基于深度强化学习的自主导航与路径规划
用深度强化学习让智能体在带障碍的网格世界里自己学会避障导航、找最短路径。Q-Learning 到 DQN 系列再到 PPO 五种算法横向对比,配多场景实验、泛化评估与消融——带注释代码、技术文档、面试问答和整套配图都给齐,做毕设、加简历、备面试都接得住。
如果你想找一个既前沿、又能在面试和答辩里清清楚楚讲明白的 AI 项目,这个「让智能体自己学会走迷宫、避开障碍找到出口」的题目会很合适。
它踩在两个特别热的点上——强化学习和自主导航,正是机器人、无人车、游戏 AI 背后的核心技术。更重要的是,配套都给你备齐了,帮你真正搞懂它、在面试和答辩里讲明白:带中文注释、能一行行读懂的代码,一份从研究动机讲到每个算法推导的技术文档,一份把面试可能追问的点连参考答案都写好的问答文档,还有一整套可以直接拿去做 PPT 的配图。
先说清楚,它到底在做什么
想象一个布满障碍物的网格地图,左上角是起点、右下角是终点,中间随机散着一堆墙。任务是:让一个智能体从起点走到终点,既要避开所有障碍,又要尽量走最短的路。
难点在于,没有人会告诉智能体"这一步该往哪走"。它一开始什么都不会,只能瞎走——撞墙了被扣分,绕远了被扣分,终于摸到终点才得一大笔奖励。它要做的,是在成千上万次试错里,自己悟出一套"在什么情况下该往哪走"的策略。这就是强化学习的精髓:不靠标准答案,靠奖励信号自己学。
这个项目把这件事做成了一个完整的对比研究。它没有只实现一种算法,而是把强化学习发展史上最有代表性的五种方法一字排开——从最朴素的表格法 Q-Learning,到用神经网络的 DQN、Double DQN、Dueling DQN,再到当下最主流的策略梯度方法 PPO,外加一个传统搜索算法 A* 作为"满分参考线"。再设计三种由易到难的场景(固定小地图、固定大地图、每轮都换的随机地图),看看这些算法各自的能力边界在哪。

搞懂它,你能在面试里讲清楚什么
这才是这个项目对你最大的价值。把下面几件事吃透,面试官顺着强化学习往下深挖时,你都能从容接住。
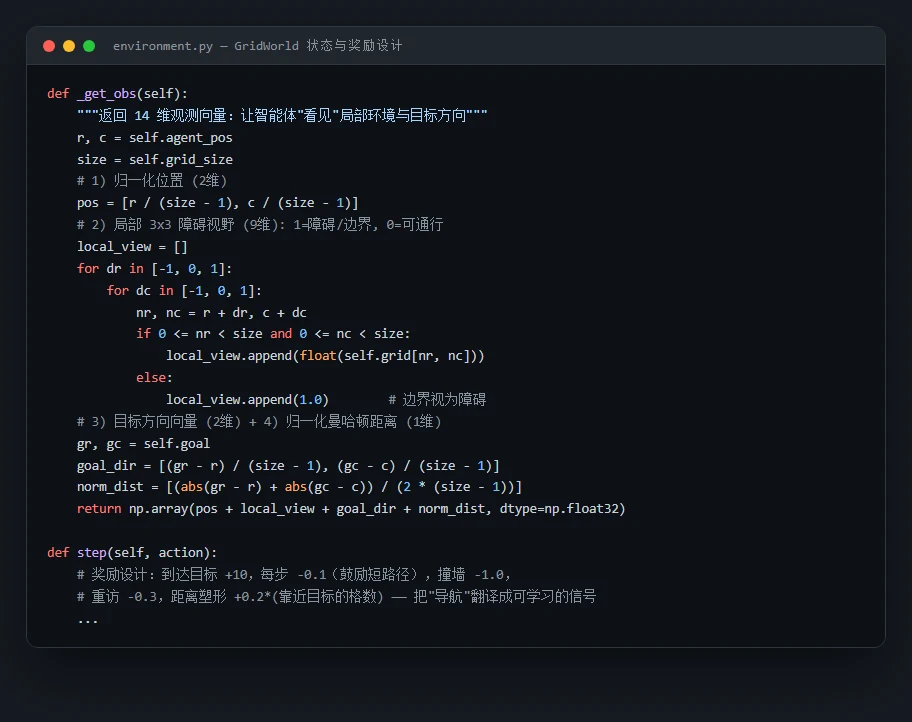
