基于现代网络流量的入侵检测与攻击类型识别
用真实的 UNSW-NB15 现代网络流量(17 万+ 连接、9 类攻击)做入侵检测:二分类判正常/攻击(XGBoost AUC 0.994),多分类识别具体攻击类型,并对比有监督与无监督异常检测两种范式。配套带注释代码、技术文档、面试问答和整套配图,适合毕设、简历、面试。
项目亮点
- 若 `data/raw/` 已有 `UNSW_NB15_training-set.csv` 和 `UNSW_NB15_testing-set.csv`,直接复用;
- 否则自动从公开镜像下载官方完整数据(45 列、约 17.5 万条,含 `attack_cat` + `label`),按攻击类别分层切分为训练/测试两份 CSV;
- 若所有下载源不可用,回退到内置的高保真合成生成器——严格按 UNSW-NB15 真实 schema(相同数值/类别特征、9 类攻击与不平衡先验)生成结构一致的演示数据,保证整条流程在任何环境下都能跑通。
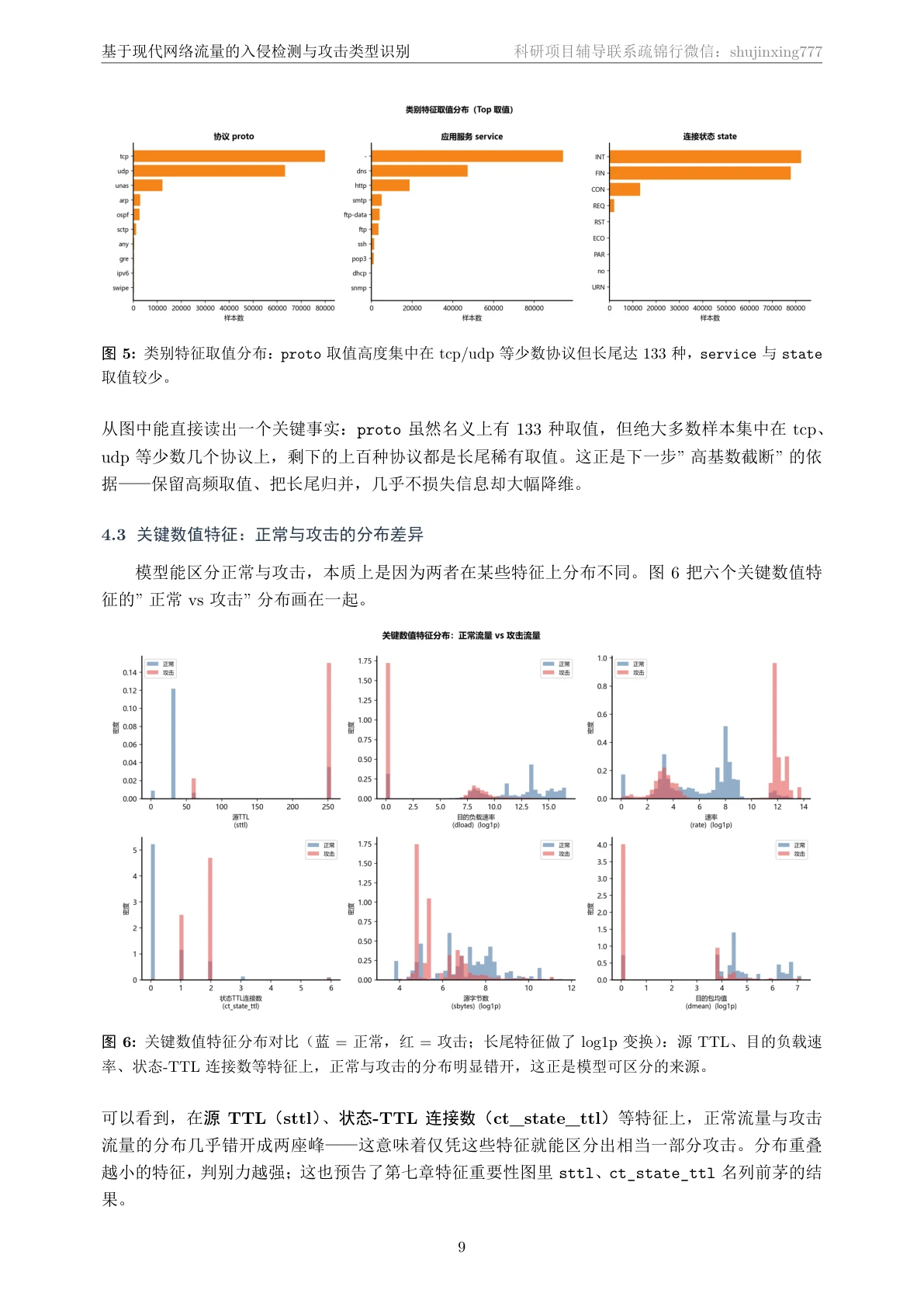
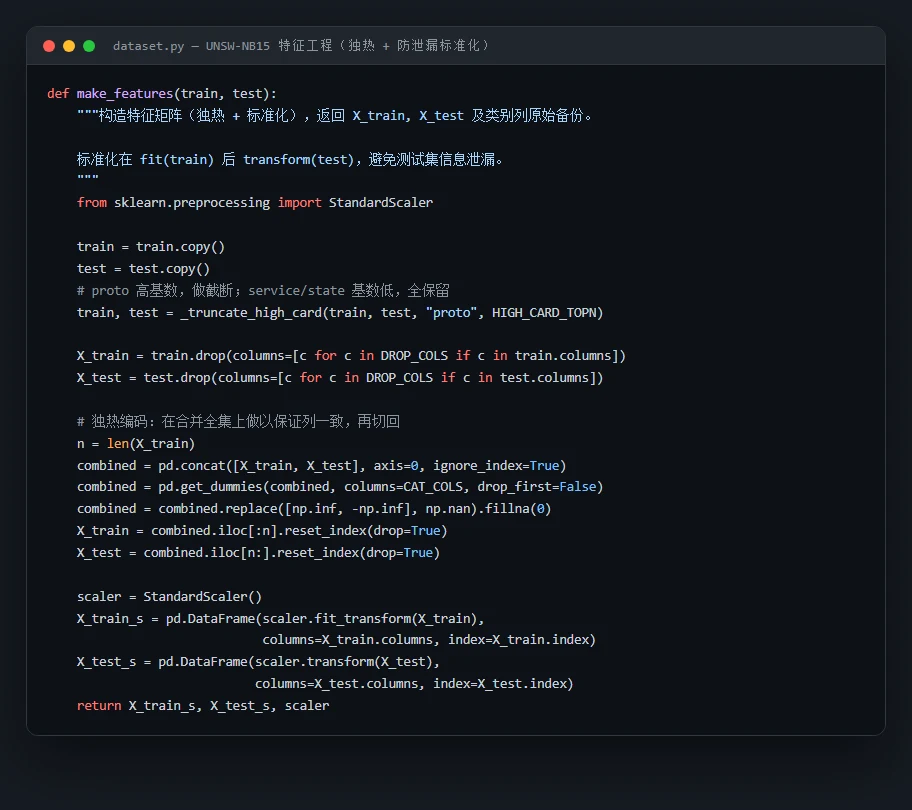
- 预处理:proto 高基数(133 种)频次 Top-20 截断、proto/service/state 独热编码、数值特征 StandardScaler 标准化(仅 fit 训练集防泄漏)。
如果你正在找一个能写进简历、面试时又能讲清楚的 AI 项目,这个「用机器学习给网络流量做入侵检测」的题目会很合适——方向硬核(网络安全 + 机器学习),但一句话就能讲明白:从海量网络连接里,自动揪出哪些是攻击、并判断是哪种攻击。
它用的是真实的 UNSW-NB15 