基于机器学习的 A 股上市公司财务困境(ST/*ST)预测
用 CSMAR 真实 A 股财务数据预测上市公司被 ST/*ST:以第 T 年年报的 38 个财务比率,提前 1~2 年预警财务困境——SMOTE 解极端不平衡(困境仅 3.16%)+ 五模型对比 + 熵权-TOPSIS 客观选模 + 阈值优化 + SHAP 找预警因子,一条本土化的金融风控建模流水线。
项目亮点
- 真实 CSMAR 数据 + 规范 ST 标签:业内公认的中国财务困境研究范式,区别于合成数据项目。
- 时序无泄露建模:T 年报特征 → 预测未来 ST,剔除已困境样本,杜绝前视偏差。
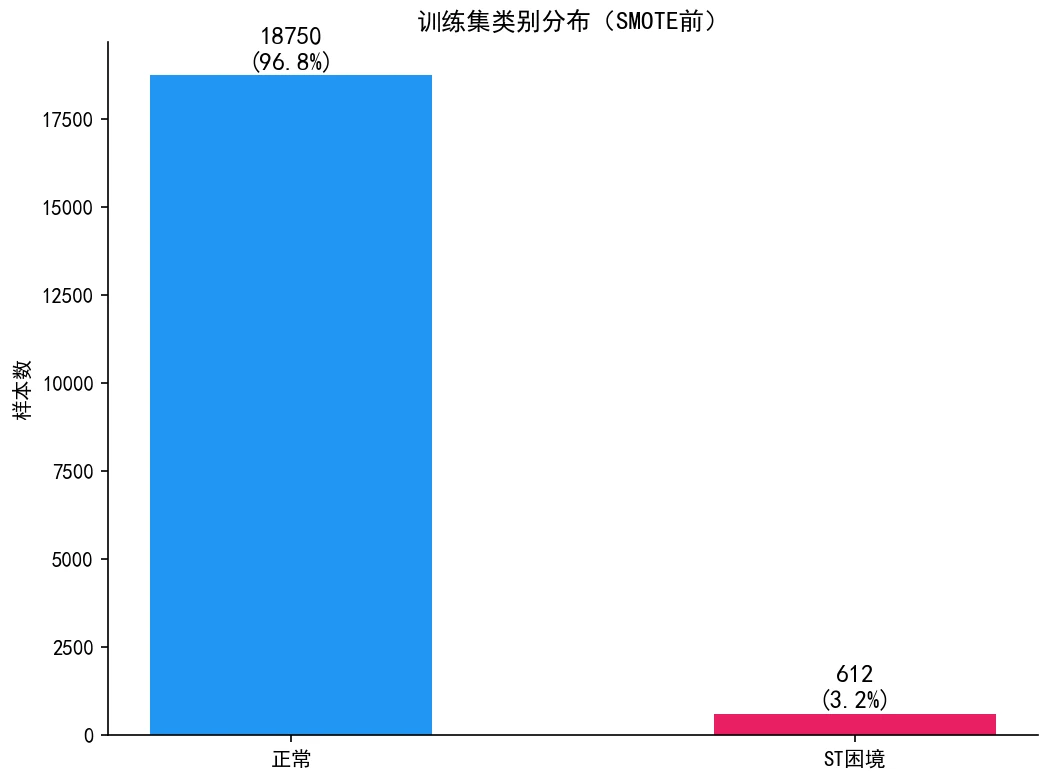
- 类别不平衡处理:适度 SMOTE 过采样 + 阈值优化,避免准确率假象,关注 AUC 与困境类召回。
- 多模型对比 + 客观赋权:5 模型 + TOPSIS 熵权法综合评价,结论自洽(树模型 > 线性基线)。