怎么把"导航"这件事翻译成机器能学的语言。 强化学习项目最见功底的地方,从来不是套哪个算法,而是状态、动作、奖励三件套怎么设计。这个项目里,智能体每一步"看到"的是一个 14 维向量——它的位置、周围 3×3 范围有没有障碍、目标在哪个方向、离终点还有多远;动作就是上下左右四选一;奖励则精心设计成"到终点 +10、每走一步 -0.1(逼它走短路)、撞墙 -1、原地打转 -0.3,再加一个靠近目标就给正分的距离塑形"。这套设计能讲明白,面试官立刻知道你是真懂强化学习,而不是只会调库。
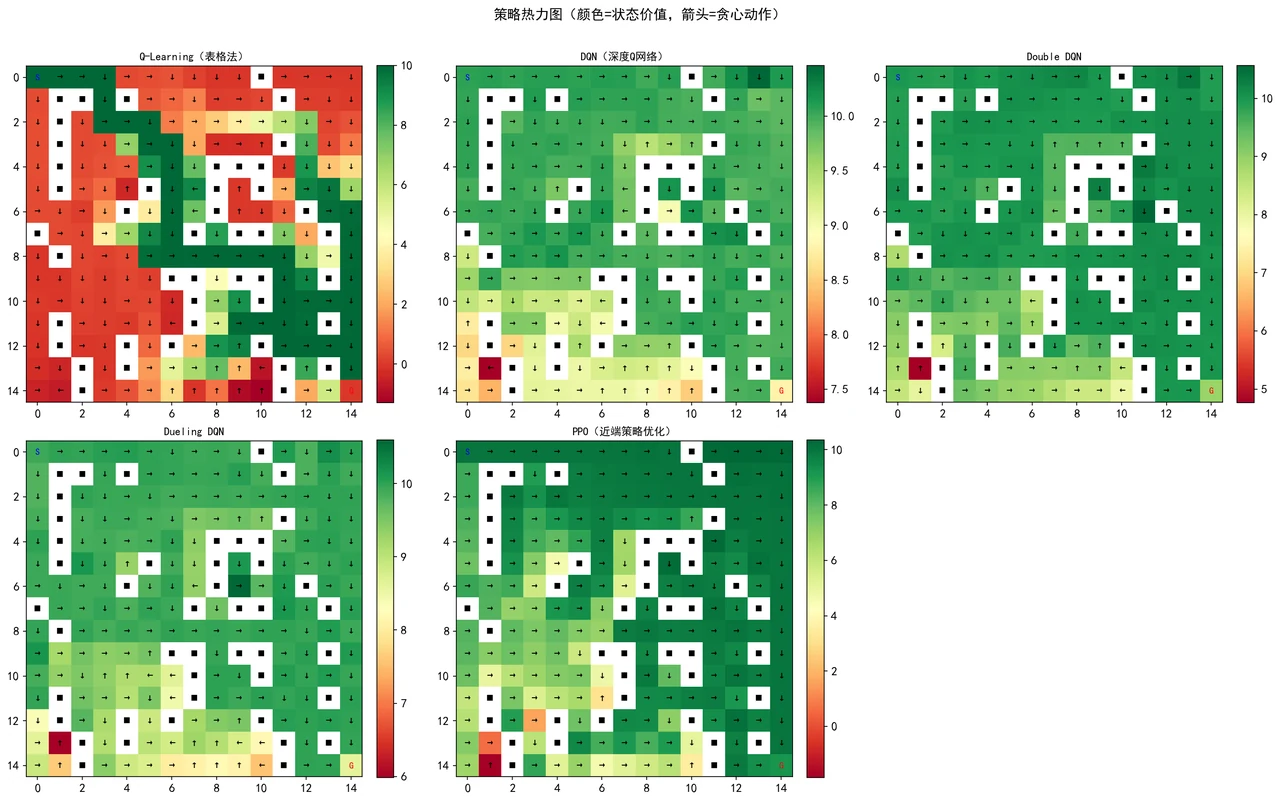
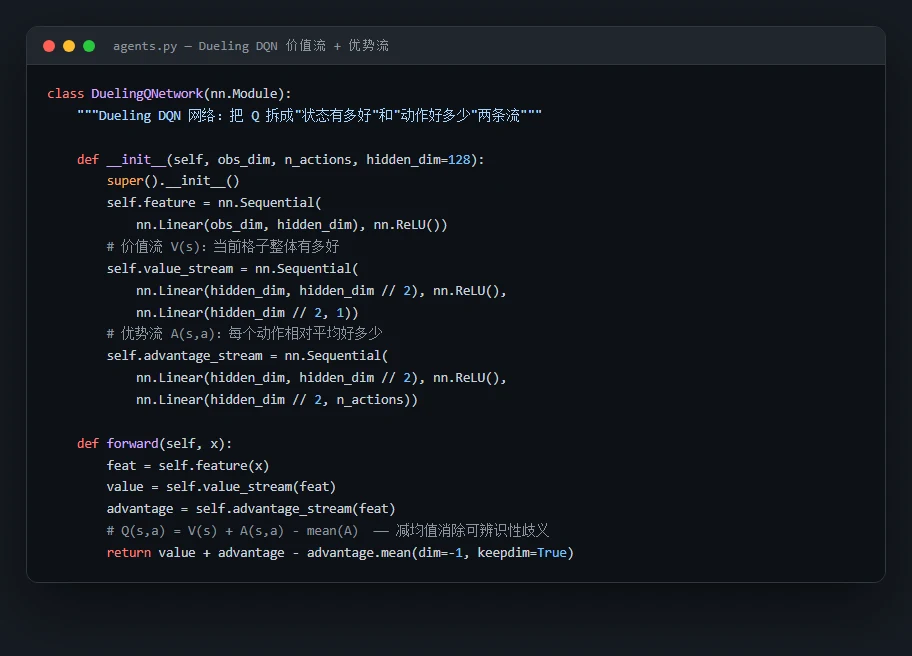
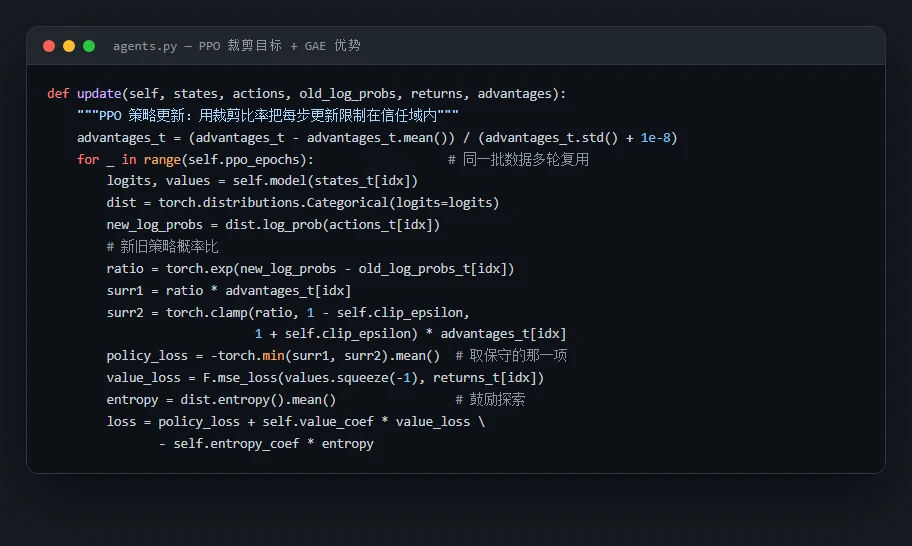
为什么要把五种算法摆在一起比。 这正是这个项目最出彩、面试也最爱问的设计点。五种算法不是随便凑的,而是一条清晰的技术演进线:Q-Learning 用一张表格死记硬背,DQN 用神经网络来"举一反三",Double DQN 修正了 DQN 高估价值的毛病,Dueling DQN 把"这个位置好不好"和"这个动作值不值"拆开来看,PPO 则干脆换了条路——不再估每个动作的价值,而是直接优化策略本身。你能顺着这条线讲清楚每一代解决了上一代什么问题,这本身就是一段很漂亮的面试叙述。