现代流量数据(不是老掉牙的演示数据),配套也都给你备齐了,帮你真正搞懂它、在面试和答辩里讲明白:带中文注释、能读懂的代码,一份从背景到每步实现的技术文档,一份把面试问题连答案都写好的问答文档,还有一整套可以直接拿去做 PPT 的配图。
先说清楚,它到底在做什么
网络安全里有个最基础又最关键的系统叫入侵检测系统(IDS):网络上每时每刻都有海量连接在跑,绝大多数是正常的,但里头夹杂着扫描、漏洞利用、拒绝服务这些攻击。IDS 要做的,就是从这片流量里实时把攻击挑出来、最好还能说清是哪一类,赶在造成损失前发出告警。
这个项目把它拆成两个递进的任务:第一步,二分类——先判一条连接「是不是攻击」(正常 vs 攻击);第二步,多分类——再进一步识别「是哪种攻击」(Normal 加 9 类攻击,共 10 类)。在此之上,项目还做了一组很有意思的对照:把有监督学习(喂模型大量带标签的攻击样本,让它学"攻击长什么样")和无监督异常检测(只让模型见过正常流量,学"正常长什么样"、再把偏离正常的判为可疑)这两种思路放在一起比,看它们各自强在哪、弱在哪。
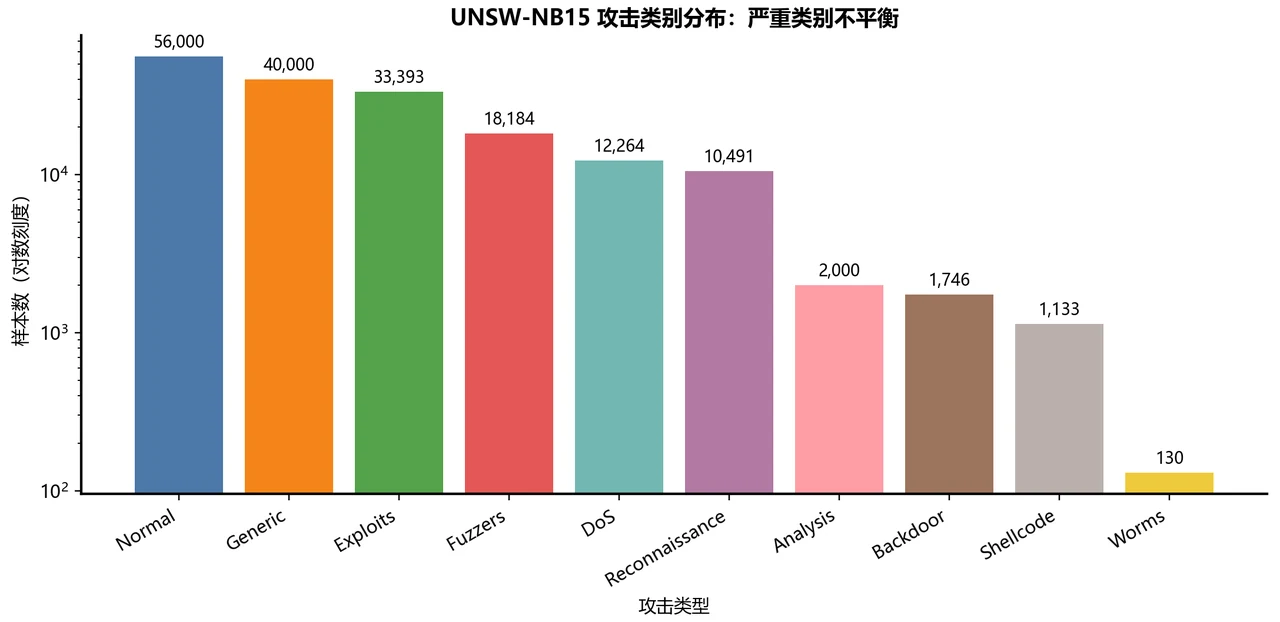
数据用的是 UNSW-NB15——由新南威尔士大学 2015 年发布的现代流量基准,约 17.5 万条真实连接、42 个特征、9 类攻击 + 正常流量。相比很多教程还在用的 1999 年 KDD99,它的攻击类型更新(含 Backdoor、Shellcode、Worms 等现代攻击)、特征更贴近真实网络、类别分布也更真实,是当前入侵检测研究的主流基准。
搞懂它,你能在面试里讲清楚什么
这才是这个项目对你最大的价值。把下面几件事吃透,面试官问到相关问题时,你都能从容答上来。
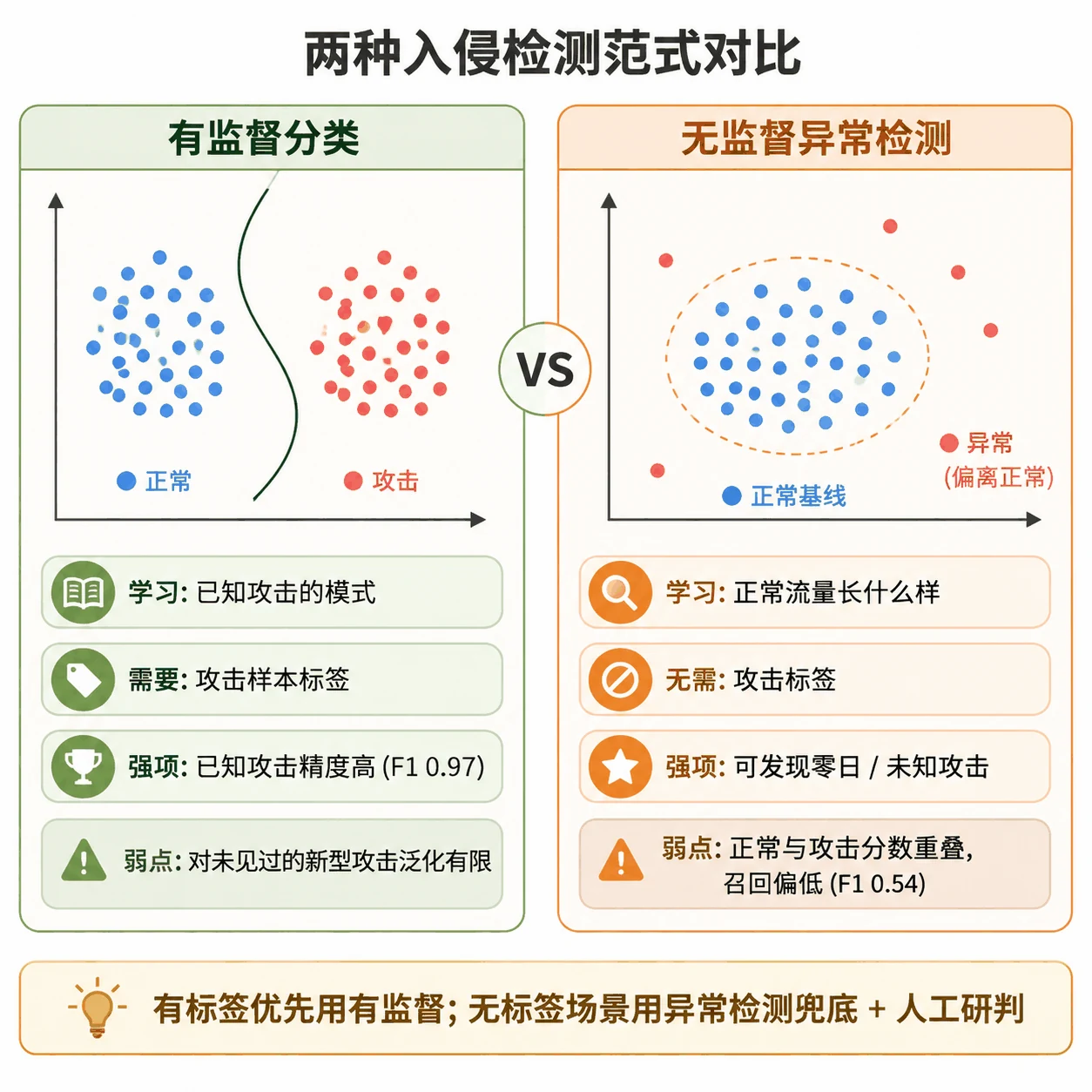
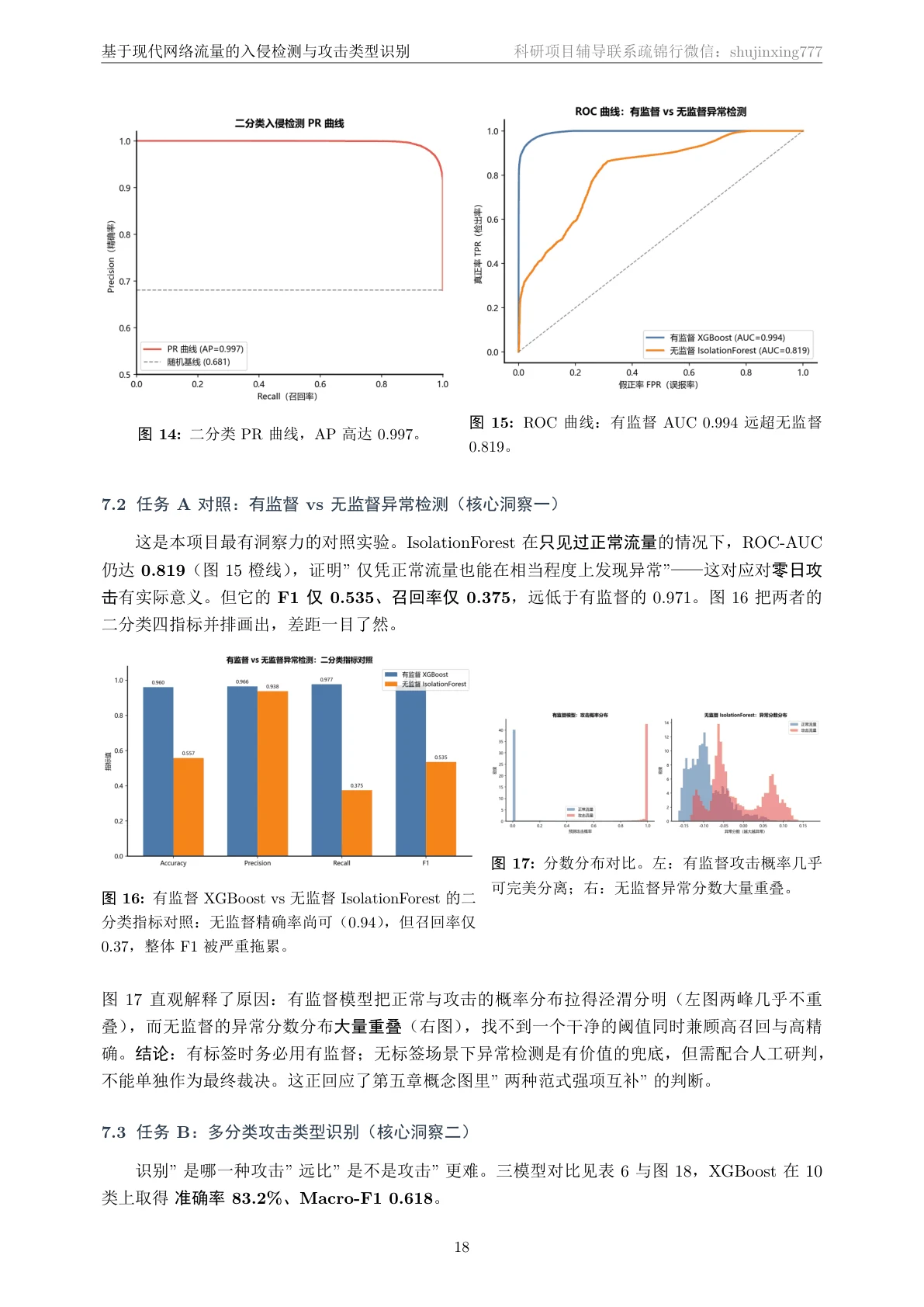