数据与任务
| 样本量 | CSMAR · 24203 个公司-年样本 |
|---|---|
| 核心方法 | SMOTE + 五模型 + 熵权-TOPSIS + SHAP |
| 技术栈 | scikit-learn · XGBoost · LightGBM · SHAP |
如果你想找一个落在真实 A 股市场、又能把机器学习全流程讲透的项目,这个「上市公司财务困境预测」很合适。
它的题目本身就有分量——拿真实财务报表预测哪些 A 股公司会被 ST/ST,是信用评级、债券风控、量化避雷里都在做的事。配套也给你备齐了,帮你真正搞懂它、在面试和答辩里讲明白*:带中文注释、能读懂的代码,一份从数据构建到 SHAP 预警因子层层讲透的技术说明文档(里面连简历描述和会被追问的面试问题都连答案写好了),还有一整套能直接做 PPT 的配图。
先说清楚,它到底在做什么
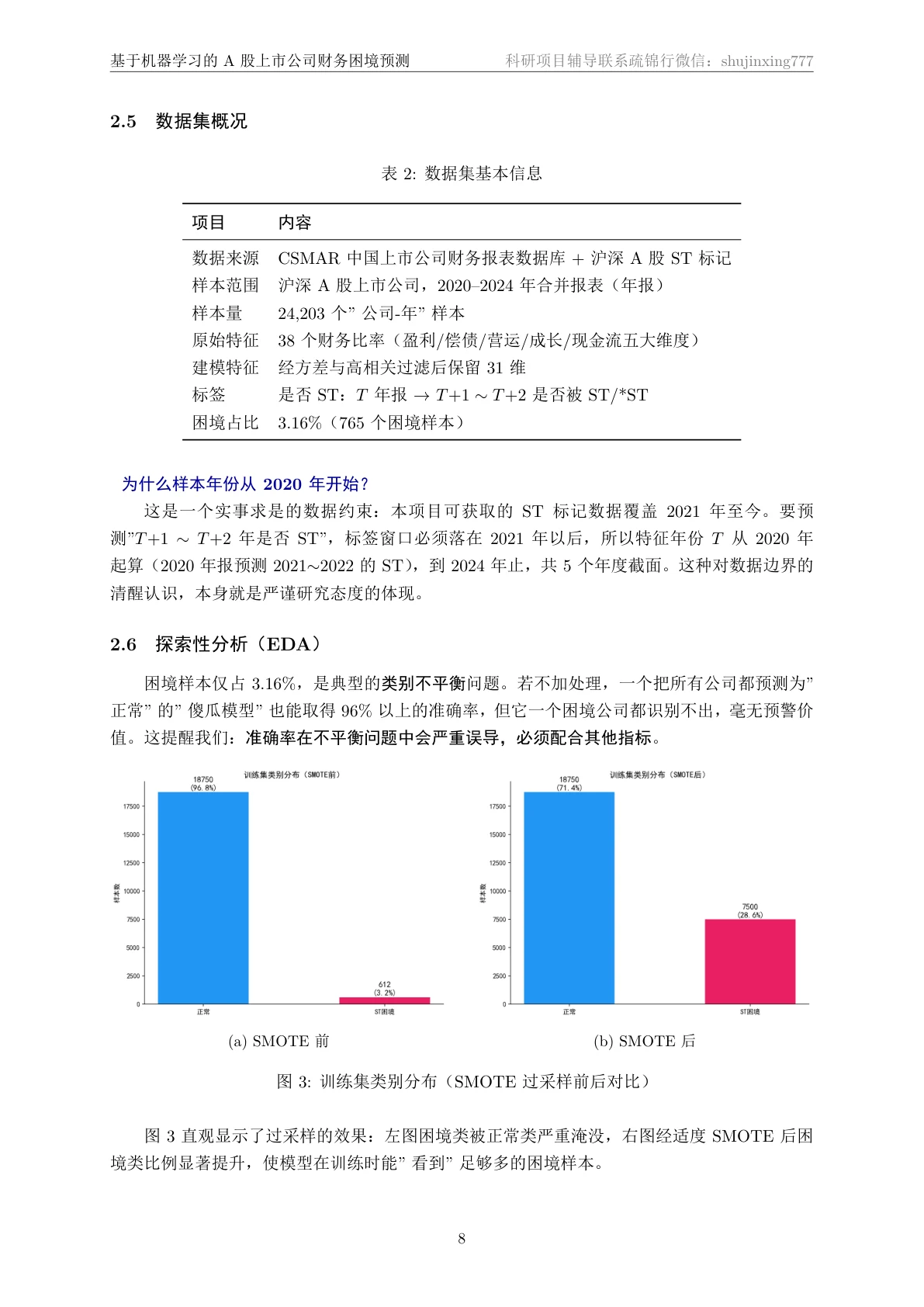
财务困境预测的难点有两层。第一层是数据极度不平衡:两万多个"公司-年"样本里,真正会被 ST 的只占 3.16%。一个无脑全猜"不会困境"的模型,准确率就能到 96%——可它一家要出事的公司都预警不出来,在风控里毫无价值。第二层更隐蔽,是时序泄露:你要用今天能看到的财报,去预测未来才会发生的 ST 事件,绝不能偷看未来。
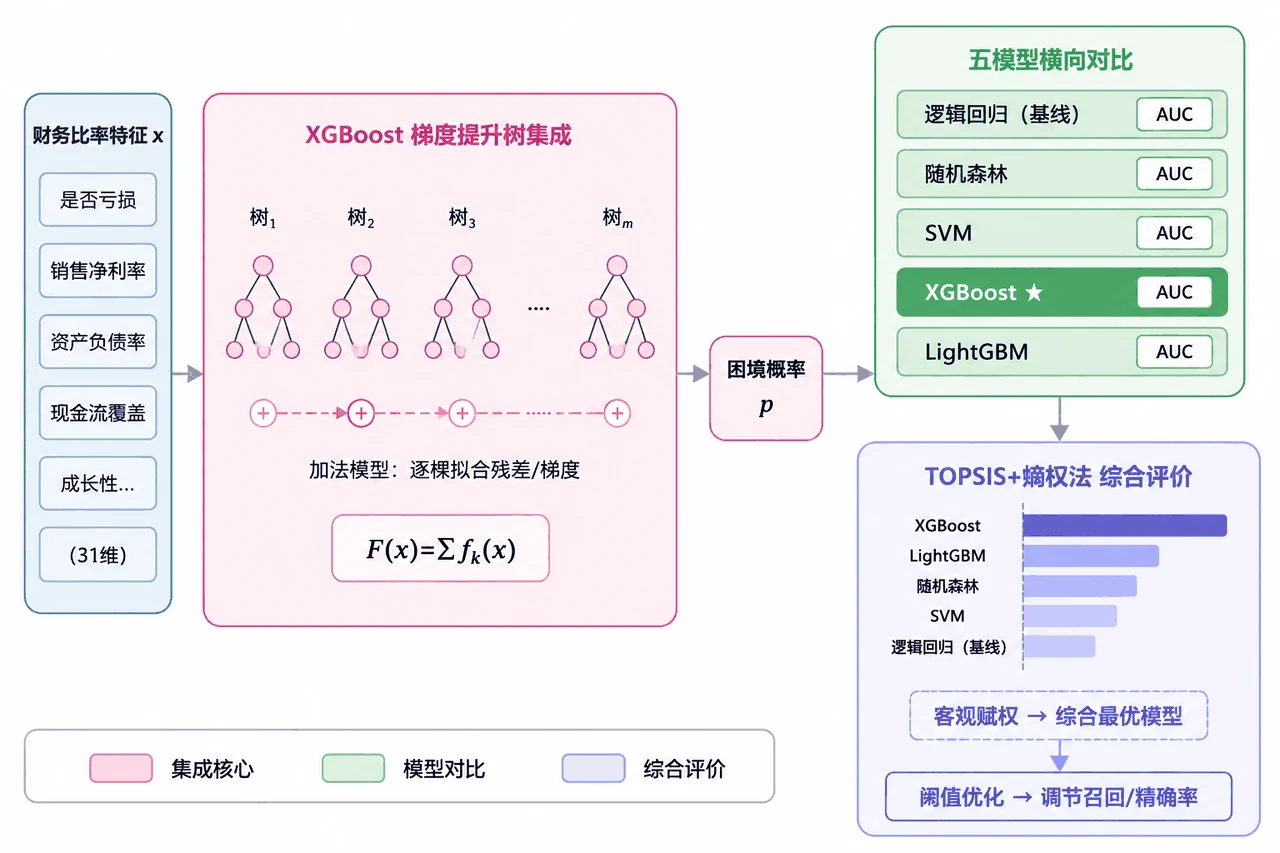
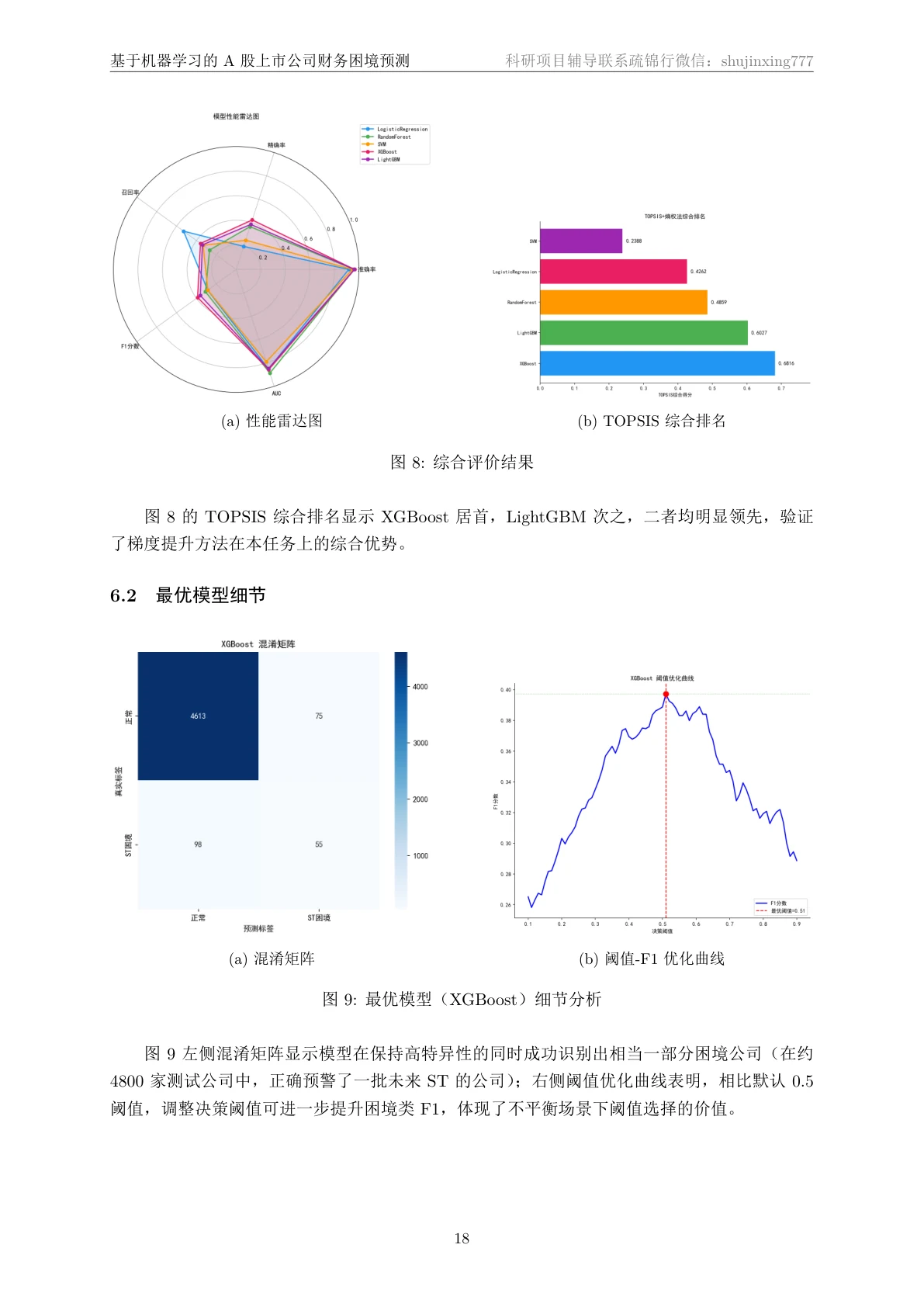
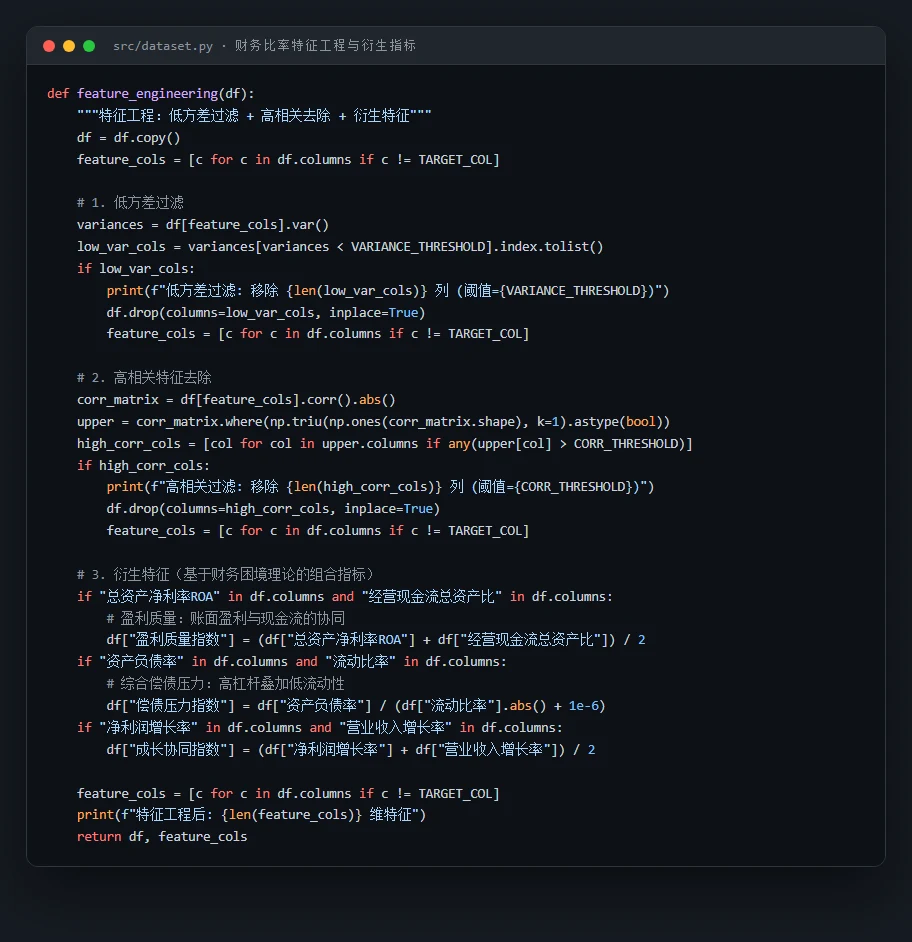
这个项目从 CSMAR 中国上市公司财务报表数据库出发,用资产负债表、利润表、现金流量表算出 38 个财务比率(覆盖盈利、偿债、营运、成长、现金流五大维度),并严格用第 T 年年报的特征去预测 T+1~T+2 年是否被 ST、还剔除了 T 年已 ST 的公司,把任务锁定在"健康→困境"的转变预测上,杜绝前视偏差。