最值钱的结论:为什么 PPO 能泛化,而别的算法不行。 这是整个项目的高潮,也是你在面试里能讲出彩、压住全场的地方。在每轮都换新地图的随机场景里,表格法 Q-Learning 彻底失败(成功率 0%)——因为它记的是"在某个具体格子该怎么走",地图一换,这套记忆全废了;DQN 系列虽然用了神经网络,但也只有 5–8%。唯独 PPO,凭借策略梯度方法,做到了 47% 的训练成功率和 40% 的泛化率,在从没见过的地图上也能导航。你能把"为什么会这样"讲透——它直接关系到强化学习里最核心的"记忆 vs 泛化"之争,是面试官一旦聊到强化学习就一定会感兴趣的点。
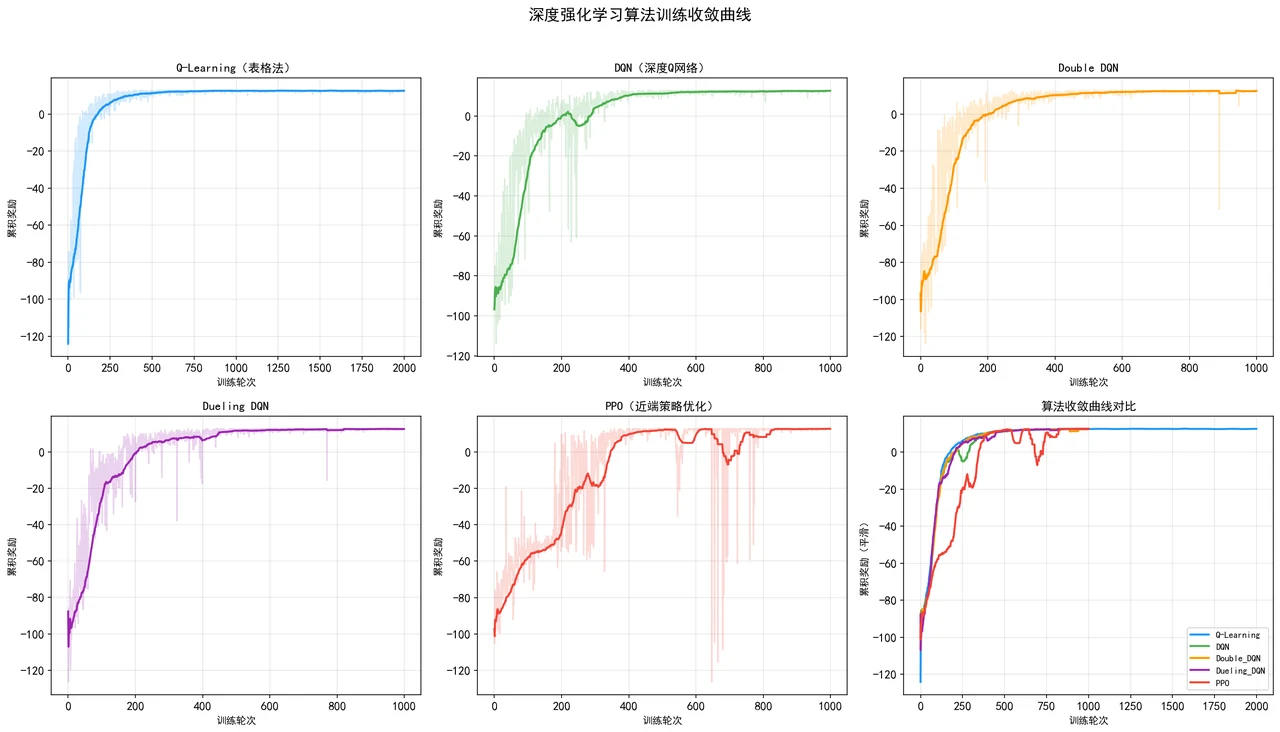
下面这组分析图也都给你做好了,可以直接放进你的答辩或面试 PPT:
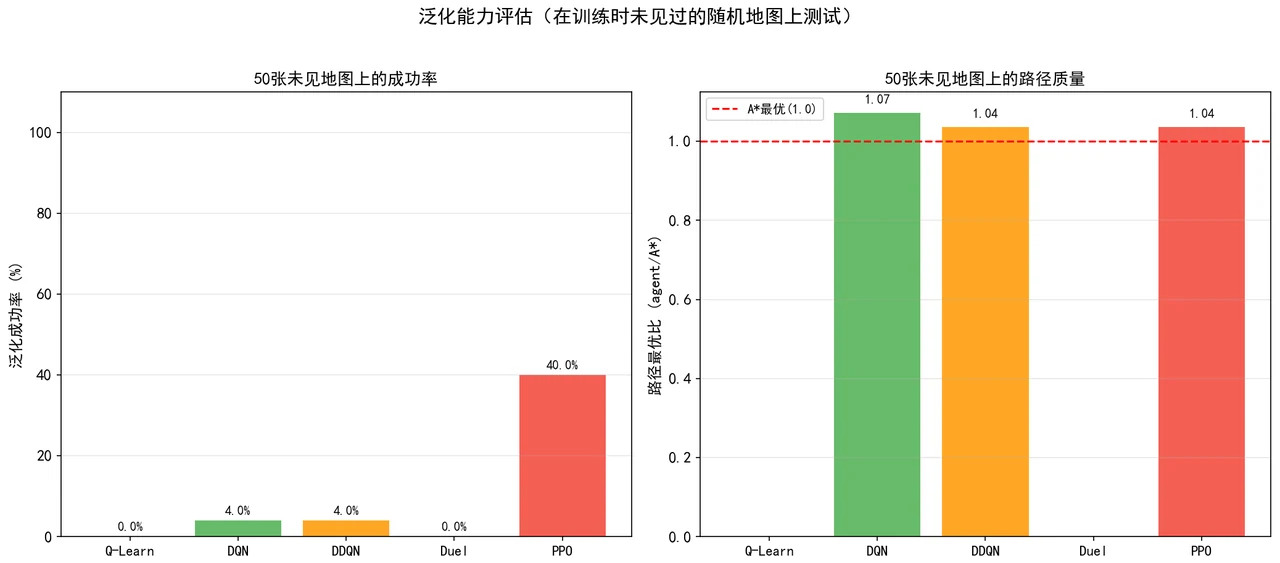