有监督分类 vs 无监督异常检测,这两种范式的取舍。 这是整个项目最出彩、面试也最爱挖的设计点。有监督模型(随机森林 / XGBoost)需要大量带标签的攻击样本,学得准但只认识"见过的攻击";无监督的 IsolationForest 只用正常流量训练,完全不需要攻击标签,靠"这条连接和正常的不一样"来报警,因此天然能应对零日攻击(前所未见的新型攻击),代价是精度和召回都更低。项目用一张概念图把两者讲得明明白白——什么时候该用哪个,你能答得有理有据。
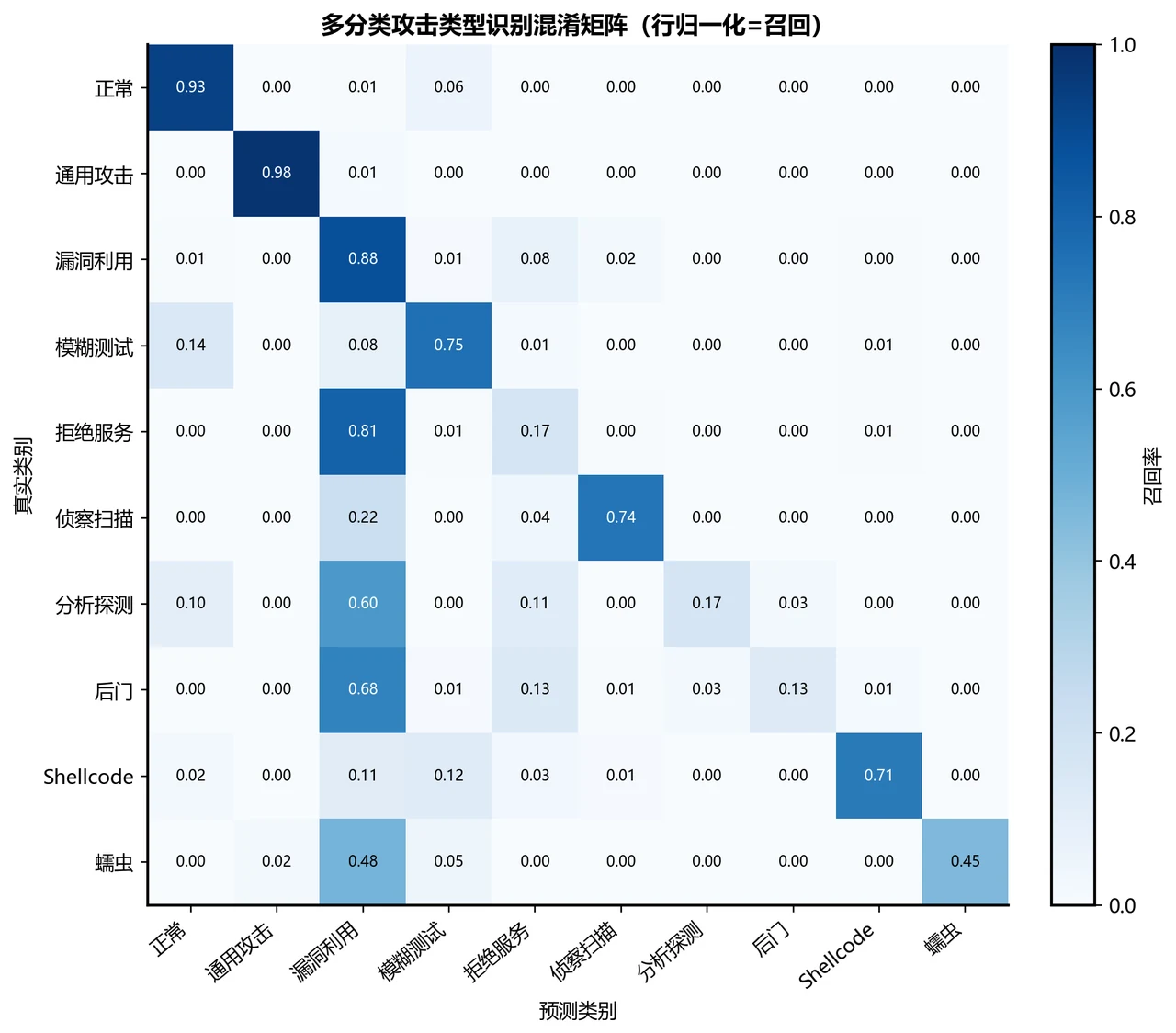
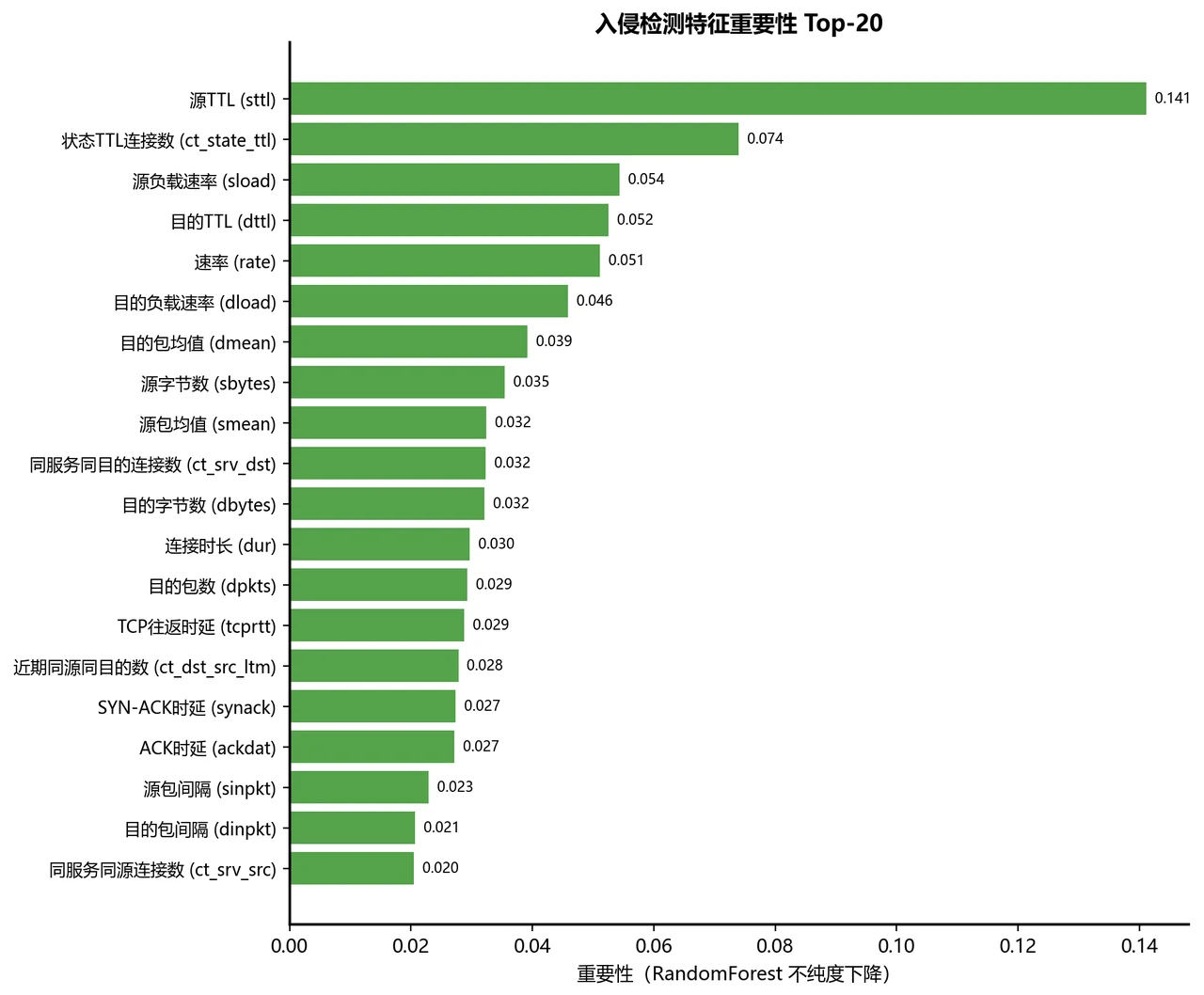
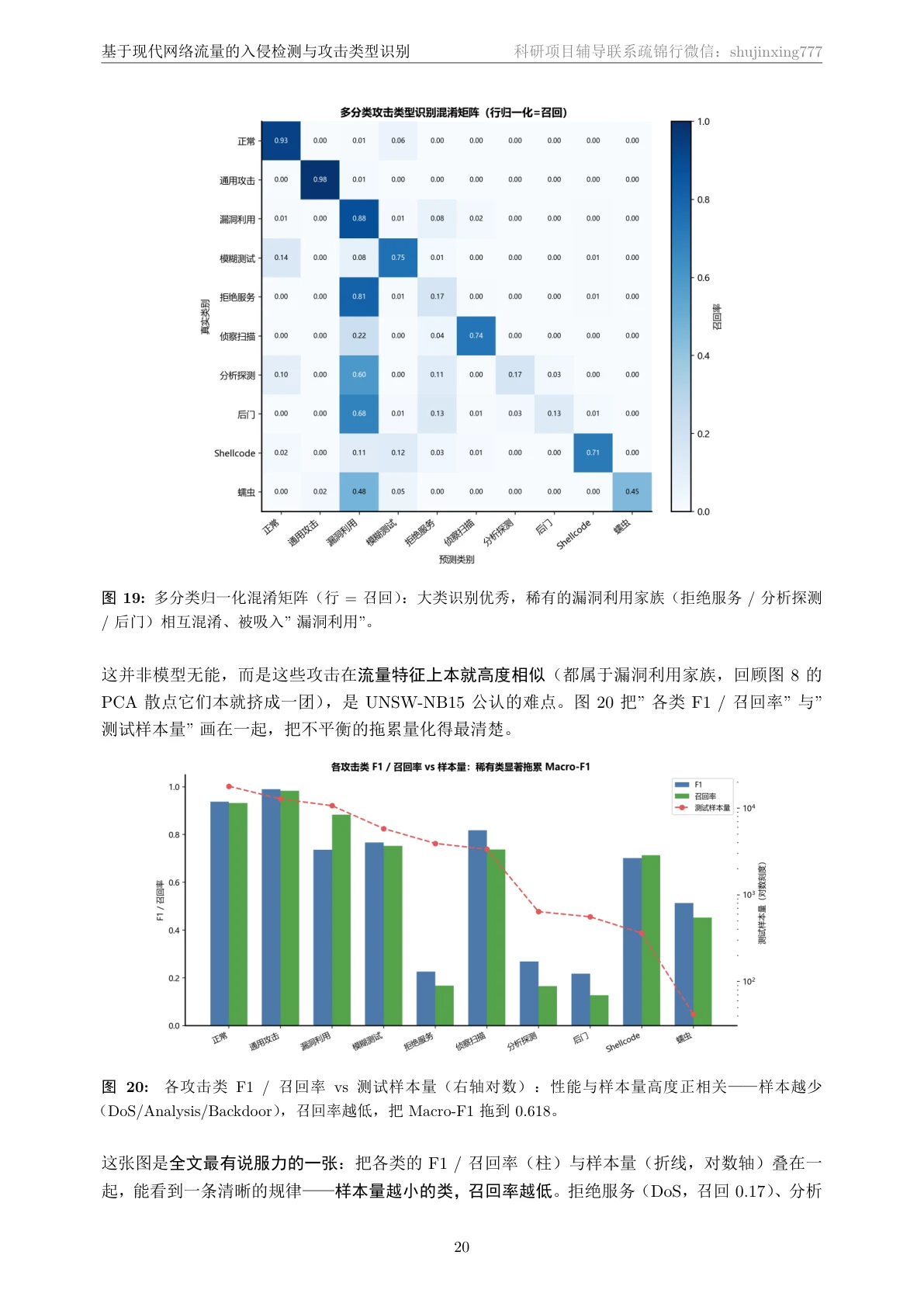