再经方差与相关过滤把特征压到 31 维、加上几个基于财务困境理论的衍生指标,用 SMOTE 只对训练集做适度过采样;对比逻辑回归、随机森林、SVM、XGBoost、LightGBM 五种模型并逐一调参,用熵权-TOPSIS 客观选出最优模型(XGBoost),再做阈值优化,最后用 SHAP 找出哪些财务指标最能预警 ST。
搞懂它,你能在面试里讲清楚什么
把下面几件事吃透,面试官顺着风控这条线问下来你都能接得住。
标签怎么定,时序泄露怎么躲。 这是这个项目最见功力、也最能体现科研严谨度的地方。你要能讲清楚为什么只能用 T 年及以前的财报,为什么要剔除 T 年已经 ST 的公司,以及如果不小心用了未来信息会怎么把指标"刷虚高"。这套"信息截止线"的思路,正是真实金融建模和课堂玩具数据的本质区别。
极端不平衡怎么处理,为什么准确率会骗人。 你要能讲清楚为什么 96% 的准确率毫无意义,为什么这里要盯着 AUC 和困境类的召回、F1,以及 SMOTE 为什么只能在训练集上做、绝不能碰测试集——否则就是数据泄露。项目里还特意做了"适度过采样"而不是补到全平衡,避免合成样本泛滥把精确率打崩,这个取舍也能讲。
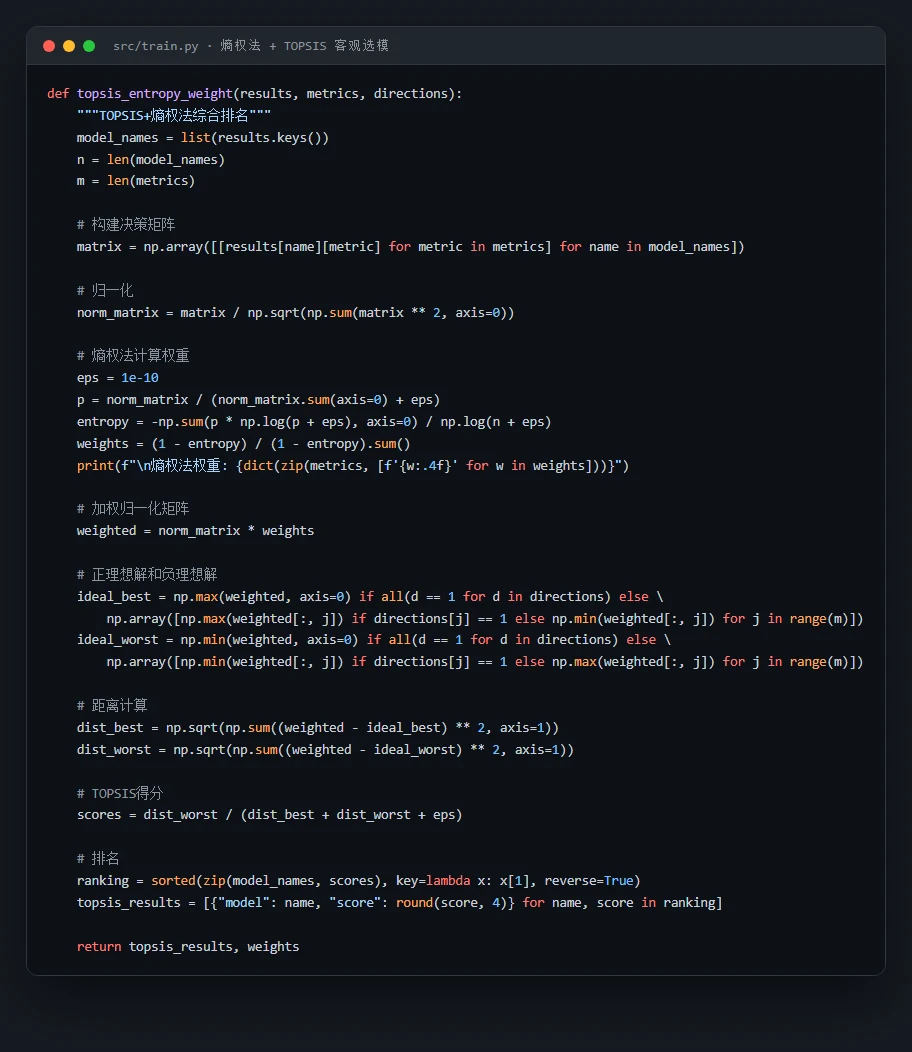
为什么五个模型还要客观选模。 "哪个模型最好"不该拍脑袋。这里用熵权法给准确率、精确率、召回率、F1、AUC 五个指标自动定权,再用 TOPSIS 综合排名,把选模做成一套客观、可追溯的流程。配上这张架构图,你能把"特征工程 → 五模型 → 熵权-TOPSIS 选模 → 阈值优化"整条链路一口气讲明白。
SHAP 怎么把模型讲成"看得懂的预警因子"。 风控最怕黑盒——模型说一家公司要出事,你得说出凭什么。