、电气与自动化、工业工程、智能制造方向都很合适。把这条流水线真正搞懂、能讲出来,就是一个能写进简历、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「基于机器学习的半导体产量预测」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。