二分类近乎完美,但我更想讲清楚多分类背后的"类别不平衡"。 二分类上 XGBoost 拿到了 Accuracy 0.960、AUC 0.994,几乎完美——这部分讲起来很漂亮。但项目真正有深度的地方在多分类:总体准确率 0.83 看着不低,可只要换一个对稀有类敏感的指标 Macro-F1,就掉到 0.62。这个落差不是模型不行,而是数据本身的"类别不平衡"在作怪——稀有攻击类(DoS、Analysis、Backdoor)样本太少、又和 Exploits 这类大家族在流量特征上高度相似,被淹没了。能识别、并讲清楚这个真问题,正是这个项目最能体现你专业深度的地方:它告诉面试官,你懂"准确率不等于模型好,选对评估指标比堆模型更重要"。
误报率和漏报率怎么权衡。 安全场景里,漏报(把攻击放过)通常代价更高,但误报(把正常判成攻击)一多就会造成"告警疲劳",让分析师麻木。你能讲清楚怎么通过 PR / ROC 曲线、按业务的容忍度去选阈值——要高检出就降阈值,要少打扰就升阈值。这种"在工程权衡里做决策"的思维,比单纯报一个指标更能打动面试官。
下面这组分析图也都给你做好了,可以直接放进你的答辩或面试 PPT:
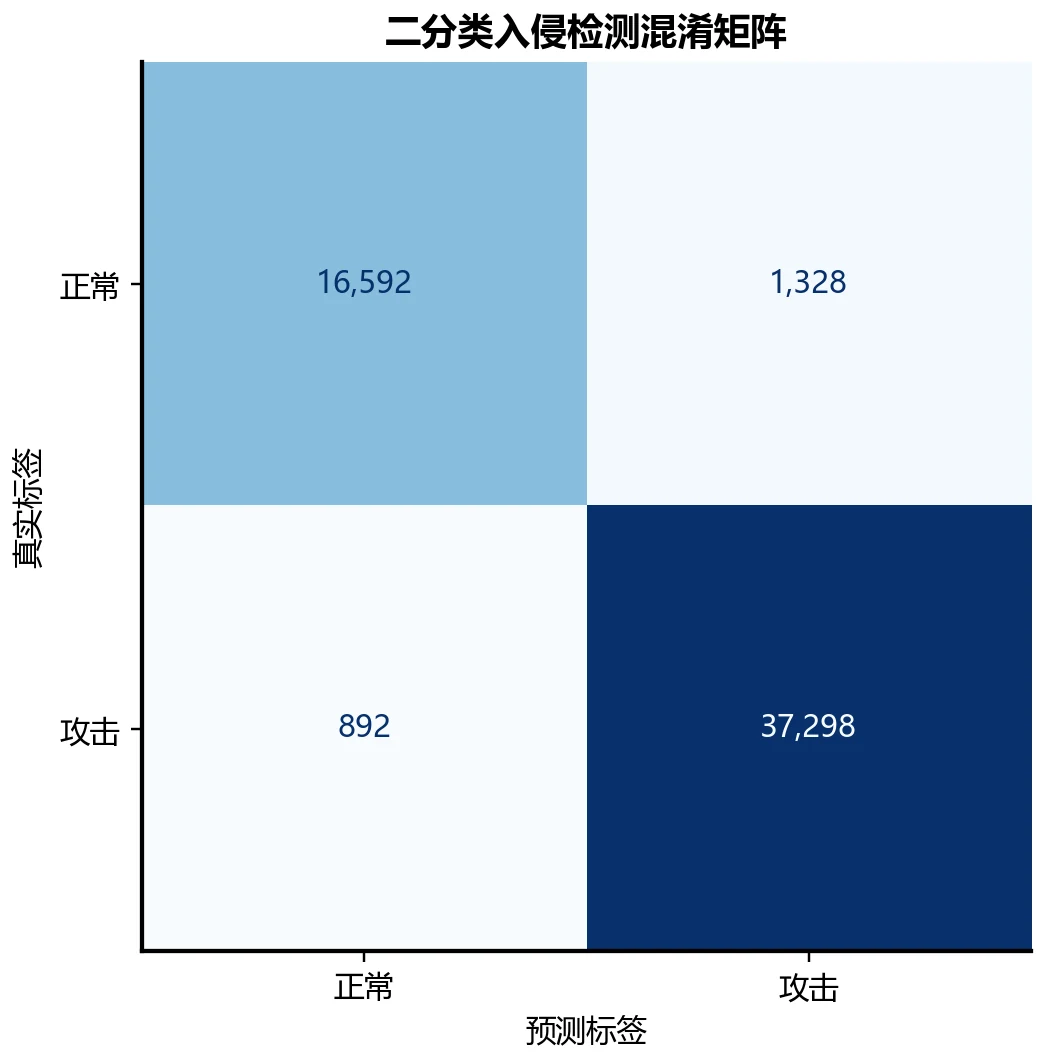
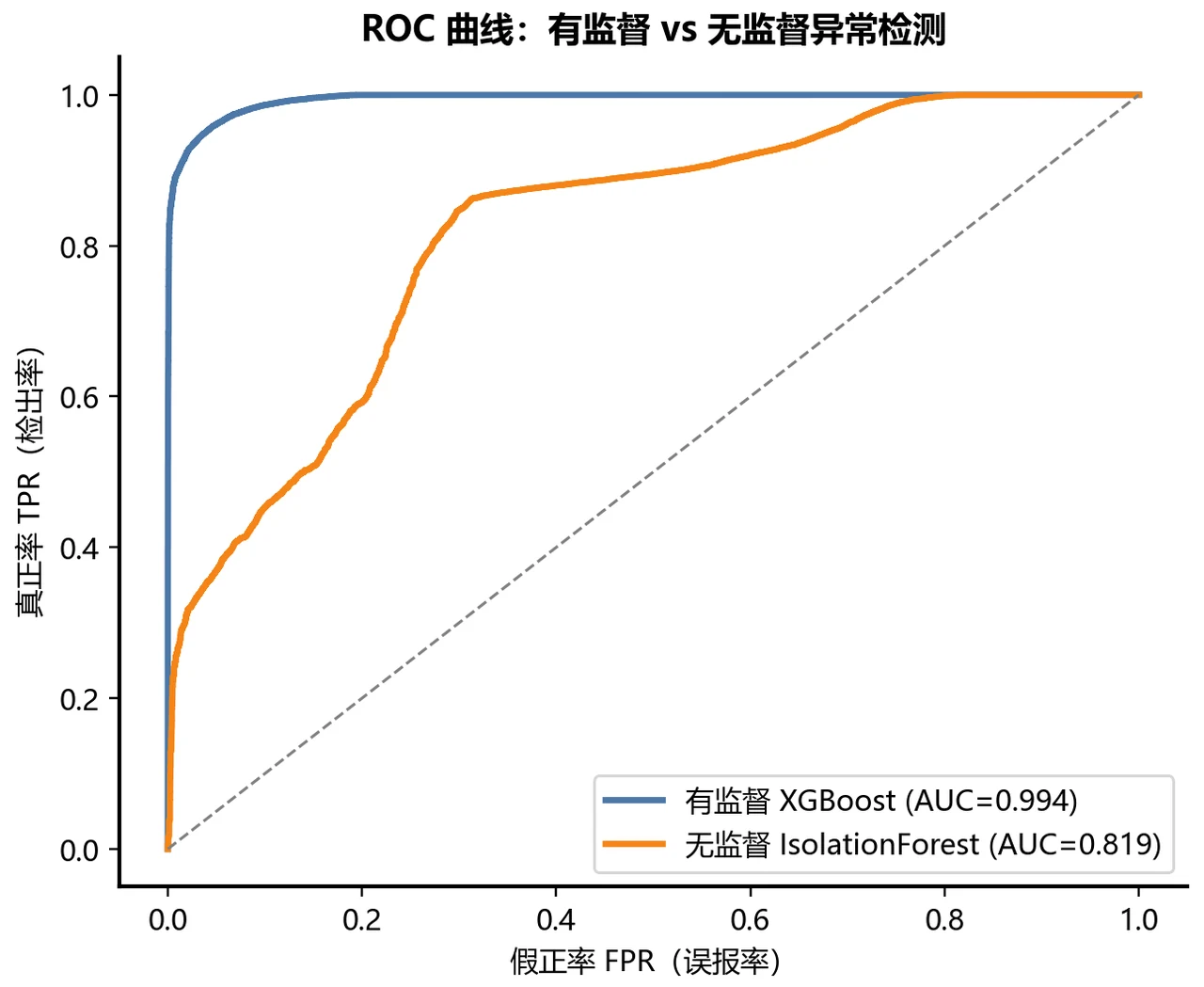
更关键的是,每一张图是怎么跑出来的、该怎么解读,技术文档里都讲清楚了——所以你不是只会往 PPT 上贴图,而是能说明白每张图到底说明了什么。比如那张 ROC 曲线,你能讲出"有监督 XGBoost 的 AUC 0.994 几乎贴着左上角,而只见过正常流量的 IsolationForest 仍有 0.819",进而说清两种范式的差距与价值。
面试官会问的,都帮你备好了
随便感受几个这个项目真实会被追问的问题:
- 数据严重不平衡时,为什么要看 Macro-F1,而不能只看 Accuracy?