SHAP 能排出哪些财务指标最推动困境判断,还原出"是否亏损、销售净利率、成长性、偿债压力"这些核心预警信号,而它们恰好和 ST 制度(连续亏损触发)、财务困境理论高度吻合,让模型的判断站得住脚、讲得清楚。
下面这组分析图也都给你做好了,可以直接放进答辩或面试 PPT:
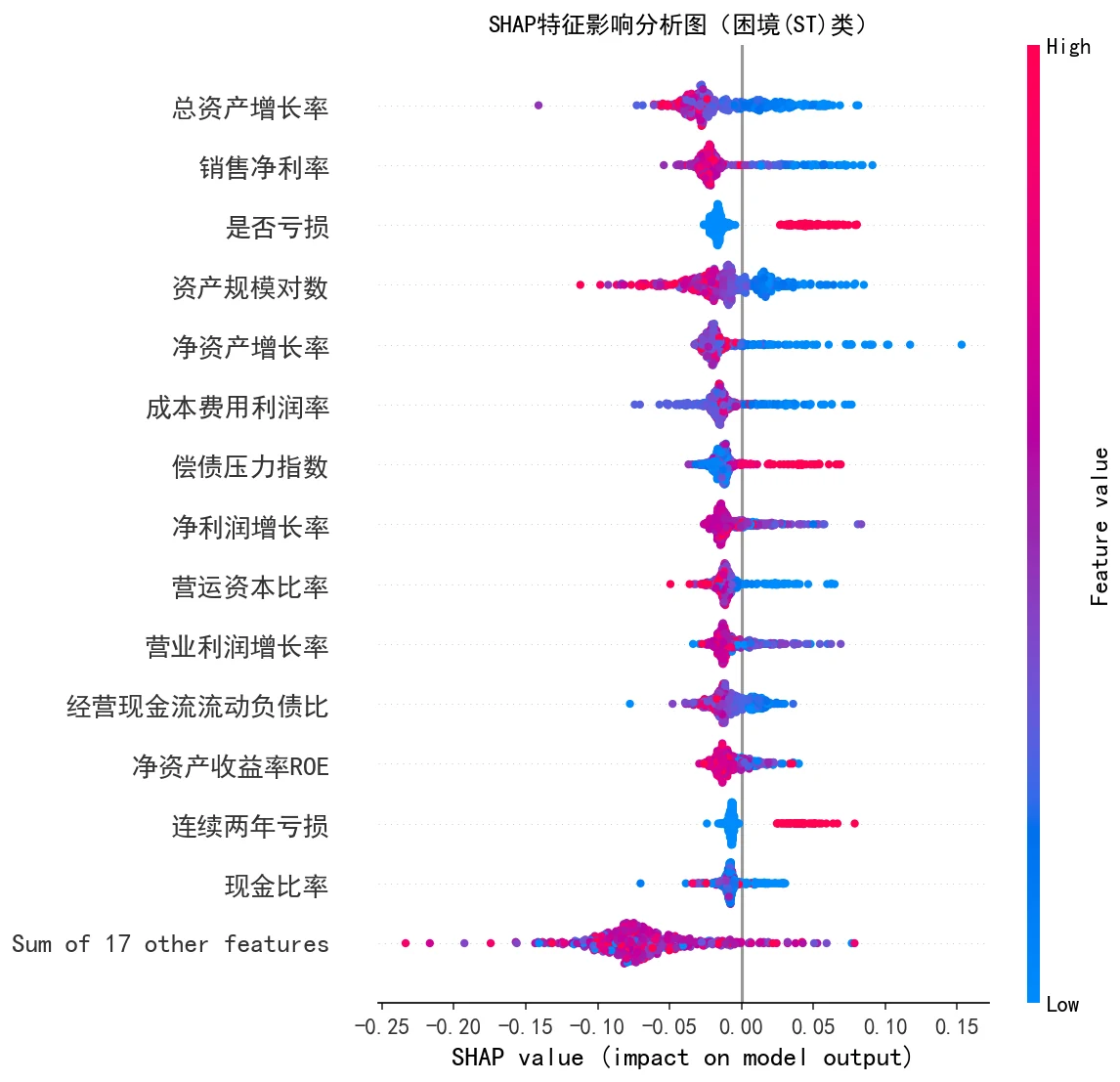
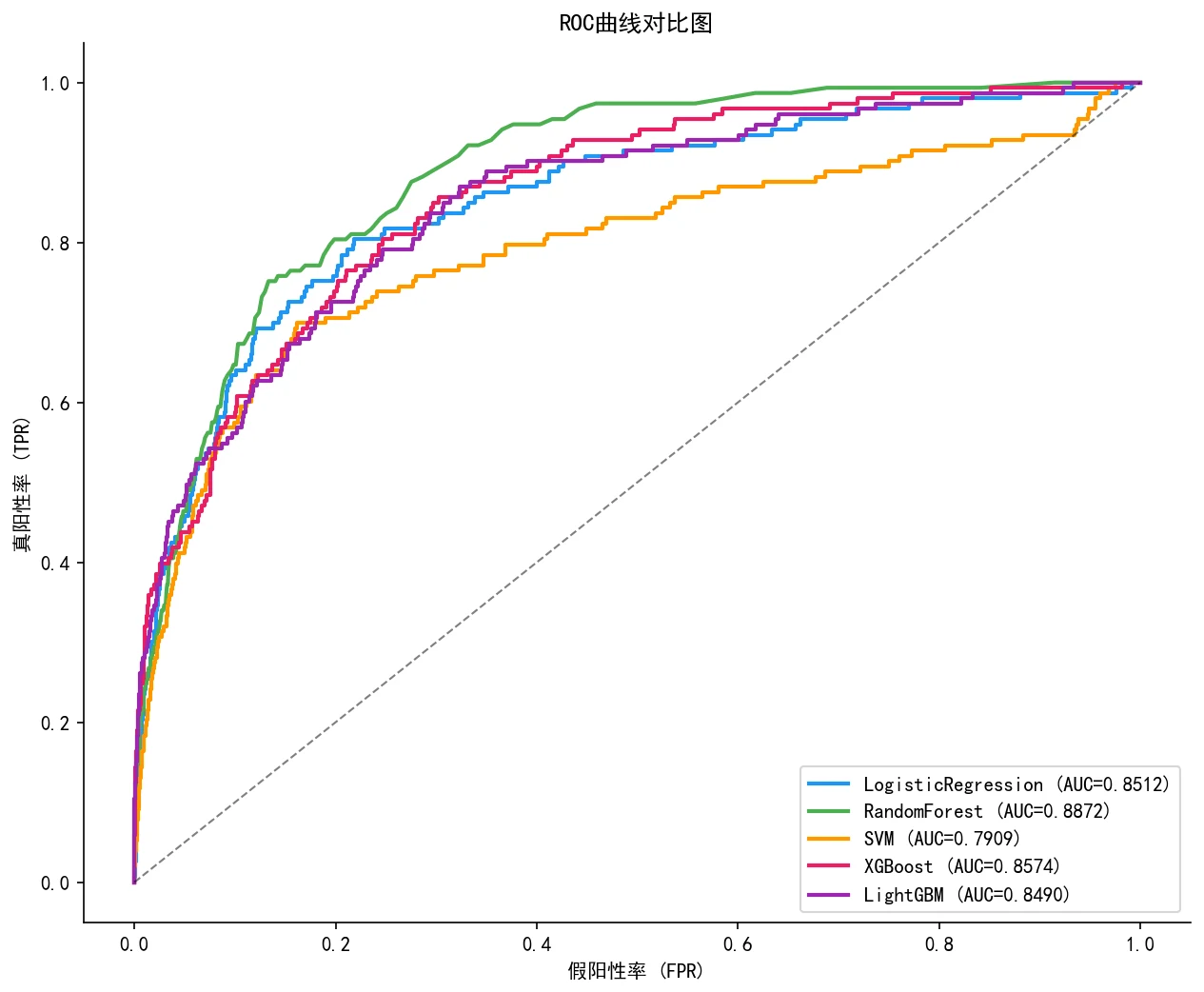
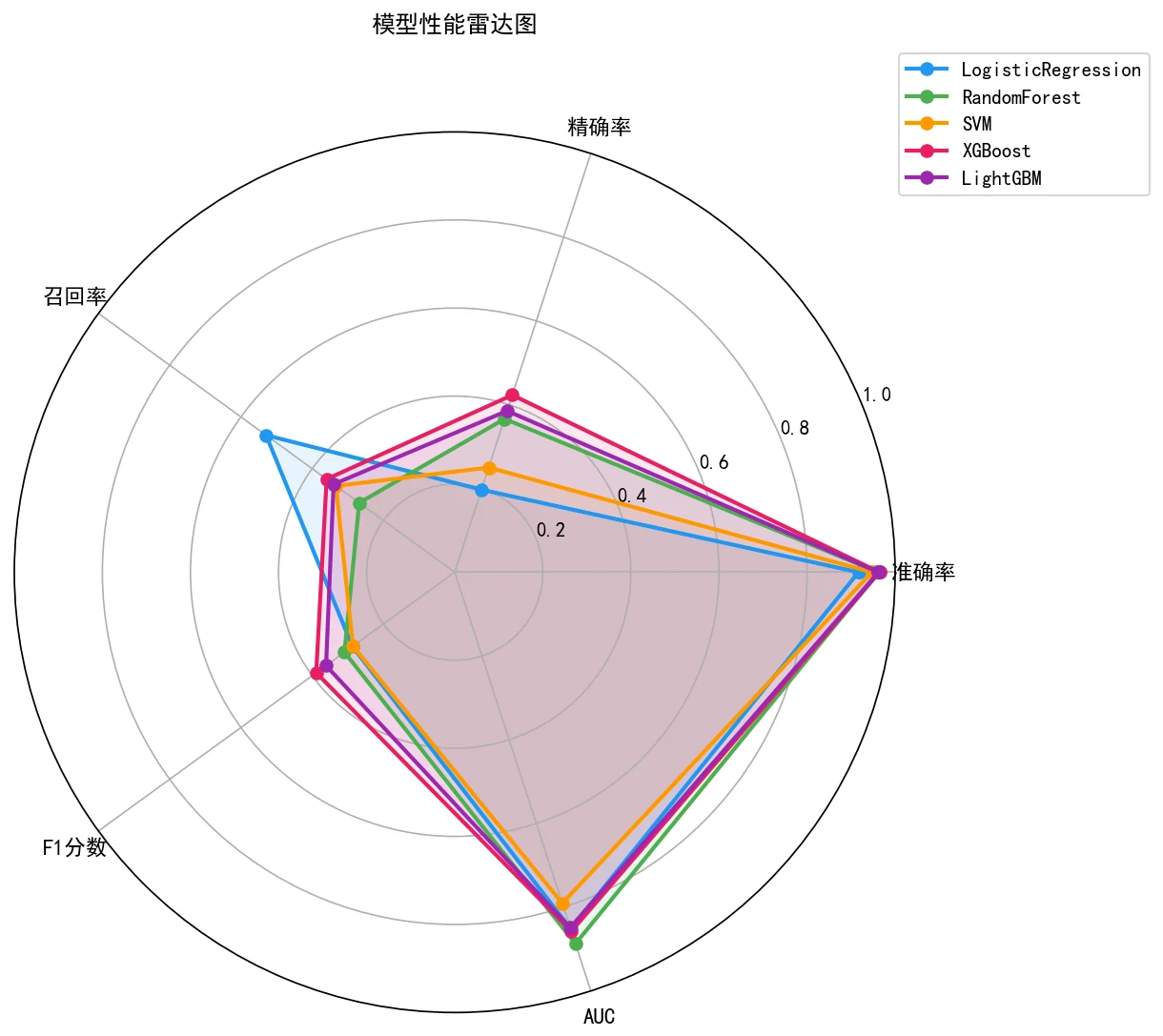
更关键的是,每张图怎么跑出来的、该怎么解读,技术文档里都讲清楚了——你能说明白每张图到底说明了什么,而不只是把图贴上去。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
- 你怎么保证没用到未来数据?标签里的"T+1~T+2"是怎么设计的?
- 困境样本只占 3%,你为什么不直接看准确率?该看什么指标?