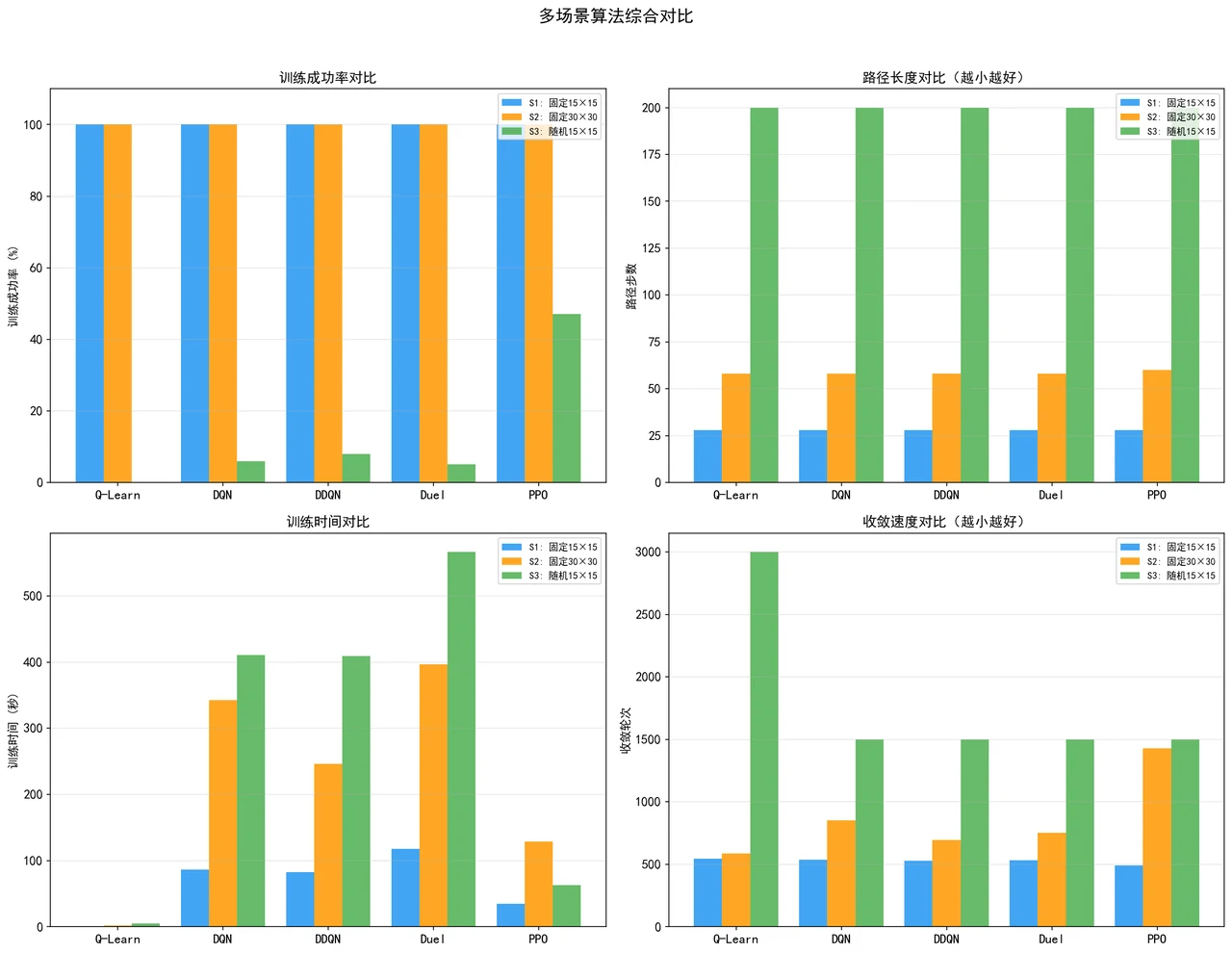
更关键的是,每一张图是怎么跑出来的、该怎么解读,技术文档里都讲清楚了——所以你不是只会往 PPT 上贴图,而是能说明白每张图到底说明了什么问题。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
- 同样是网格寻路,为什么不直接用 A*,非要上强化学习?两者的本质区别在哪?
- Double DQN 和 Dueling DQN 各自改进了 DQN 的什么毛病?为什么这么改有用?
- 随机地图上 Q-Learning 成功率为 0,PPO 却能到 40%,背后的根本原因是什么?
看到这几个是不是会愣一下?正常。配套的面试问答文档把这个项目——从整体思路到每个流程细节、各种可能被追问的点——连参考答案都给你写好了,从奖励函数为什么这么设计,到 PPO 的裁剪目标在防什么,都讲得明明白白。
另外还有现成的简历描述,照着改就能写进简历;那一整套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。你要做的不是背,而是理解,再用自己的话讲一遍。
配套资料:搞懂一个项目需要的,这里全都有
先看那份技术文档——从研究动机一路讲到每个算法的数学推导、每张实验图的解读,图文并茂,帮你把原理从头吃透:



代码也给你了——从环境设计到五种算法实现,关键部分都带着中文注释,帮你读懂"它到底是怎么实现的",面试被追问细节时也答得上来:
技术文档、面试问答、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添一个有分量又够前沿的项目,还是在准备面试,这个题目都接得住。它覆盖了强化学习从经典到主流的整条脉络,深度和广度都拿得出手。专业上,人工智能、计算机、自动化、机器人、数据科学方向都很合适。资料、讲解和面试答案都给你铺好了,把它真正搞懂、能讲出来,就是一个能写进简历、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「基于深度强化学习的自主导航与路径规划」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。