- 有监督分类和无监督异常检测,分别适合什么场景?为什么无监督召回偏低还要用它?
- 数值特征标准化为什么只能在训练集上 fit、再去 transform 测试集?
看到这几个是不是会愣一下?正常。配套的面试问答文档把这个项目——从整体思路到每个流程细节、各种面试可能追问的点——连参考答案都给你写好了,包括"为什么用 UNSW-NB15 而不是 KDD99""IsolationForest 的原理""DoS / Analysis / Backdoor 为什么容易混"这些容易被问倒的硬核点。
另外还有现成的简历描述,照着改就能写进简历;那一整套配图也能直接套进 PPT 模板,快速出一份面试 / 答辩 PPT。你要做的不是背,而是理解,再用自己的话讲一遍。
配套资料:搞懂一个项目需要的,这里全都有
先看那份技术文档——从研究背景、数据来源一直讲到每一步实现与结果分析,图文并茂,帮你把原理从头吃透:
代码也给你了——关键部分都带着中文注释,帮你读懂"它到底是怎么实现的",面试被追问细节时也答得上来:
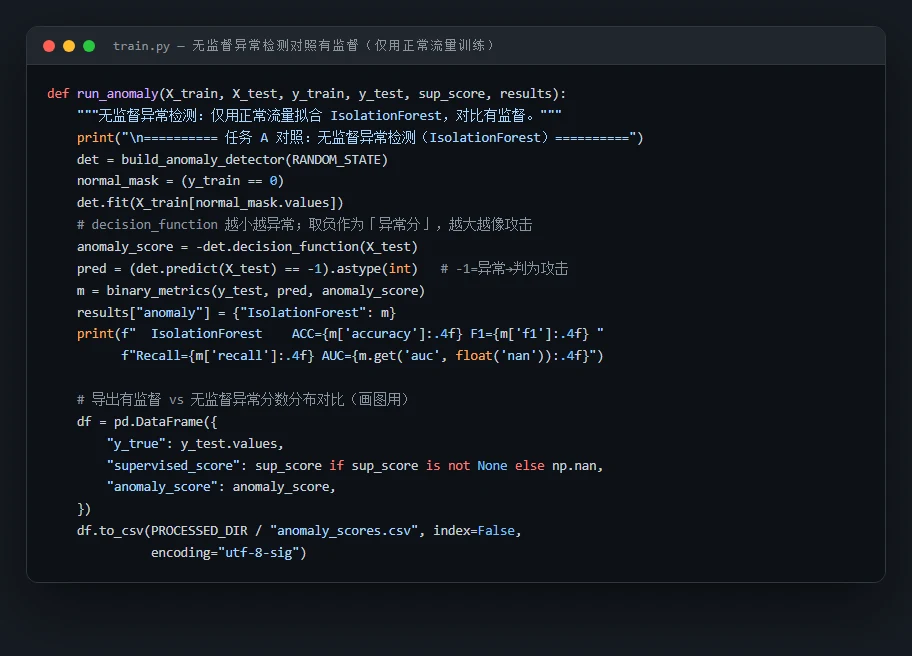
技术文档、面试问答、源码注释、整套配图——搞懂一个项目、并在面试里讲清楚它,需要的全都备齐了。
适合谁
不管你是赶毕设、想给简历添个有分量的项目,还是在准备面试,这个题目都接得住。专业上,网络安全、信息安全、信息工程、计算机、数据科学和人工智能方向都很合适。它把真实数据处理、有监督与无监督建模、类别不平衡这个机器学习核心难题、再到一套完整的检测-识别-告警闭环串成了一条线,资料、讲解和面试答案也都给你铺好了——把它真正搞懂、能讲出来,就是一个能写进简历、撑得起面试的项目。
想把这样的项目做成你简历上的亮点?
这是一套配齐了代码、文档、面试问答和配图的 AI+X 项目,可写进简历、在面试里讲清楚。 想做同类项目、或获取「基于现代网络流量的入侵检测与攻击类型识别」的完整资料(代码 / 数据处理流程 / 论文文档 / 配图), 请联系为你介绍本页面的老师咨询,按你的情况定一个合适的项目。