- SMOTE 为什么只对训练集做、还只过采样到适度而不是全平衡?
- 熵权法和 TOPSIS 各自解决了选模里的什么问题?
看到会愣一下?正常。配套的项目讲解资料把这个项目——从整体思路到每个流程细节、各种可能被追问的点——连参考答案都给你写好了,从标签设计、不平衡处理到客观选模这些容易被深挖的环节,都帮你梳理成了能直接开口讲的话。另外还有现成的简历描述,照着改就能写进简历;那套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。
配套资料:搞懂一个项目需要的,这里全都有
先看那份技术说明文档——从 CSMAR 数据从哪来、标签怎么避开前视偏差,到特征工程、五模型对比、阈值优化,一直讲到 SHAP 可解释性,图文并茂、层层递进:

代码也给你了——关键部分都带着中文注释,帮你读懂"它到底是怎么实现的":左边是从三大报表算出财务比率、再加衍生指标的特征工程,右边是用熵权法自动定权、TOPSIS 客观排名的那段选模逻辑:
技术文档、项目讲解资料、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添个有金融含量的项目,还是在准备面试,这个题目都接得住。专业上,计算机、人工智能、金融科技、数据科学、统计、经济金融方向都很合适——尤其是想往量化、风控、信用评级方向走的同学,用真实 A 股数据做 ST 困境预警,是把机器学习落到中国资本市场的经典题。把这条从时序无泄露建模、极端不平衡处理到可解释风控的完整流水线真正搞懂、能讲出来,就是一个能写进简历、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「基于机器学习的 A 股上市公司财务困境(ST/*ST)预测」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。